NewsQs: Multi-Source Question Generation for the Inquiring Mind
2402.18479
0
0

Abstract
We present NewsQs (news-cues), a dataset that provides question-answer pairs for multiple news documents. To create NewsQs, we augment a traditional multi-document summarization dataset with questions automatically generated by a T5-Large model fine-tuned on FAQ-style news articles from the News On the Web corpus. We show that fine-tuning a model with control codes produces questions that are judged acceptable more often than the same model without them as measured through human evaluation. We use a QNLI model with high correlation with human annotations to filter our data. We release our final dataset of high-quality questions, answers, and document clusters as a resource for future work in query-based multi-document summarization.
Create account to get full access
Overview
- This paper introduces NewsQs, a system for generating multi-source questions about news articles.
- NewsQs aims to help readers engage more deeply with news content by prompting them to think critically and ask their own questions.
- The system draws information from multiple related articles to generate diverse, open-ended questions that go beyond the content of a single source.
Plain English Explanation
NewsQs is a tool that can generate thought-provoking questions about news articles. The idea is to help readers dig deeper into the news and develop their own inquiring mindset, rather than just passively consuming information.
Typically, when reading a news article, readers might have various questions that come to mind - whether it's seeking clarification on a point, wondering about underlying causes, or imagining how the story might continue. NewsQs taps into this natural human curiosity by automatically generating a set of questions based on the article.
Importantly, NewsQs doesn't just ask questions about the specific content of a single article. Instead, it draws information from a wider set of related news sources to generate more diverse and open-ended questions. This encourages readers to make connections, consider different perspectives, and explore the broader context around a news story.
By engaging readers in this way, NewsQs aims to foster a more active, critical approach to news consumption. Rather than just absorbing information, readers are prompted to become inquiring minds - questioning, analyzing, and ultimately gaining a richer understanding of current events.
Technical Explanation
The core of the NewsQs system is a question generation model that leverages a multi-source, multi-task learning framework. The model is trained on a large corpus of news articles and related questions, allowing it to generate relevant and diverse questions for new input articles.
Specifically, the NewsQs model takes in a target news article along with a set of related articles on the same topic. It then uses a series of transformer-based neural networks to:
- Extract relevant information and context from the multi-source input.
- Generate diverse questions that go beyond the content of any single article.
- Rank the generated questions based on criteria like relevance, interestingness, and coverage of key information.
The researchers evaluate NewsQs on a variety of metrics, including the quality and diversity of the generated questions, as well as their ability to promote deeper engagement with the source material. The results demonstrate the effectiveness of the multi-source, multi-task approach in producing thought-provoking questions that can enhance the news reading experience.
Critical Analysis
The NewsQs paper makes a compelling case for the value of automatically generating questions to foster more active and critical news consumption. By drawing on multiple news sources, the system is able to produce questions that go beyond the surface-level details of a single article and encourage readers to think more deeply.
That said, the researchers acknowledge some limitations of their approach. For example, the quality and relevance of the generated questions are still imperfect and may require further refinement. Additionally, the current implementation is focused on textual news articles, but extending the system to handle other media formats like videos or podcasts could broaden its real-world applicability.
Another potential area for improvement is in personalizing the question generation to individual readers' interests and backgrounds. While the current multi-source approach aims for broad relevance, tailoring the questions to each user's unique informational needs and curiosities could make the system even more engaging and impactful.
Overall, the NewsQs framework represents an exciting step forward in developing AI-powered tools to enhance the news reading experience. By encouraging critical thinking and a more active, inquiring mindset, systems like this have the potential to improve news literacy and empower citizens to better navigate the complex information landscape.
Conclusion
The NewsQs paper introduces an innovative approach to generating thought-provoking questions about news articles. By leveraging multiple related sources, the system can produce diverse, open-ended questions that go beyond the content of a single article and prompt readers to think more critically.
While the current implementation has some limitations, the underlying concept of using AI to foster active, inquiring engagement with news content is highly promising. As news consumers increasingly navigate a complex and often overwhelming information ecosystem, tools like NewsQs could play a valuable role in cultivating the skills and mindset needed to be an informed and discerning citizen.
Looking ahead, further advancements in areas like personalization, multimodal question generation, and real-time adaptation could unlock even greater potential for systems like NewsQs to transform the way we consume and interact with news. Ultimately, by empowering readers to become active inquirers, this research carries important implications for the future of news literacy and democratic discourse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
SEMQA: Semi-Extractive Multi-Source Question Answering
Tal Schuster, Adam D. Lelkes, Haitian Sun, Jai Gupta, Jonathan Berant, William W. Cohen, Donald Metzler
0
0
Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
7/2/2024
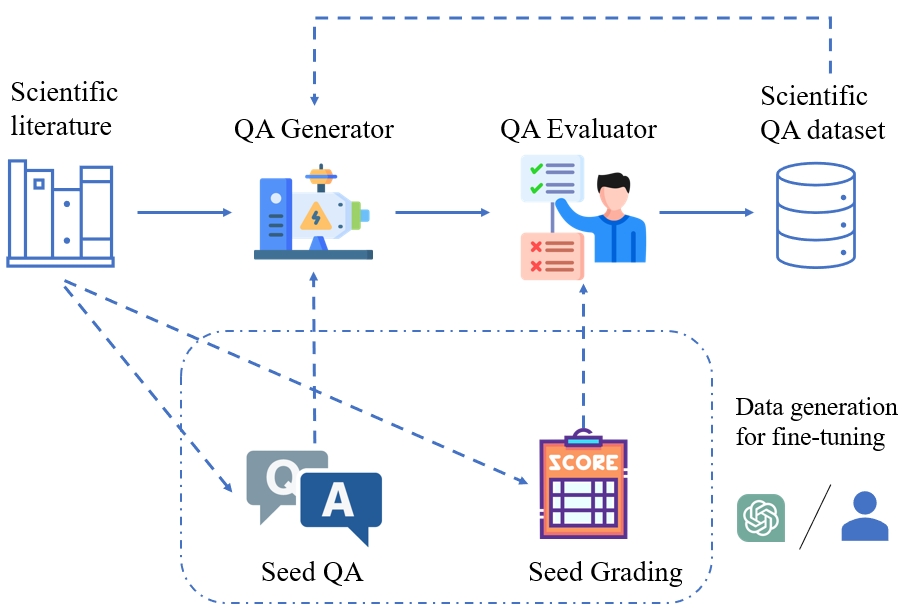
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Aswathy Ajith, Yixuan Liu, Ke Lu, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
0
0
The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
5/17/2024
👁️
TANQ: An open domain dataset of table answered questions
Mubashara Akhtar, Chenxi Pang, Andreea Marzoca, Yasemin Altun, Julian Martin Eisenschlos
0
0
Language models, potentially augmented with tool usage such as retrieval are becoming the go-to means of answering questions. Understanding and answering questions in real-world settings often requires retrieving information from different sources, processing and aggregating data to extract insights, and presenting complex findings in form of structured artifacts such as novel tables, charts, or infographics. In this paper, we introduce TANQ, the first open domain question answering dataset where the answers require building tables from information across multiple sources. We release the full source attribution for every cell in the resulting table and benchmark state-of-the-art language models in open, oracle, and closed book setups. Our best-performing baseline, GPT4 reaches an overall F1 score of 29.1, lagging behind human performance by 19.7 points. We analyse baselines' performance across different dataset attributes such as different skills required for this task, including multi-hop reasoning, math operations, and unit conversions. We further discuss common failures in model-generated answers, suggesting that TANQ is a complex task with many challenges ahead.
5/14/2024
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024