Neural Assembler: Learning to Generate Fine-Grained Robotic Assembly Instructions from Multi-View Images

0

Sign in to get full access
Overview
- This paper presents a novel neural network model called "Neural Assembler" that can generate fine-grained robotic assembly instructions from multi-view images.
- The model learns to identify and understand the components and their spatial relationships in 3D objects, and then generates step-by-step assembly instructions.
- The model is trained on a large dataset of 3D object models and their corresponding assembly instructions, and is evaluated on its ability to generate accurate and interpretable instructions for new objects.
Plain English Explanation
The Neural Assembler is a machine learning model that can look at multiple images of an object and automatically generate step-by-step instructions for assembling that object. This could be very useful for robotics applications, where a robot needs to be able to put together complex 3D objects by following instructions.
The key idea is that the model learns to understand the individual components that make up a 3D object, as well as how those components fit together in space. It does this by training on a large dataset of 3D object models and their corresponding assembly instructions.
Once trained, the model can take in new images of an object from different angles, and use that 3D understanding to generate a sequence of assembly steps that explain how to put the object together. This could be incredibly helpful for automating tasks like furniture assembly, manufacturing, or even repair and maintenance.
The researchers show that their Neural Assembler model can generate very detailed and accurate assembly instructions, outperforming previous approaches. This is an exciting advance that could have a big impact on the ability of robots and other autonomous systems to independently assemble complex 3D objects.
Technical Explanation
The Neural Assembler model proposed in this paper is designed to generate fine-grained robotic assembly instructions from multi-view images of 3D objects.
The key components of the model are:
- A 3D object understanding module that learns to identify the individual parts of an object and their spatial relationships from multi-view images.
- An assembly instruction generation module that takes the 3D object understanding and generates a sequence of assembly steps.
The model is trained end-to-end on a large dataset of 3D object models and their corresponding assembly instructions. During inference, the model takes in multi-view images of a new object and outputs a step-by-step assembly procedure.
The researchers evaluate the Neural Assembler on both synthetic and real-world datasets, and show that it outperforms previous approaches in generating accurate and interpretable assembly instructions. This highlights the model's ability to effectively learn the underlying 3D structure and assembly dynamics of complex objects.
Critical Analysis
The Neural Assembler paper makes a compelling contribution to the field of robotic assembly and 3D object understanding. The ability to automatically generate fine-grained assembly instructions from visual inputs is a challenging and important problem, with many potential real-world applications.
One key strength of the work is the end-to-end training approach, which allows the model to jointly learn object understanding and instruction generation in an integrated fashion. This likely contributes to the strong performance observed in the experiments.
However, the paper also acknowledges several limitations and avenues for future work. For example, the current model is trained and evaluated on a relatively restricted set of object types and assembly procedures. Extending the approach to handle greater diversity, complexity, and real-world noise and uncertainty would be an important next step.
Additionally, the paper does not deeply explore the model's interpretability and transparency - it would be valuable to better understand how the 3D object understanding and instruction generation components work, and how they can be inspected and debugged. Incorporating more explicit modeling of the assembly process may also help improve the quality and reliability of the generated instructions.
Overall, the Neural Assembler is a promising step forward, and the researchers have laid a strong foundation for continued progress in this important area of robotic and autonomous systems research.
Conclusion
The Neural Assembler model presented in this paper represents an exciting advance in the ability of machines to understand and assemble complex 3D objects. By learning to extract the underlying 3D structure and assembly dynamics from visual inputs, the model can generate detailed, step-by-step instructions for putting objects together.
This capability has the potential to significantly impact a wide range of robotic and autonomous applications, from furniture assembly to manufacturing to maintenance and repair. As the researchers continue to refine and expand the model, it could lead to more capable, flexible, and user-friendly robotic systems that can independently tackle a growing variety of assembly tasks.
Overall, the Neural Assembler is a notable contribution to the fields of computer vision, robotics, and artificial intelligence, demonstrating the power of end-to-end learning to tackle complex, real-world challenges. As the technology matures, it could unlock new frontiers in automation and human-machine collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Assembler: Learning to Generate Fine-Grained Robotic Assembly Instructions from Multi-View Images
Hongyu Yan, Yadong Mu
Image-guided object assembly represents a burgeoning research topic in computer vision. This paper introduces a novel task: translating multi-view images of a structural 3D model (for example, one constructed with building blocks drawn from a 3D-object library) into a detailed sequence of assembly instructions executable by a robotic arm. Fed with multi-view images of the target 3D model for replication, the model designed for this task must address several sub-tasks, including recognizing individual components used in constructing the 3D model, estimating the geometric pose of each component, and deducing a feasible assembly order adhering to physical rules. Establishing accurate 2D-3D correspondence between multi-view images and 3D objects is technically challenging. To tackle this, we propose an end-to-end model known as the Neural Assembler. This model learns an object graph where each vertex represents recognized components from the images, and the edges specify the topology of the 3D model, enabling the derivation of an assembly plan. We establish benchmarks for this task and conduct comprehensive empirical evaluations of Neural Assembler and alternative solutions. Our experiments clearly demonstrate the superiority of Neural Assembler.
Read more4/26/2024

