Mutually-Aware Feature Learning for Few-Shot Object Counting

0

Sign in to get full access
Overview
- The paper presents a novel approach called Mutually-Aware Feature Learning (MAFL) for few-shot object counting.
- Few-shot learning is the ability to learn from a small number of examples, which is important for real-world applications.
- The key idea is to leverage mutual information between feature representations of the support set and the query set to improve performance on few-shot object counting tasks.
Plain English Explanation
Counting the number of objects in an image is a common task in computer vision, but it can be challenging when you only have a few examples to learn from. Mutually-Aware Feature Learning (MAFL) is a new technique that aims to solve this problem.
The core idea is to find the hidden connections between the features extracted from the few example images (the "support set") and the features extracted from the image you're trying to count the objects in (the "query set"). By understanding how these features relate to each other, the model can learn more effectively from the limited data and make better predictions about the object count.
This "mutual awareness" between the support and query sets is the key innovation that sets MAFL apart from previous approaches. Rather than just trying to memorize the examples, MAFL actively explores the relationship between them to gain deeper insights that improve its ability to generalize to new images.
The end result is a model that can accurately count objects in images, even when it has only seen a handful of examples during training. This makes MAFL particularly useful for real-world applications where data is scarce, such as medical imaging or wildlife monitoring.
Technical Explanation
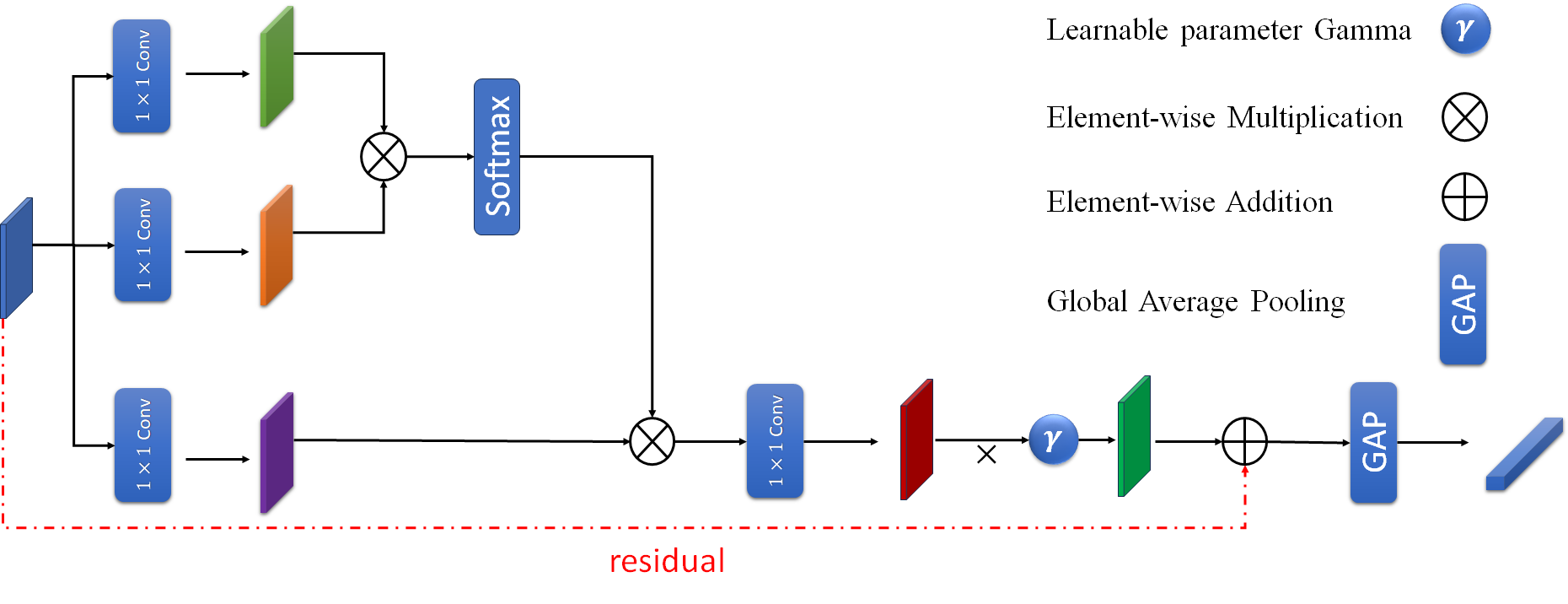
The Mutually-Aware Feature Learning (MAFL) approach works by jointly learning feature representations for both the support set and the query set in a few-shot object counting task.
