NeurLZ: On Systematically Enhancing Lossy Compression Performance for Scientific Data based on Neural Learning with Error Control

0

Sign in to get full access
Overview
- The paper presents NeurLZ, a novel lossy compression approach for scientific data that leverages error-controlled neural learning to enhance compression performance.
- NeurLZ combines traditional lossless compression with machine learning-based models to achieve higher compression ratios while maintaining high-fidelity detail retention.
- The key innovations include cross-field learning between different scientific domains, lightweight skipping models for fast inference, and an error-control mechanism to ensure the compressed data meets user-specified error tolerances.
Plain English Explanation
NeurLZ: Enhancing Lossy Compression for Scientific Data
Compressing large scientific datasets is a crucial challenge, as researchers need to balance file size with retaining important details. Traditional compression methods can significantly reduce file size, but they may also lose important information.
NeurLZ is a new approach that aims to solve this problem. It combines traditional lossless compression techniques with machine learning models to achieve higher compression ratios while preserving essential details. The key innovations include:
-
Cross-Field Learning: NeurLZ can leverage knowledge learned from compressing data in one scientific field to improve compression of data in another field. This allows the model to learn more efficient compression strategies.
-
Lightweight Skipping Models: NeurLZ uses compact machine learning models that can quickly identify and skip over areas of the data that don't need detailed compression, speeding up the overall compression process.
-
Error Control: NeurLZ includes mechanisms to ensure the compressed data meets user-specified error tolerances, so researchers can control the balance between file size and data fidelity.
By incorporating these techniques, NeurLZ is able to achieve higher compression ratios than traditional methods while retaining important details in the compressed scientific data.
Technical Explanation
The key innovations in the NeurLZ approach include:
-
Cross-Field Learning: NeurLZ leverages knowledge learned from compressing data in one scientific domain to improve compression performance on data from a different domain. This cross-field learning allows the model to develop more generalizable and efficient compression strategies.
-
Lightweight Skipping Models: NeurLZ employs compact neural network models that can quickly identify and skip over areas of the data that don't require detailed compression. This "skipping" mechanism accelerates the overall compression process without sacrificing quality.
-
Error-Controlled Compression: NeurLZ includes an error control mechanism that ensures the compressed data meets user-specified error tolerances. This allows researchers to fine-tune the balance between compression ratio and data fidelity to suit their needs.
The authors evaluated NeurLZ on a variety of scientific datasets across different domains, including climate, physics, and astronomy. The results demonstrate that NeurLZ can achieve significantly higher compression ratios compared to traditional methods, while maintaining high-fidelity detail retention within user-specified error bounds.
Critical Analysis
The authors of the NeurLZ paper have made a compelling case for their approach to enhancing lossy compression performance for scientific data. The key strengths of the work include the innovative cross-field learning, lightweight skipping models, and error control mechanisms, which collectively address important challenges in scientific data compression.
However, the paper also acknowledges some limitations and areas for future research. For example, the authors note that the current implementation of NeurLZ may not be optimal for real-time or streaming compression scenarios, as the model training and setup process can be computationally intensive. Additionally, the paper suggests that further research is needed to explore the potential of NeurLZ for compressing high-dimensional or time-series scientific data.
Another potential area for improvement could be to investigate the generalizability of the cross-field learning approach. While the results demonstrate the benefits of leveraging knowledge across different scientific domains, it would be valuable to understand the limits of this technique and how it might scale to a broader range of data types and domains.
Overall, the NeurLZ paper presents a promising new direction for enhancing lossy compression of scientific data, and the authors have highlighted several interesting avenues for future research to further expand the capabilities and applicability of their approach.
Conclusion
NeurLZ: Enhancing Lossy Compression for Scientific Data
The NeurLZ compression approach represents a significant advancement in the field of lossy compression for scientific data. By combining traditional lossless compression techniques with novel machine learning models, the authors have developed a system that can achieve higher compression ratios while maintaining high-fidelity detail retention, as controlled by user-specified error tolerances.
The key innovations of NeurLZ, including cross-field learning, lightweight skipping models, and error control, address critical challenges in scientific data compression and pave the way for more efficient storage and transmission of large-scale datasets. As scientific research continues to generate vast amounts of data, tools like NeurLZ will become increasingly valuable for researchers and data scientists across a wide range of disciplines.
