Neural Message Passing Induced by Energy-Constrained Diffusion

0
Sign in to get full access
Overview
- The paper explores the connection between physics-inspired message passing and deep learning models like Graph Neural Networks (GNNs) and Transformers.
- It introduces a general neural message passing framework that can be used to derive various neural architectures.
- The framework is inspired by the physics concept of energy-constrained message passing, which aims to minimize the information loss during message exchange.
Plain English Explanation
The paper looks at how the way information is passed between nodes in physics-inspired neural networks can be used to develop powerful machine learning models.
In these types of networks, each node (like a neuron) sends "messages" to other nodes it's connected to. The researchers show that by designing these message passing rules to minimize the amount of information lost, you can create neural network architectures that perform well on a variety of tasks.
This includes Graph Neural Networks (GNNs), which are good at working with data in the form of graphs, and Transformers, a type of neural network that has achieved state-of-the-art results in areas like natural language processing.
The key insight is that by taking inspiration from how information is passed in physical systems, you can build neural networks that are efficient at processing and propagating information - which is crucial for many real-world machine learning problems.
Technical Explanation
The paper introduces a general neural message passing framework that can be used to derive various neural architectures, including GNNs and Transformers.
The framework is inspired by the physics concept of energy-constrained message passing, which aims to minimize the information loss during message exchange. This is achieved by defining message passing rules that optimize for a global energy function.
The authors show that by varying the form of the energy function, they can obtain different neural architectures with unique inductive biases. For example, using an energy function that encourages local information sharing leads to architectures similar to GNNs, while an energy function promoting long-range interactions results in Transformer-like models.
The paper also introduces the concept of virtual nodes, which can be used to probabilistically rewire the graph structure during training, allowing the network to adaptively learn the optimal connectivity pattern.
Overall, the framework provides a principled way to learn diffusion dynamics at lightspeed and derive a wide range of powerful neural architectures from first principles.
Critical Analysis
The paper presents a novel and promising approach to designing neural network architectures, but it also raises some interesting questions and concerns:
-
The energy-constrained message passing framework is quite general, but it's not always clear how to choose the appropriate energy function for a given problem. More guidance on this process would be helpful.
-
While the virtual node concept is intriguing, the paper does not provide a thorough analysis of its impact on performance and training stability. More research is needed to understand the limitations and edge cases of this technique.
-
The connection between the proposed framework and classical physics is somewhat loose - it's not obvious how the energy minimization principle directly maps to desirable neural network properties. A deeper exploration of this analogy could strengthen the theoretical foundations.
-
The paper focuses on the architectural aspects of the framework, but does not delve into practical considerations like training efficiency, scalability, and generalization to real-world tasks. Empirical evaluations on a wider range of benchmarks would help assess the framework's broader applicability.
Overall, the paper introduces an interesting new perspective on neural network design that merits further exploration and refinement. The ideas presented have the potential to inspire new breakthroughs, but additional research is needed to fully realize their impact.
Conclusion
The paper presents a physics-inspired neural message passing framework that can be used to derive a wide range of neural architectures, including GNNs and Transformers. The key insight is that by designing message passing rules to minimize information loss, you can create efficient and powerful models for processing complex data.
While the framework is promising, the paper also highlights the need for more research to fully understand its implications and limitations. Continuing to explore the connections between physics and deep learning could lead to even more exciting advancements in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Message Passing Induced by Energy-Constrained Diffusion
Qitian Wu, David Wipf, Junchi Yan
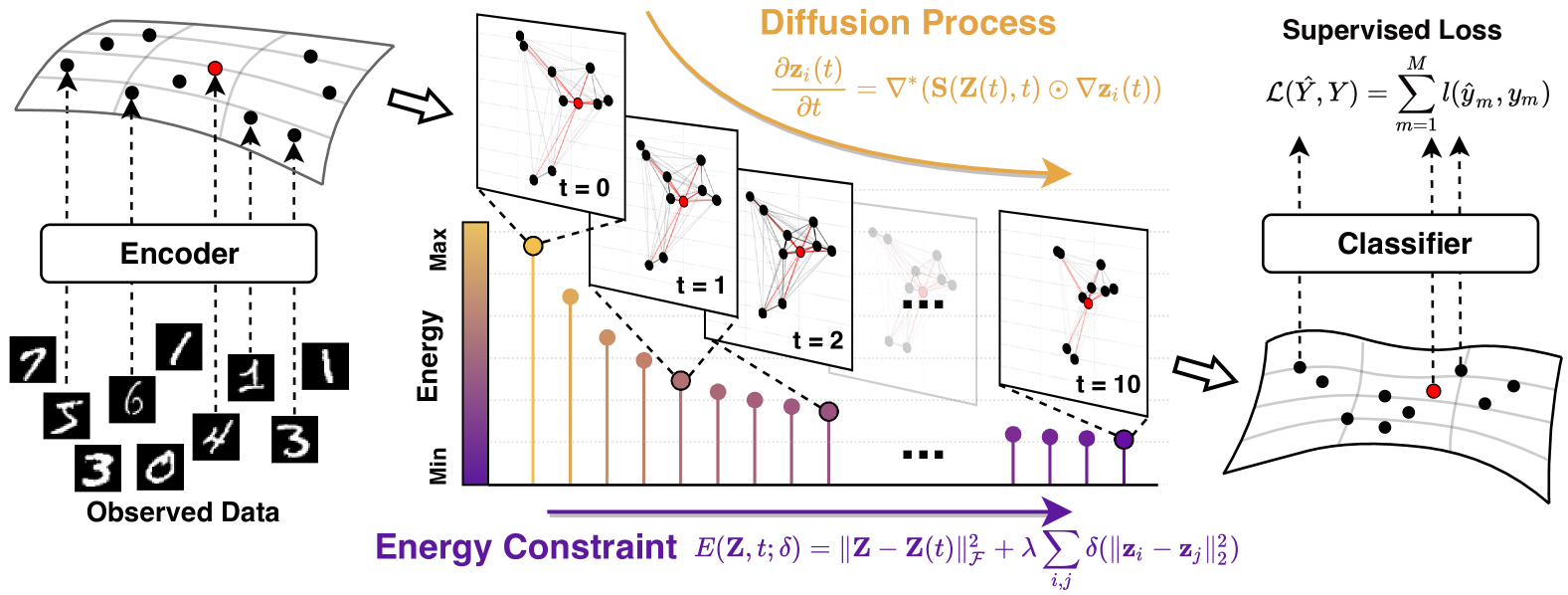
Learning representations for structured data with certain geometries (observed or unobserved) is a fundamental challenge, wherein message passing neural networks (MPNNs) have become a de facto class of model solutions. In this paper, we propose an energy-constrained diffusion model as a principled interpretable framework for understanding the mechanism of MPNNs and navigating novel architectural designs. The model, inspired by physical systems, combines the inductive bias of diffusion on manifolds with layer-wise constraints of energy minimization. As shown by our analysis, the diffusion operators have a one-to-one correspondence with the energy functions implicitly descended by the diffusion process, and the finite-difference iteration for solving the energy-constrained diffusion system induces the propagation layers of various types of MPNNs operated on observed or latent structures. On top of these findings, we devise a new class of neural message passing models, dubbed as diffusion-inspired Transformers, whose global attention layers are induced by the principled energy-constrained diffusion. Across diverse datasets ranging from real-world networks to images and physical particles, we show that the new model can yield promising performance for cases where the data structures are observed (as a graph), partially observed or completely unobserved.
Read more9/17/2024