The key innovation is the Mutual Information Maximization (MIM) module, which encourages the model to extract features that capture the hidden relationships between the support and query sets. By maximizing the mutual information between these feature representations, the model can learn more discriminative and transferable features that improve its ability to generalize to new examples.
In addition to the MIM module, the MAFL architecture includes a Counting Head that predicts the object count based on the learned feature representations. The model is trained end-to-end using a combination of counting loss and the mutual information objective.
Experiments on benchmark datasets show that MAFL outperforms previous state-of-the-art few-shot object counting methods, demonstrating the effectiveness of the mutual awareness approach.
Critical Analysis
The MAFL paper provides a compelling solution to the challenge of few-shot object counting, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The experiments in the paper are conducted on a limited set of datasets, which may not capture the full range of real-world object counting scenarios. It would be valuable to evaluate the method on a more diverse set of datasets to assess its robustness.
-
Computational Complexity: The inclusion of the Mutual Information Maximization module may increase the computational overhead of the model, which could be a concern for real-time applications. Exploring ways to streamline the architecture or approximate the mutual information calculation could help address this issue.
-
Interpretability: While the mutual awareness approach is conceptually interesting, the paper does not provide much insight into how the learned feature representations capture the relationships between the support and query sets. Incorporating more interpretable components could help users understand the model's decision-making process.
-
Generalization to Other Tasks: The MAFL method is specifically designed for few-shot object counting, but the underlying principles of mutual awareness could potentially be applied to other few-shot learning tasks. Investigating the generalizability of the approach could lead to broader impacts.
Overall, the MAFL paper presents an innovative solution to a challenging problem and offers several promising directions for future research.
Conclusion
Mutually-Aware Feature Learning (MAFL) is a novel approach to few-shot object counting that leverages the mutual information between feature representations of the support and query sets. By encouraging the model to learn features that capture the hidden relationships between these two sets, MAFL can achieve state-of-the-art performance on few-shot object counting tasks.
This breakthrough has the potential to significantly impact real-world applications where data is scarce, such as medical imaging and wildlife monitoring. By enabling accurate object counting from just a few examples, MAFL could lead to more efficient and cost-effective solutions in these domains.
While the paper presents promising results, there are also opportunities for further research to address potential limitations and explore the broader applicability of the mutual awareness approach. As the field of few-shot learning continues to advance, innovations like MAFL will play a crucial role in unlocking the full potential of AI systems to tackle complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mutually-Aware Feature Learning for Few-Shot Object Counting
Yerim Jeon, Subeen Lee, Jihwan Kim, Jae-Pil Heo
Few-shot object counting has garnered significant attention for its practicality as it aims to count target objects in a query image based on given exemplars without the need for additional training. However, there is a shortcoming in the prevailing extract-and-match approach: query and exemplar features lack interaction during feature extraction since they are extracted unaware of each other and later correlated based on similarity. This can lead to insufficient target awareness of the extracted features, resulting in target confusion in precisely identifying the actual target when multiple class objects coexist. To address this limitation, we propose a novel framework, Mutually-Aware FEAture learning(MAFEA), which encodes query and exemplar features mutually aware of each other from the outset. By encouraging interaction between query and exemplar features throughout the entire pipeline, we can obtain target-aware features that are robust to a multi-category scenario. Furthermore, we introduce a background token to effectively associate the target region of query with exemplars and decouple its background region from them. Our extensive experiments demonstrate that our model reaches a new state-of-the-art performance on the two challenging benchmarks, FSCD-LVIS and FSC-147, with a remarkably reduced degree of the target confusion problem.
