MVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification

0

Sign in to get full access
Overview
- This paper presents MVGaussian, a high-fidelity text-to-3D content generation system that uses multi-view guidance and surface densification.
- MVGaussian generates 3D models from text descriptions, aiming to achieve realistic and detailed results.
- The system leverages multi-view guidance to capture the full 3D geometry and surface densification to enhance the fidelity of the generated models.
Plain English Explanation
MVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification is a method for creating 3D models from text descriptions. The goal is to generate 3D objects that look realistic and have a high level of detail.
The key ideas are:
- Multi-view Guidance: The system uses information from multiple viewpoints (e.g., front, side, top) to capture the full 3D shape of the object. This helps ensure the generated model accurately represents the 3D geometry.
- Surface Densification: The method enhances the surface detail of the generated 3D model, making it look more realistic and lifelike. This helps fill in missing details that might be lost when converting a text description into a 3D shape.
By combining these two techniques, MVGaussian is able to create 3D models from text that are high-fidelity - meaning they look very realistic and true to the original description.
Technical Explanation
MVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification introduces a novel approach for generating 3D content from text inputs. The key innovations are:
-
Multi-View Guidance: The system takes a text description as input and generates 2D rendering views (e.g., front, side, top) of the corresponding 3D object. These multiple views are then used to guide the 3D reconstruction, ensuring the final model accurately captures the full 3D geometry.
-
Surface Densification: After generating the coarse 3D shape, the method applies a surface densification step to enhance the level of detail and realism. This involves adding more surface points to fill in missing information and create a smoother, more realistic appearance.
The architecture consists of several components:
- A text encoder to embed the input description
- Multiple view generators to produce 2D rendering views
- A 3D reconstruction module that uses the multi-view guidance to estimate the 3D shape
- A surface densification network that refines the 3D geometry
The researchers demonstrate the effectiveness of MVGaussian through extensive experiments, showing it can generate high-quality 3D models from a variety of text inputs with fine-grained details.
Critical Analysis
