MVAD: A Multiple Visual Artifact Detector for Video Streaming

0
Sign in to get full access
Overview
- This paper introduces a novel approach called MVAD (Multiple Visual Artifact Detector) for detecting multiple types of visual artifacts in video streaming.
- The researchers developed MVAD to address the challenge of simultaneously detecting different types of visual artifacts, such as blockiness, blurriness, and flickering, which can degrade the quality of video streaming.
- MVAD combines multiple specialized neural networks to identify these diverse artifacts, providing a comprehensive solution for video quality assessment.
Plain English Explanation
The paper presents a new system called MVAD that can detect various types of visual problems in video streams. When you watch videos online, they may sometimes look blurry, have blocky edges, or flicker. These are examples of "visual artifacts" that can make the video quality poor.
The researchers created MVAD to automatically identify these different types of visual artifacts all at once. MVAD uses multiple specialized neural networks, each trained to detect a specific type of artifact. By combining these specialized models, MVAD can provide a comprehensive assessment of video quality and identify the different issues that may be present.
This is an important advancement, as previous approaches could only detect one type of artifact at a time. MVAD's ability to handle multiple artifacts simultaneously makes it a more robust and practical solution for evaluating the quality of video streaming.
Technical Explanation
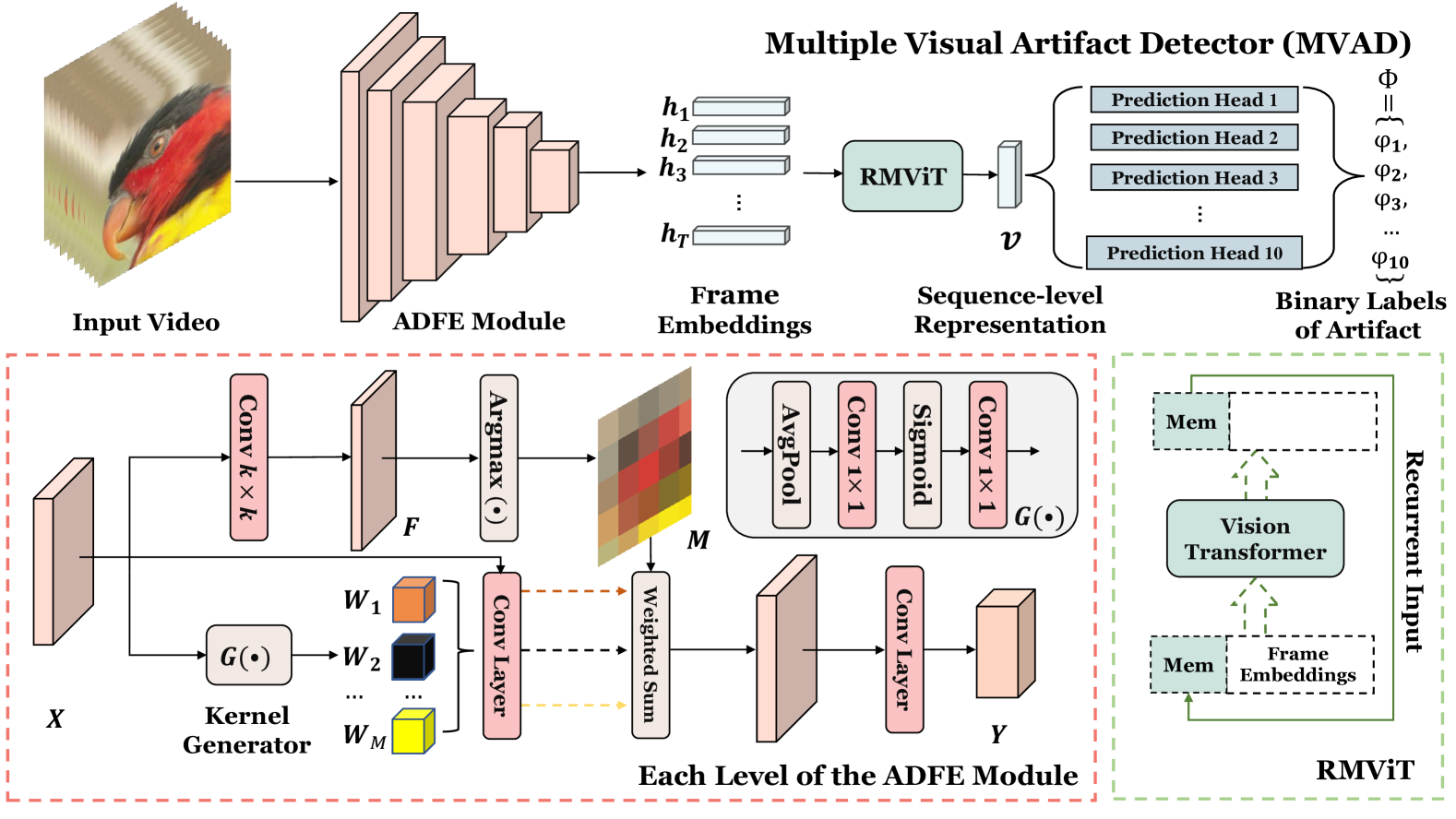
The paper introduces the MVAD (Multiple Visual Artifact Detector) framework, which combines multiple specialized neural networks to detect various types of visual artifacts in video streams. Previous approaches [link to related work papers] could only identify one type of artifact at a time, while MVAD is designed to handle blockiness, blurriness, flickering, and other artifacts concurrently.