While the paper highlights some areas for further research and improvement, the NeurLZ framework represents an important step forward in the quest to balance file size and data fidelity for scientific data compression.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeurLZ: On Systematically Enhancing Lossy Compression Performance for Scientific Data based on Neural Learning with Error Control
Wenqi Jia, Youyuan Liu, Zhewen Hu, Jinzhen Wang, Boyuan Zhang, Wei Niu, Junzhou Huang, Stavros Kalafatis, Sian Jin, Miao Yin
Large-scale scientific simulations generate massive datasets that pose significant challenges for storage and I/O. While traditional lossy compression techniques can improve performance, balancing compression ratio, data quality, and throughput remains difficult. To address this, we propose NeurLZ, a novel cross-field learning-based and error-controlled compression framework for scientific data. By integrating skipping DNN models, cross-field learning, and error control, our framework aims to substantially enhance lossy compression performance. Our contributions are three-fold: (1) We design a lightweight skipping model to provide high-fidelity detail retention, further improving prediction accuracy. (2) We adopt a cross-field learning approach to significantly improve data prediction accuracy, resulting in a substantially improved compression ratio. (3) We develop an error control approach to provide strict error bounds according to user requirements. We evaluated NeurLZ on several real-world HPC application datasets, including Nyx (cosmological simulation), Miranda (large turbulence simulation), and Hurricane (weather simulation). Experiments demonstrate that our framework achieves up to a 90% relative reduction in bit rate under the same data distortion, compared to the best existing approach.
Read more9/11/2024

0
GWLZ: A Group-wise Learning-based Lossy Compression Framework for Scientific Data
Wenqi Jia, Sian Jin, Jinzhen Wang, Wei Niu, Dingwen Tao, Miao Yin
The rapid expansion of computational capabilities and the ever-growing scale of modern HPC systems present formidable challenges in managing exascale scientific data. Faced with such vast datasets, traditional lossless compression techniques prove insufficient in reducing data size to a manageable level while preserving all information intact. In response, researchers have turned to error-bounded lossy compression methods, which offer a balance between data size reduction and information retention. However, despite their utility, these compressors employing conventional techniques struggle with limited reconstruction quality. To address this issue, we draw inspiration from recent advancements in deep learning and propose GWLZ, a novel group-wise learning-based lossy compression framework with multiple lightweight learnable enhancer models. Leveraging a group of neural networks, GWLZ significantly enhances the decompressed data reconstruction quality with negligible impact on the compression efficiency. Experimental results on different fields from the Nyx dataset demonstrate remarkable improvements by GWLZ, achieving up to 20% quality enhancements with negligible overhead as low as 0.0003x.