0
Cognitive Manipulation: Semi-supervised Visual Representation and Classroom-to-real Reinforcement Learning for Assembly in Semi-structured Environments
Chuang Wang, Lie Yang, Ze Lin, Yizhi Liao, Gang Chen, Longhan Xie
Assembling a slave object into a fixture-free master object represents a critical challenge in flexible manufacturing. Existing deep reinforcement learning-based methods, while benefiting from visual or operational priors, often struggle with small-batch precise assembly tasks due to their reliance on insufficient priors and high-costed model development. To address these limitations, this paper introduces a cognitive manipulation and learning approach that utilizes skill graphs to integrate learning-based object detection with fine manipulation models into a cohesive modular policy. This approach enables the detection of the master object from both global and local perspectives to accommodate positional uncertainties and variable backgrounds, and parametric residual policy to handle pose error and intricate contact dynamics effectively. Leveraging the skill graph, our method supports knowledge-informed learning of semi-supervised learning for object detection and classroom-to-real reinforcement learning for fine manipulation. Simulation experiments on a gear-assembly task have demonstrated that the skill-graph-enabled coarse-operation planning and visual attention are essential for efficient learning and robust manipulation, showing substantial improvements of 13$%$ in success rate and 15.4$%$ in number of completion steps over competing methods. Real-world experiments further validate that our system is highly effective for robotic assembly in semi-structured environments.
Read more6/4/2024

0
Component Selection for Craft Assembly Tasks
Vitor Hideyo Isume (Osaka University), Takuya Kiyokawa (Osaka University), Natsuki Yamanobe (AIST), Yukiyasu Domae (AIST), Weiwei Wan (Osaka University), Kensuke Harada (Osaka University, AIST)
Inspired by traditional handmade crafts, where a person improvises assemblies based on the available objects, we formally introduce the Craft Assembly Task. It is a robotic assembly task that involves building an accurate representation of a given target object using the available objects, which do not directly correspond to its parts. In this work, we focus on selecting the subset of available objects for the final craft, when the given input is an RGB image of the target in the wild. We use a mask segmentation neural network to identify visible parts, followed by retrieving labelled template meshes. These meshes undergo pose optimization to determine the most suitable template. Then, we propose to simplify the parts of the transformed template mesh to primitive shapes like cuboids or cylinders. Finally, we design a search algorithm to find correspondences in the scene based on local and global proportions. We develop baselines for comparison that consider all possible combinations, and choose the highest scoring combination for common metrics used in foreground maps and mask accuracy. Our approach achieves comparable results to the baselines for two different scenes, and we show qualitative results for an implementation in a real-world scenario.
Read more8/19/2024
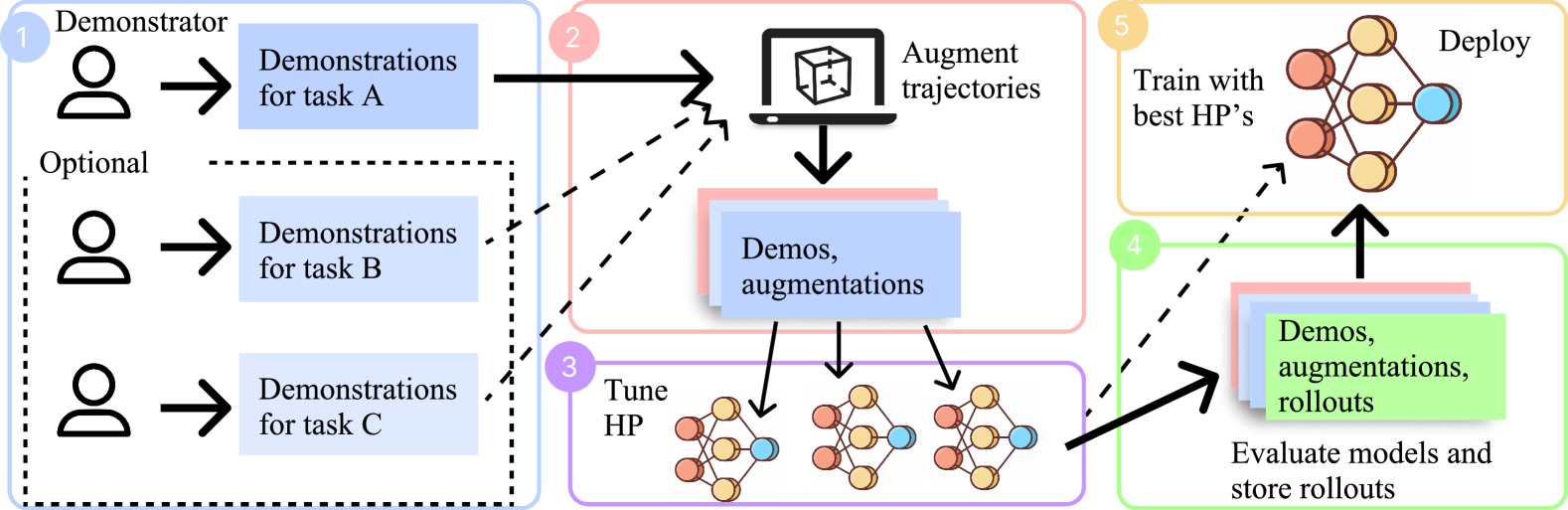
0
JUICER: Data-Efficient Imitation Learning for Robotic Assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Pulkit Agrawal
While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines. Project website: https://imitation-juicer.github.io/.
Read more4/11/2024