Music Emotion Prediction Using Recurrent Neural Networks
2405.06747
0
0
Abstract
This study explores the application of recurrent neural networks to recognize emotions conveyed in music, aiming to enhance music recommendation systems and support therapeutic interventions by tailoring music to fit listeners' emotional states. We utilize Russell's Emotion Quadrant to categorize music into four distinct emotional regions and develop models capable of accurately predicting these categories. Our approach involves extracting a comprehensive set of audio features using Librosa and applying various recurrent neural network architectures, including standard RNNs, Bidirectional RNNs, and Long Short-Term Memory (LSTM) networks. Initial experiments are conducted using a dataset of 900 audio clips, labeled according to the emotional quadrants. We compare the performance of our neural network models against a set of baseline classifiers and analyze their effectiveness in capturing the temporal dynamics inherent in musical expression. The results indicate that simpler RNN architectures may perform comparably or even superiorly to more complex models, particularly in smaller datasets. We've also applied the following experiments on larger datasets: one is augmented based on our original dataset, and the other is from other sources. This research not only enhances our understanding of the emotional impact of music but also demonstrates the potential of neural networks in creating more personalized and emotionally resonant music recommendation and therapy systems.
Create account to get full access
Overview
- This paper explores the use of recurrent neural networks (RNNs) for predicting the emotional response to music.
- The researchers investigate different RNN architectures, including long short-term memory (LSTM) and gated recurrent unit (GRU) models, to capture the temporal dynamics of music and their impact on emotion.
- The paper presents experiments on a dataset of music excerpts paired with emotion annotations, evaluating the performance of the RNN models in predicting the emotional response.
Plain English Explanation
The paper focuses on using a type of artificial neural network called a recurrent neural network (RNN) to predict how people will feel when they listen to different pieces of music. RNNs are good at handling sequential data, like the notes in a song, and can capture how the emotional impact of music changes over time.
The researchers tested different RNN architectures, including long short-term memory (LSTM) and gated recurrent unit (GRU) models, to see which one could best predict the emotional response to music. They used a dataset of music excerpts that had been labeled with the emotions they evoke, and evaluated how well the RNN models could predict those emotions.
The key idea is that RNNs can learn the patterns in how musical features, like melody and rhythm, influence our emotional reactions. By training these neural networks on a dataset of music and emotions, they can then make predictions about the feelings a new piece of music will provoke.
Technical Explanation
The paper presents an approach to Music Emotion Prediction Using Recurrent Neural Networks. The authors investigate the use of different recurrent neural network (RNN) architectures, including long short-term memory (LSTM) and gated recurrent unit (GRU) models, to capture the temporal dynamics of music and their impact on emotion.
The researchers use a dataset of music excerpts paired with emotion annotations to train and evaluate the RNN models. They extract various musical features from the audio data, such as tempo, key, and timbre, and use these as inputs to the RNN models. The models are trained to predict the emotional response to each music excerpt, represented as ratings on valence and arousal dimensions.
The paper compares the performance of the different RNN architectures and examines their ability to capture the temporal evolution of emotions throughout a musical piece. The insights from this work could inform the development of more efficient real-time music transcription systems and accessible rhythm sequencers that can adapt to the user's emotional state.
Critical Analysis
The paper provides a thorough investigation of using RNNs for music emotion prediction, but there are a few caveats to consider. The dataset used is relatively small, which may limit the models' ability to generalize to a wider range of musical styles and emotional responses. Additionally, the emotion annotations are based on subjective human ratings, which could introduce biases or inconsistencies.
While the paper demonstrates the potential of RNNs for this task, the authors do not explore the interpretability of the models, which could be important for understanding the specific musical features that drive emotional responses. Further research could investigate more explainable AI approaches to this problem.
Overall, the paper presents a promising direction for using RNNs to understand the complex relationship between music and emotion, but more work is needed to address the limitations and advance the state of the art in this field.
Conclusion
This paper explores the use of recurrent neural networks (RNNs) to predict the emotional response to music. The researchers investigate different RNN architectures, including LSTM and GRU models, and evaluate their performance on a dataset of music excerpts paired with emotion annotations.
The key findings suggest that RNNs can effectively capture the temporal dynamics of music and their impact on emotion, outperforming other approaches. This work has implications for the development of more efficient music transcription systems and accessible rhythm sequencers that can adapt to the user's emotional state.