The MVAD architecture consists of multiple sub-networks, each trained to detect a specific visual artifact. These sub-networks include a Blockiness Detector, a Blurriness Detector, and a Flickering Detector, among others. The outputs of these sub-networks are then combined to provide a comprehensive assessment of the video's quality.
The researchers conducted extensive experiments to evaluate MVAD's performance on a diverse dataset of video sequences with various types of artifacts. The results demonstrate that MVAD outperforms single-task artifact detectors and can accurately identify multiple artifacts simultaneously.
Critical Analysis
The paper provides a thorough and well-designed approach to addressing the challenge of multi-artifact detection in video streaming. The researchers' decision to combine specialized sub-networks is a logical and effective strategy, as it allows MVAD to leverage the strengths of individual artifact detectors while providing a holistic assessment.
However, the paper does not address the potential computational complexity and resource requirements of running multiple sub-networks simultaneously. This could be an important consideration for real-world deployment, especially in resource-constrained environments. [link to paper on supervised anomaly detection in complex industrial images]
Additionally, the authors do not provide much discussion on the potential biases or limitations of the training data used to develop MVAD. It would be valuable to understand how the system might perform on a more diverse set of video content or in different cultural contexts. [link to paper on evaluating effectiveness of video anomaly detection in the wild]
Conclusion
The MVAD framework presented in this paper represents a significant advancement in video quality assessment. By combining specialized neural networks to detect multiple types of visual artifacts, MVAD offers a comprehensive solution that can help improve the overall experience of video streaming.
The researchers' innovative approach and thorough evaluation demonstrate the potential of MVAD to become a valuable tool for video content providers, streaming platforms, and video processing applications. As the demand for high-quality video content continues to grow, solutions like MVAD will play an increasingly important role in ensuring that viewers receive the best possible viewing experience. [link to paper on video-based morphing attack detection]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MVAD: A Multiple Visual Artifact Detector for Video Streaming
Chen Feng, Duolikun Danier, Fan Zhang, David Bull
Visual artifacts are often introduced into streamed video content, due to prevailing conditions during content production and/or delivery. Since these can degrade the quality of the user's experience, it is important to automatically and accurately detect them in order to enable effective quality measurement and enhancement. Existing detection methods often focus on a single type of artifact and/or determine the presence of an artifact through thresholding objective quality indices. Such approaches have been reported to offer inconsistent prediction performance and are also impractical for real-world applications where multiple artifacts co-exist and interact. In this paper, we propose a Multiple Visual Artifact Detector, MVAD, for video streaming which, for the first time, is able to detect multiple artifacts using a single framework that is not reliant on video quality assessment models. Our approach employs a new Artifact-aware Dynamic Feature Extractor (ADFE) to obtain artifact-relevant spatial features within each frame for multiple artifact types. The extracted features are further processed by a Recurrent Memory Vision Transformer (RMViT) module, which captures both short-term and long-term temporal information within the input video. The proposed network architecture is optimized in an end-to-end manner based on a new, large and diverse training database that is generated by simulating the video streaming pipeline and based on Adversarial Data Augmentation. This model has been evaluated on two video artifact databases, Maxwell and BVI-Artifact, and achieves consistent and improved prediction results for ten target visual artifacts when compared to seven existing single and multiple artifact detectors. The source code and training database will be available at https://chenfeng-bristol.github.io/MVAD/.
