MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
2402.12712
0
0
📈
Abstract
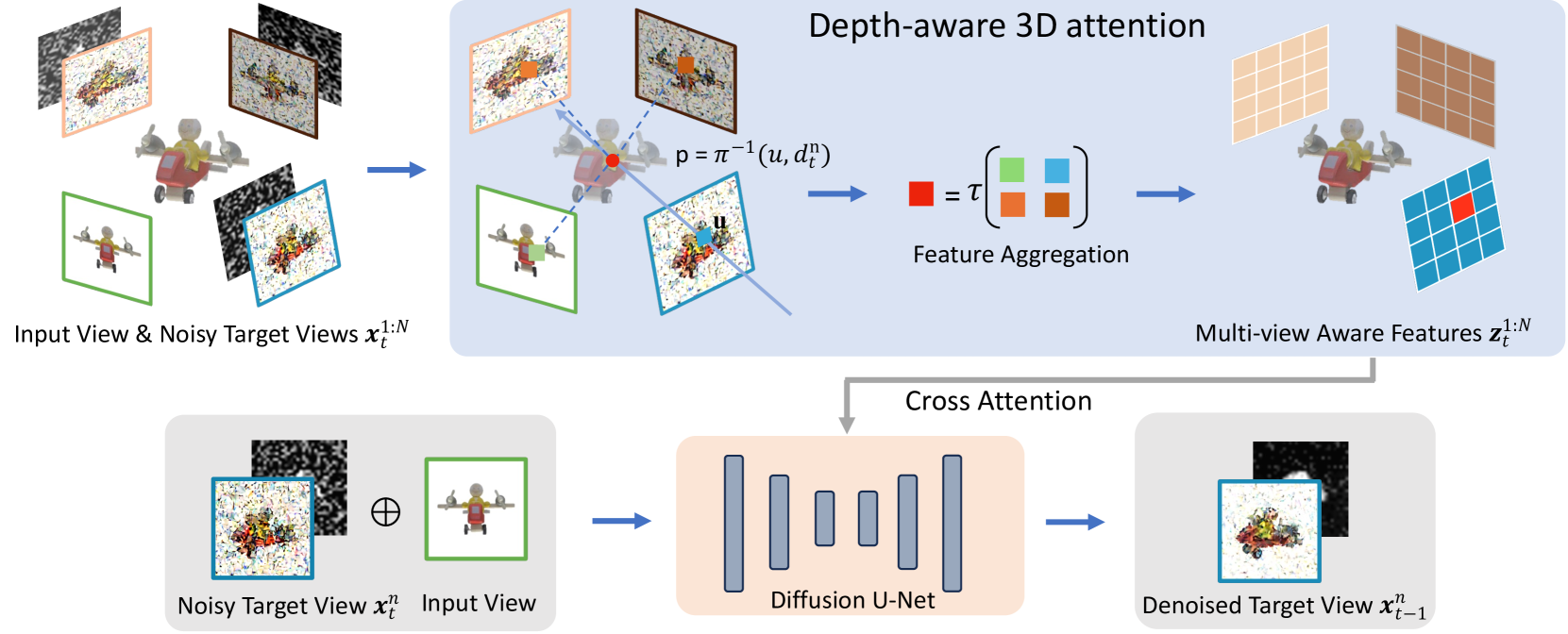
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model. The project page is at https://mvdiffusion-plusplus.github.io.
Create account to get full access
Overview
- This paper provides guidelines for authors submitting papers to the European Conference on Computer Vision (ECCV).
- It covers important details like paper formatting, submission requirements, and review process.
- The guidelines ensure a consistent and high-quality submission experience for all authors.
Plain English Explanation
The provided paper contains the official guidelines for authors who want to submit their research work to the European Conference on Computer Vision (ECCV). ECCV is a prestigious computer vision conference where researchers present their latest advancements in areas like object detection, image recognition, and 3D reconstruction.