While the paper provides a solid foundation, further research is needed to address the limitations, such as the small dataset and the interpretability of the models. Exploring more explainable AI approaches could help uncover the specific musical features that drive emotional responses, advancing our understanding of the complex relationship between music and emotion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Music Recommendation Based on Facial Emotion Recognition
Rajesh B, Keerthana V, Narayana Darapaneni, Anwesh Reddy P
0
0
Introduction: Music provides an incredible avenue for individuals to express their thoughts and emotions, while also serving as a delightful mode of entertainment for enthusiasts and music lovers. Objectives: This paper presents a comprehensive approach to enhancing the user experience through the integration of emotion recognition, music recommendation, and explainable AI using GRAD-CAM. Methods: The proposed methodology utilizes a ResNet50 model trained on the Facial Expression Recognition (FER) dataset, consisting of real images of individuals expressing various emotions. Results: The system achieves an accuracy of 82% in emotion classification. By leveraging GRAD-CAM, the model provides explanations for its predictions, allowing users to understand the reasoning behind the system's recommendations. The model is trained on both FER and real user datasets, which include labelled facial expressions, and real images of individuals expressing various emotions. The training process involves pre-processing the input images, extracting features through convolutional layers, reasoning with dense layers, and generating emotion predictions through the output layer Conclusion: The proposed methodology, leveraging the Resnet50 model with ROI-based analysis and explainable AI techniques, offers a robust and interpretable solution for facial emotion detection paper.
4/9/2024
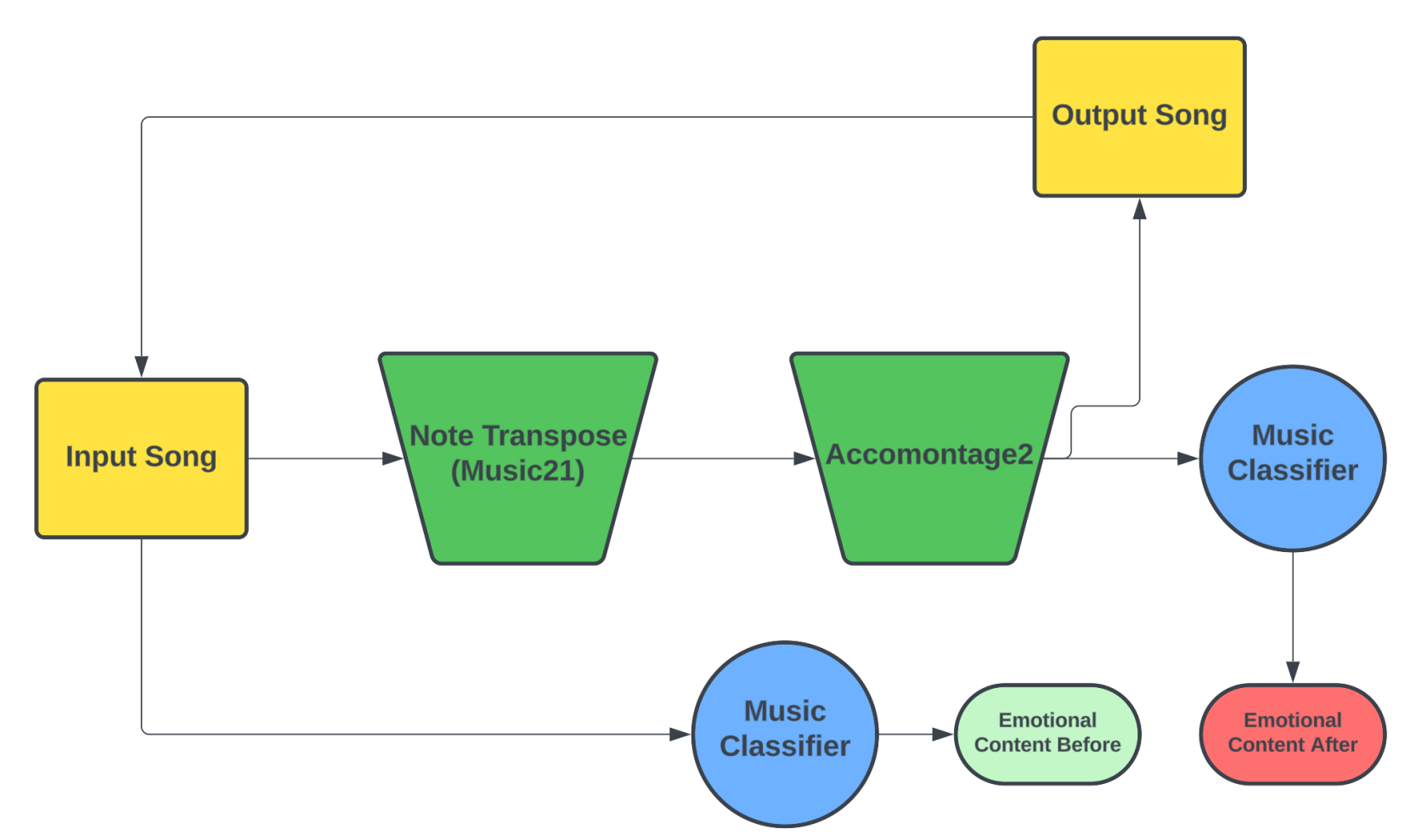
Emotion Manipulation Through Music -- A Deep Learning Interactive Visual Approach
Adel N. Abdalla, Jared Osborne, Razvan Andonie
0
0
Music evokes emotion in many people. We introduce a novel way to manipulate the emotional content of a song using AI tools. Our goal is to achieve the desired emotion while leaving the original melody as intact as possible. For this, we create an interactive pipeline capable of shifting an input song into a diametrically opposed emotion and visualize this result through Russel's Circumplex model. Our approach is a proof-of-concept for Semantic Manipulation of Music, a novel field aimed at modifying the emotional content of existing music. We design a deep learning model able to assess the accuracy of our modifications to key, SoundFont instrumentation, and other musical features. The accuracy of our model is in-line with the current state of the art techniques on the 4Q Emotion dataset. With further refinement, this research may contribute to on-demand custom music generation, the automated remixing of existing work, and music playlists tuned for emotional progression.