0
Bundle Neural Networks for message diffusion on graphs
Jacob Bamberger, Federico Barbero, Xiaowen Dong, Michael Bronstein
The dominant paradigm for learning on graph-structured data is message passing. Despite being a strong inductive bias, the local message passing mechanism suffers from pathological issues such as over-smoothing, over-squashing, and limited node-level expressivity. To address these limitations we propose Bundle Neural Networks (BuNN), a new type of GNN that operates via message diffusion over flat vector bundles - structures analogous to connections on Riemannian manifolds that augment the graph by assigning to each node a vector space and an orthogonal map. A BuNN layer evolves the features according to a diffusion-type partial differential equation. When discretized, BuNNs are a special case of Sheaf Neural Networks (SNNs), a recently proposed MPNN capable of mitigating over-smoothing. The continuous nature of message diffusion enables BuNNs to operate on larger scales of the graph and, therefore, to mitigate over-squashing. Finally, we prove that BuNN can approximate any feature transformation over nodes on any (potentially infinite) family of graphs given injective positional encodings, resulting in universal node-level expressivity. We support our theory via synthetic experiments and showcase the strong empirical performance of BuNNs over a range of real-world tasks, achieving state-of-the-art results on several standard benchmarks in transductive and inductive settings.
Read more5/27/2024

0
A Theoretical Formulation of Many-body Message Passing Neural Networks
Jiatong Han
We present many-body Message Passing Neural Network (MPNN) framework that models higher-order node interactions ($ge 2$ nodes). We model higher-order terms as tree-shaped motifs, comprising a central node with its neighborhood, and apply localized spectral filters on motif Laplacian, weighted by global edge Ricci curvatures. We prove our formulation is invariant to neighbor node permutation, derive its sensitivity bound, and bound the range of learned graph potential. We run regression on graph energies to demonstrate that it scales well with deeper and wider network topology, and run classification on synthetic graph datasets with heterophily and show its consistently high Dirichlet energy growth. We open-source our code at https://github.com/JThh/Many-Body-MPNN.
Read more7/17/2024

0
Probabilistic Graph Rewiring via Virtual Nodes
Chendi Qian, Andrei Manolache, Christopher Morris, Mathias Niepert
Message-passing graph neural networks (MPNNs) have emerged as a powerful paradigm for graph-based machine learning. Despite their effectiveness, MPNNs face challenges such as under-reaching and over-squashing, where limited receptive fields and structural bottlenecks hinder information flow in the graph. While graph transformers hold promise in addressing these issues, their scalability is limited due to quadratic complexity regarding the number of nodes, rendering them impractical for larger graphs. Here, we propose implicitly rewired message-passing neural networks (IPR-MPNNs), a novel approach that integrates implicit probabilistic graph rewiring into MPNNs. By introducing a small number of virtual nodes, i.e., adding additional nodes to a given graph and connecting them to existing nodes, in a differentiable, end-to-end manner, IPR-MPNNs enable long-distance message propagation, circumventing quadratic complexity. Theoretically, we demonstrate that IPR-MPNNs surpass the expressiveness of traditional MPNNs. Empirically, we validate our approach by showcasing its ability to mitigate under-reaching and over-squashing effects, achieving state-of-the-art performance across multiple graph datasets. Notably, IPR-MPNNs outperform graph transformers while maintaining significantly faster computational efficiency.
Read more6/10/2024