Read more4/23/2024
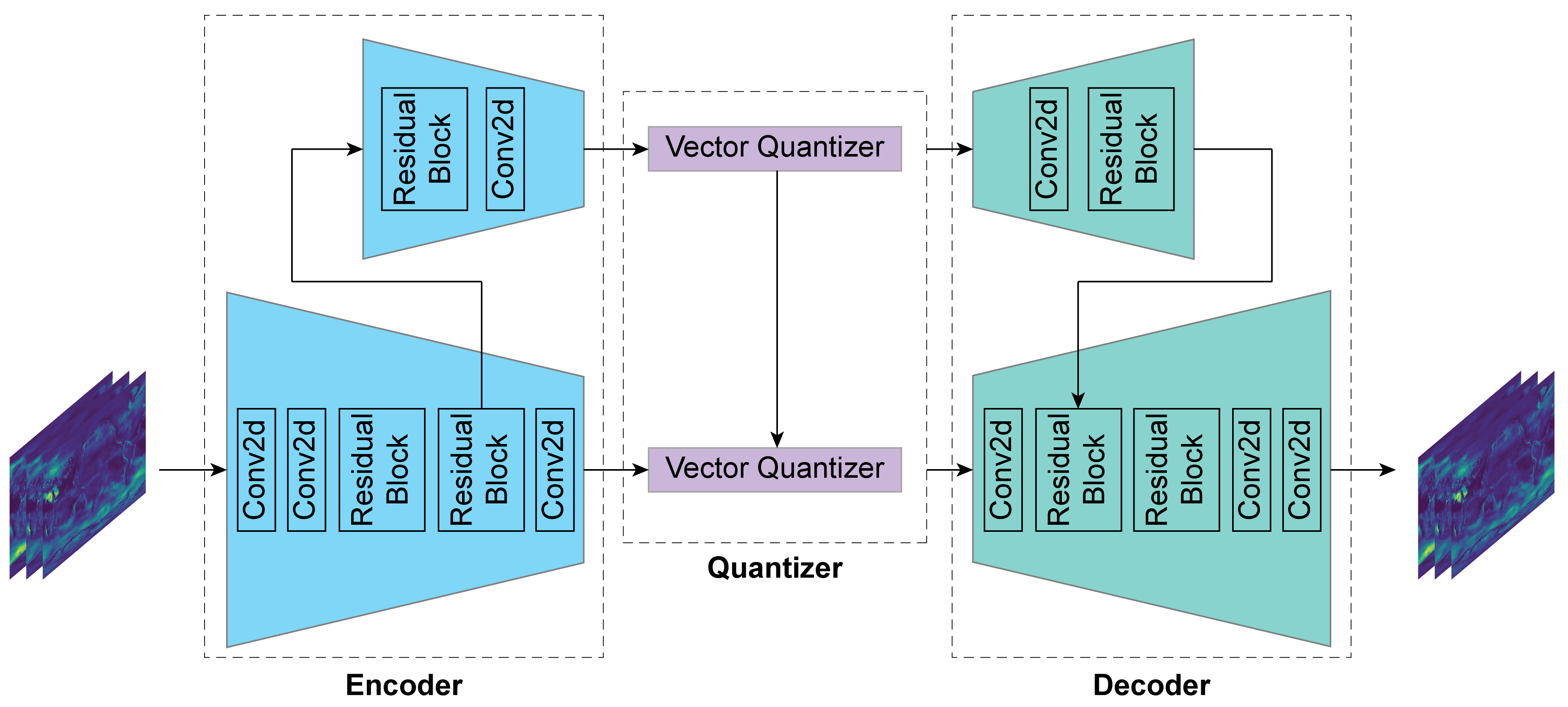
0
Hierarchical Autoencoder-based Lossy Compression for Large-scale High-resolution Scientific Data
Hieu Le, Jian Tao
Lossy compression has become an important technique to reduce data size in many domains. This type of compression is especially valuable for large-scale scientific data, whose size ranges up to several petabytes. Although Autoencoder-based models have been successfully leveraged to compress images and videos, such neural networks have not widely gained attention in the scientific data domain. Our work presents a neural network that not only significantly compresses large-scale scientific data, but also maintains high reconstruction quality. The proposed model is tested with scientific benchmark data available publicly and applied to a large-scale high-resolution climate modeling data set. Our model achieves a compression ratio of 140 on several benchmark data sets without compromising the reconstruction quality. 2D simulation data from the High-Resolution Community Earth System Model (CESM) Version 1.3 over 500 years are also being compressed with a compression ratio of 200 while the reconstruction error is negligible for scientific analysis.
Read more5/8/2024

0
A Survey on Error-Bounded Lossy Compression for Scientific Datasets
Sheng Di, Jinyang Liu, Kai Zhao, Xin Liang, Robert Underwood, Zhaorui Zhang, Milan Shah, Yafan Huang, Jiajun Huang, Xiaodong Yu, Congrong Ren, Hanqi Guo, Grant Wilkins, Dingwen Tao, Jiannan Tian, Sian Jin, Zizhe Jian, Daoce Wang, MD Hasanur Rahman, Boyuan Zhang, Jon C. Calhoun, Guanpeng Li, Kazutomo Yoshii, Khalid Ayed Alharthi, Franck Cappello
Error-bounded lossy compression has been effective in significantly reducing the data storage/transfer burden while preserving the reconstructed data fidelity very well. Many error-bounded lossy compressors have been developed for a wide range of parallel and distributed use cases for years. These lossy compressors are designed with distinct compression models and design principles, such that each of them features particular pros and cons. In this paper we provide a comprehensive survey of emerging error-bounded lossy compression techniques for different use cases each involving big data to process. The key contribution is fourfold. (1) We summarize an insightful taxonomy of lossy compression into 6 classic compression models. (2) We provide a comprehensive survey of 10+ commonly used compression components/modules used in error-bounded lossy compressors. (3) We provide a comprehensive survey of 10+ state-of-the-art error-bounded lossy compressors as well as how they combine the various compression modules in their designs. (4) We provide a comprehensive survey of the lossy compression for 10+ modern scientific applications and use-cases. We believe this survey is useful to multiple communities including scientific applications, high-performance computing, lossy compression, and big data.
Read more4/4/2024