Read more8/20/2024
0
Enhancing Few-Shot Image Classification through Learnable Multi-Scale Embedding and Attention Mechanisms
Fatemeh Askari, Amirreza Fateh, Mohammad Reza Mohammadi
In the context of few-shot classification, the goal is to train a classifier using a limited number of samples while maintaining satisfactory performance. However, traditional metric-based methods exhibit certain limitations in achieving this objective. These methods typically rely on a single distance value between the query feature and support feature, thereby overlooking the contribution of shallow features. To overcome this challenge, we propose a novel approach in this paper. Our approach involves utilizing multi-output embedding network that maps samples into distinct feature spaces. The proposed method extract feature vectors at different stages, enabling the model to capture both global and abstract features. By utilizing these diverse feature spaces, our model enhances its performance. Moreover, employing a self-attention mechanism improves the refinement of features at each stage, leading to even more robust representations and improved overall performance. Furthermore, assigning learnable weights to each stage significantly improved performance and results. We conducted comprehensive evaluations on the MiniImageNet and FC100 datasets, specifically in the 5-way 1-shot and 5-way 5-shot scenarios. Additionally, we performed a cross-domain task from MiniImageNet to the CUB dataset, achieving high accuracy in the testing domain. These evaluations demonstrate the efficacy of our proposed method in comparison to state-of-the-art approaches. https://github.com/FatemehAskari/MSENet
Read more9/14/2024

0
Zero-shot Object Counting with Good Exemplars
Huilin Zhu, Jingling Yuan, Zhengwei Yang, Yu Guo, Zheng Wang, Xian Zhong, Shengfeng He
Zero-shot object counting (ZOC) aims to enumerate objects in images using only the names of object classes during testing, without the need for manual annotations. However, a critical challenge in current ZOC methods lies in their inability to identify high-quality exemplars effectively. This deficiency hampers scalability across diverse classes and undermines the development of strong visual associations between the identified classes and image content. To this end, we propose the Visual Association-based Zero-shot Object Counting (VA-Count) framework. VA-Count consists of an Exemplar Enhancement Module (EEM) and a Noise Suppression Module (NSM) that synergistically refine the process of class exemplar identification while minimizing the consequences of incorrect object identification. The EEM utilizes advanced vision-language pretaining models to discover potential exemplars, ensuring the framework's adaptability to various classes. Meanwhile, the NSM employs contrastive learning to differentiate between optimal and suboptimal exemplar pairs, reducing the negative effects of erroneous exemplars. VA-Count demonstrates its effectiveness and scalability in zero-shot contexts with superior performance on two object counting datasets.
Read more7/10/2024

0
SMILe: Leveraging Submodular Mutual Information For Robust Few-Shot Object Detection
Anay Majee, Ryan Sharp, Rishabh Iyer
Confusion and forgetting of object classes have been challenges of prime interest in Few-Shot Object Detection (FSOD). To overcome these pitfalls in metric learning based FSOD techniques, we introduce a novel Submodular Mutual Information Learning (SMILe) framework which adopts combinatorial mutual information functions to enforce the creation of tighter and discriminative feature clusters in FSOD. Our proposed approach generalizes to several existing approaches in FSOD, agnostic of the backbone architecture demonstrating elevated performance gains. A paradigm shift from instance based objective functions to combinatorial objectives in SMILe naturally preserves the diversity within an object class resulting in reduced forgetting when subjected to few training examples. Furthermore, the application of mutual information between the already learnt (base) and newly added (novel) objects ensures sufficient separation between base and novel classes, minimizing the effect of class confusion. Experiments on popular FSOD benchmarks, PASCAL-VOC and MS-COCO show that our approach generalizes to State-of-the-Art (SoTA) approaches improving their novel class performance by up to 5.7% (3.3 mAP points) and 5.4% (2.6 mAP points) on the 10-shot setting of VOC (split 3) and 30-shot setting of COCO datasets respectively. Our experiments also demonstrate better retention of base class performance and up to 2x faster convergence over existing approaches agnostic of the underlying architecture.
Read more9/18/2024