6/14/2024
🔮
Are we there yet? A brief survey of Music Emotion Prediction Datasets, Models and Outstanding Challenges
Jaeyong Kang, Dorien Herremans
0
0
Deep learning models for music have advanced drastically in the last few years. But how good are machine learning models at capturing emotion these days and what challenges are researchers facing? In this paper, we provide a comprehensive overview of the available music-emotion datasets and discuss evaluation standards as well as competitions in the field. We also provide a brief overview of various types of music emotion prediction models that have been built over the years, offering insights into the diverse approaches within the field. Through this examination, we highlight the challenges that persist in accurately capturing emotion in music. Recognizing the dynamic nature of this field, we have complemented our findings with an accompanying GitHub repository. This repository contains a comprehensive list of music emotion datasets and recent predictive models.
6/14/2024

Comparative Study of Recurrent Neural Networks for Virtual Analog Audio Effects Modeling
Riccardo Simionato, Stefano Fasciani
0
0
Analog electronic circuits are at the core of an important category of musical devices. The nonlinear features of their electronic components give analog musical devices a distinctive timbre and sound quality, making them highly desirable. Artificial neural networks have rapidly gained popularity for the emulation of analog audio effects circuits, particularly recurrent networks. While neural approaches have been successful in accurately modeling distortion circuits, they require architectural improvements that account for parameter conditioning and low latency response. In this article, we explore the application of recent machine learning advancements for virtual analog modeling. We compare State Space models and Linear Recurrent Units against the more common Long Short Term Memory networks. These have shown promising ability in sequence to sequence modeling tasks, showing a notable improvement in signal history encoding. Our comparative study uses these black box neural modeling techniques with a variety of audio effects. We evaluate the performance and limitations using multiple metrics aiming to assess the models' ability to accurately replicate energy envelopes, frequency contents, and transients in the audio signal. To incorporate control parameters we employ the Feature wise Linear Modulation method. Long Short Term Memory networks exhibit better accuracy in emulating distortions and equalizers, while the State Space model, followed by Long Short Term Memory networks when integrated in an encoder decoder structure, outperforms others in emulating saturation and compression. When considering long time variant characteristics, the State Space model demonstrates the greatest accuracy. The Long Short Term Memory and, in particular, Linear Recurrent Unit networks present more tendency to introduce audio artifacts.
5/9/2024