The paper presents a compelling approach for text-to-3D content generation that addresses important limitations of prior work. By incorporating multi-view guidance and surface densification, MVGaussian is able to generate 3D models with greater fidelity and realism compared to previous methods.
Some potential areas for further research include:
- Exploring ways to further improve the level of detail and surface quality of the generated 3D models
- Investigating how the system handles more complex or abstract text descriptions
- Assessing the computational efficiency and scalability of the approach
Additionally, it would be interesting to see how MVGaussian performs in real-world applications, such as 3D asset creation for games, virtual environments, or e-commerce.
Conclusion
MVGaussian presents a significant advance in the field of text-to-3D content generation. By leveraging multi-view guidance and surface densification, the system is able to generate 3D models with a high level of fidelity and realism from text descriptions. This technology has the potential to greatly streamline 3D asset creation and enable more accessible 3D content generation. Overall, the paper demonstrates an impressive integration of techniques to push the boundaries of what is possible in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MVGaussian: High-Fidelity text-to-3D Content Generation with Multi-View Guidance and Surface Densification
Phu Pham, Aradhya N. Mathur, Ojaswa Sharma, Aniket Bera
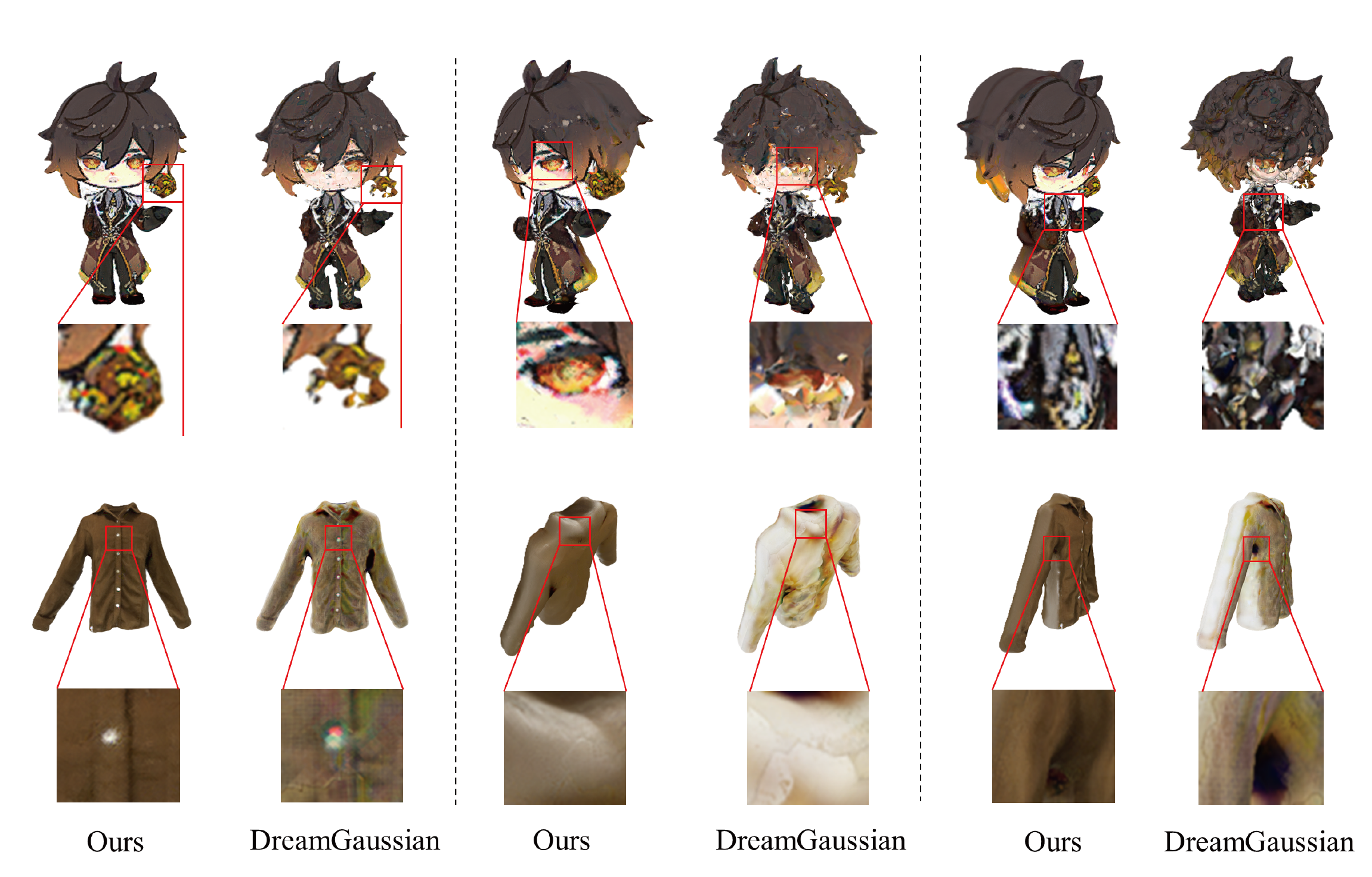
The field of text-to-3D content generation has made significant progress in generating realistic 3D objects, with existing methodologies like Score Distillation Sampling (SDS) offering promising guidance. However, these methods often encounter the Janus problem-multi-face ambiguities due to imprecise guidance. Additionally, while recent advancements in 3D gaussian splitting have shown its efficacy in representing 3D volumes, optimization of this representation remains largely unexplored. This paper introduces a unified framework for text-to-3D content generation that addresses these critical gaps. Our approach utilizes multi-view guidance to iteratively form the structure of the 3D model, progressively enhancing detail and accuracy. We also introduce a novel densification algorithm that aligns gaussians close to the surface, optimizing the structural integrity and fidelity of the generated models. Extensive experiments validate our approach, demonstrating that it produces high-quality visual outputs with minimal time cost. Notably, our method achieves high-quality results within half an hour of training, offering a substantial efficiency gain over most existing methods, which require hours of training time to achieve comparable results.