The guidelines outline the specific formatting and submission requirements authors must follow to have their papers considered for the conference. This includes details like the maximum page limit, required sections (e.g. abstract, introduction, experiments), and formatting rules for text, figures, and references.
The guidelines also explain the review process that submitted papers will go through. Each paper is carefully evaluated by multiple experts in the field to assess its technical merits, novelty, and potential impact. Only the strongest papers are ultimately accepted for presentation at the conference.
By following these guidelines, authors can ensure their submissions meet the high standards expected by the ECCV organizers and reviewers. This helps create a consistent, fair, and high-quality conference program for all attendees.
Technical Explanation
The ECCV author guidelines document specifies the required format and submission process for papers to be considered for the conference. It includes details on:
- Paper Formatting: Papers must adhere to a specific page limit (typically 14 pages), use a predefined LaTeX template, and follow strict formatting rules for text, figures, tables, and references.
- Submission Requirements: Authors must submit their paper, source code, and any supplementary materials through the conference's online submission system by the specified deadlines.
- Review Process: Submitted papers undergo a double-blind peer review process, where they are evaluated by multiple expert reviewers based on criteria like technical quality, novelty, and potential impact. Only the highest-rated papers are accepted for presentation at the conference.
- Camera-Ready Submission: Authors of accepted papers must then submit a final camera-ready version that incorporates any requested revisions from the review process.
By clearly outlining these guidelines, the ECCV organizers aim to ensure a standardized and high-quality submission experience for all authors. This helps maintain the conference's reputation for publishing leading-edge computer vision research.
Critical Analysis
The ECCV author guidelines provide a comprehensive and well-structured set of instructions for paper submission. The detailed formatting requirements help create a consistent visual presentation across the accepted papers, which is important for the conference proceedings.
However, one potential limitation is the strict page limit, which may force authors to omit important details or technical explanations from their submissions. Additionally, the double-blind review process, while intended to be fair, could introduce biases if reviewers are able to infer the authors' identities through the content or writing style.
It would be valuable for the guidelines to also address the potential ethical considerations of the research being presented, such as the societal implications or potential for misuse of the developed technologies. This could help encourage authors to reflect on the broader impact of their work.
Overall, the ECCV author guidelines serve an important role in maintaining the quality and consistency of the conference. But there may be opportunities to further refine the process to address potential issues and ensure the research presented aligns with ethical principles.
Conclusion
The ECCV author guidelines provide a clear and comprehensive set of instructions for researchers wishing to submit their work to the prestigious European Conference on Computer Vision. By outlining the formatting requirements, submission process, and review criteria, the guidelines help ensure a standardized and high-quality conference program.
While the guidelines cover the technical aspects of paper submission, there may be value in also addressing the ethical considerations of the presented research. This could help foster a conference environment that not only celebrates technical innovation, but also encourages researchers to thoughtfully consider the broader societal impact of their work.
Overall, the ECCV author guidelines play a crucial role in upholding the conference's reputation for publishing cutting-edge computer vision research. By following these guidelines, authors can increase their chances of having their work accepted and contributing to the advancement of the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024
🛸
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, Xiao Yang
0
0
We introduce MVDream, a diffusion model that is able to generate consistent multi-view images from a given text prompt. Learning from both 2D and 3D data, a multi-view diffusion model can achieve the generalizability of 2D diffusion models and the consistency of 3D renderings. We demonstrate that such a multi-view diffusion model is implicitly a generalizable 3D prior agnostic to 3D representations. It can be applied to 3D generation via Score Distillation Sampling, significantly enhancing the consistency and stability of existing 2D-lifting methods. It can also learn new concepts from a few 2D examples, akin to DreamBooth, but for 3D generation.
4/19/2024
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Hanzhe Hu, Zhizhuo Zhou, Varun Jampani, Shubham Tulsiani
0
0
We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
4/5/2024

Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, Bernard Ghanem
0
0
While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
6/14/2024