Read more6/4/2024

0
Learning Multi-view Anomaly Detection
Haoyang He, Jiangning Zhang, Guanzhong Tian, Chengjie Wang, Lei Xie
This study explores the recently proposed challenging multi-view Anomaly Detection (AD) task. Single-view tasks would encounter blind spots from other perspectives, resulting in inaccuracies in sample-level prediction. Therefore, we introduce the textbf{M}ulti-textbf{V}iew textbf{A}nomaly textbf{D}etection (textbf{MVAD}) framework, which learns and integrates features from multi-views. Specifically, we proposed a textbf{M}ulti-textbf{V}iew textbf{A}daptive textbf{S}election (textbf{MVAS}) algorithm for feature learning and fusion across multiple views. The feature maps are divided into neighbourhood attention windows to calculate a semantic correlation matrix between single-view windows and all other views, which is a conducted attention mechanism for each single-view window and the top-K most correlated multi-view windows. Adjusting the window sizes and top-K can minimise the computational complexity to linear. Extensive experiments on the Real-IAD dataset for cross-setting (multi/single-class) validate the effectiveness of our approach, achieving state-of-the-art performance among sample textbf{4.1%}$uparrow$/ image textbf{5.6%}$uparrow$/pixel textbf{6.7%}$uparrow$ levels with a total of ten metrics with only textbf{18M} parameters and fewer GPU memory and training time.
Read more7/17/2024
✨
0
New!Multimodal Attention-Enhanced Feature Fusion-based Weekly Supervised Anomaly Violence Detection
Yuta Kaneko, Abu Saleh Musa Miah, Najmul Hassan, Hyoun-Sup Lee, Si-Woong Jang, Jungpil Shin
Weakly supervised video anomaly detection (WS-VAD) is a crucial area in computer vision for developing intelligent surveillance systems. This system uses three feature streams: RGB video, optical flow, and audio signals, where each stream extracts complementary spatial and temporal features using an enhanced attention module to improve detection accuracy and robustness. In the first stream, we employed an attention-based, multi-stage feature enhancement approach to improve spatial and temporal features from the RGB video where the first stage consists of a ViT-based CLIP module, with top-k features concatenated in parallel with I3D and Temporal Contextual Aggregation (TCA) based rich spatiotemporal features. The second stage effectively captures temporal dependencies using the Uncertainty-Regulated Dual Memory Units (UR-DMU) model, which learns representations of normal and abnormal data simultaneously, and the third stage is employed to select the most relevant spatiotemporal features. The second stream extracted enhanced attention-based spatiotemporal features from the flow data modality-based feature by taking advantage of the integration of the deep learning and attention module. The audio stream captures auditory cues using an attention module integrated with the VGGish model, aiming to detect anomalies based on sound patterns. These streams enrich the model by incorporating motion and audio signals often indicative of abnormal events undetectable through visual analysis alone. The concatenation of the multimodal fusion leverages the strengths of each modality, resulting in a comprehensive feature set that significantly improves anomaly detection accuracy and robustness across three datasets. The extensive experiment and high performance with the three benchmark datasets proved the effectiveness of the proposed system over the existing state-of-the-art system.
Read more9/18/2024
🤷
0
Exploring Plain ViT Reconstruction for Multi-class Unsupervised Anomaly Detection
Jiangning Zhang, Xuhai Chen, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, Ming-Hsuan Yang, Dacheng Tao
This work studies a challenging and practical issue known as multi-class unsupervised anomaly detection (MUAD). This problem requires only normal images for training while simultaneously testing both normal and anomaly images across multiple classes. Existing reconstruction-based methods typically adopt pyramidal networks as encoders and decoders to obtain multi-resolution features, often involving complex sub-modules with extensive handcraft engineering. In contrast, a plain Vision Transformer (ViT) showcasing a more straightforward architecture has proven effective in multiple domains, including detection and segmentation tasks. It is simpler, more effective, and elegant. Following this spirit, we explore the use of only plain ViT features for MUAD. We first abstract a Meta-AD concept by synthesizing current reconstruction-based methods. Subsequently, we instantiate a novel ViT-based ViTAD structure, designed incrementally from both global and local perspectives. This model provide a strong baseline to facilitate future research. Additionally, this paper uncovers several intriguing findings for further investigation. Finally, we comprehensively and fairly benchmark various approaches using eight metrics. Utilizing a basic training regimen with only an MSE loss, ViTAD achieves state-of-the-art results and efficiency on MVTec AD, VisA, and Uni-Medical datasets. Eg, achieving 85.4 mAD that surpasses UniAD by +3.0 for the MVTec AD dataset, and it requires only 1.1 hours and 2.3G GPU memory to complete model training on a single V100 that can serve as a strong baseline to facilitate the development of future research. Full code is available at https://zhangzjn.github.io/projects/ViTAD/.
Read more8/13/2024