Read more9/11/2024

0
GVGEN: Text-to-3D Generation with Volumetric Representation
Xianglong He, Junyi Chen, Sida Peng, Di Huang, Yangguang Li, Xiaoshui Huang, Chun Yuan, Wanli Ouyang, Tong He
In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed ($sim$7 seconds), effectively striking a balance between quality and efficiency. Our project page is: https://gvgen.github.io/
Read more7/17/2024
🌐
0
Text-to-3D using Gaussian Splatting
Zilong Chen, Feng Wang, Yikai Wang, Huaping Liu
Automatic text-to-3D generation that combines Score Distillation Sampling (SDS) with the optimization of volume rendering has achieved remarkable progress in synthesizing realistic 3D objects. Yet most existing text-to-3D methods by SDS and volume rendering suffer from inaccurate geometry, e.g., the Janus issue, since it is hard to explicitly integrate 3D priors into implicit 3D representations. Besides, it is usually time-consuming for them to generate elaborate 3D models with rich colors. In response, this paper proposes GSGEN, a novel method that adopts Gaussian Splatting, a recent state-of-the-art representation, to text-to-3D generation. GSGEN aims at generating high-quality 3D objects and addressing existing shortcomings by exploiting the explicit nature of Gaussian Splatting that enables the incorporation of 3D prior. Specifically, our method adopts a progressive optimization strategy, which includes a geometry optimization stage and an appearance refinement stage. In geometry optimization, a coarse representation is established under 3D point cloud diffusion prior along with the ordinary 2D SDS optimization, ensuring a sensible and 3D-consistent rough shape. Subsequently, the obtained Gaussians undergo an iterative appearance refinement to enrich texture details. In this stage, we increase the number of Gaussians by compactness-based densification to enhance continuity and improve fidelity. With these designs, our approach can generate 3D assets with delicate details and accurate geometry. Extensive evaluations demonstrate the effectiveness of our method, especially for capturing high-frequency components. Our code is available at https://github.com/gsgen3d/gsgen
Read more4/3/2024
0
ScalingGaussian: Enhancing 3D Content Creation with Generative Gaussian Splatting
Shen Chen, Jiale Zhou, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, Jenq-Neng Hwang, Lei Li
The creation of high-quality 3D assets is paramount for applications in digital heritage preservation, entertainment, and robotics. Traditionally, this process necessitates skilled professionals and specialized software for the modeling, texturing, and rendering of 3D objects. However, the rising demand for 3D assets in gaming and virtual reality (VR) has led to the creation of accessible image-to-3D technologies, allowing non-professionals to produce 3D content and decreasing dependence on expert input. Existing methods for 3D content generation struggle to simultaneously achieve detailed textures and strong geometric consistency. We introduce a novel 3D content creation framework, ScalingGaussian, which combines 3D and 2D diffusion models to achieve detailed textures and geometric consistency in generated 3D assets. Initially, a 3D diffusion model generates point clouds, which are then densified through a process of selecting local regions, introducing Gaussian noise, followed by using local density-weighted selection. To refine the 3D gaussians, we utilize a 2D diffusion model with Score Distillation Sampling (SDS) loss, guiding the 3D Gaussians to clone and split. Finally, the 3D Gaussians are converted into meshes, and the surface textures are optimized using Mean Square Error(MSE) and Gradient Profile Prior(GPP) losses. Our method addresses the common issue of sparse point clouds in 3D diffusion, resulting in improved geometric structure and detailed textures. Experiments on image-to-3D tasks demonstrate that our approach efficiently generates high-quality 3D assets.
Read more7/30/2024