LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
2308.10390
0
0
💬
Abstract
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
Create account to get full access
Overview
- Researchers have found that while large language models (LLMs) perform well on many tasks, they struggle with multimodal functionalities, especially on the Spoken Question Answering (SQA) task which requires tight alignment and deep understanding between speech and text.
- To address this, the researchers curated the LibriSQA dataset, a free-form and open-ended collection of 107,000 SQA pairs covering various topics, including natural conversational formats and multiple-choice questions with answers and analysis.
- The researchers propose a lightweight, end-to-end framework to tackle the SQA task on LibriSQA, achieving significant results and demonstrating LLMs' ability to align and comprehend multimodal information.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a variety of tasks, from answering questions to generating text. However, the researchers found that these models still struggle when it comes to handling information from multiple sources, like speech and text.
To address this, the researchers created a new dataset called LibriSQA, which contains over 100,000 examples of people asking questions and getting answers, using both speech and text. This dataset covers a wide range of topics and includes natural conversations as well as multiple-choice questions with detailed explanations.
Using this dataset, the researchers developed a new framework - a kind of AI system - that can take speech and text inputs and answer questions about them. This framework was able to achieve impressive results, showing that LLMs can be trained to work with multimodal information, like speech and text together.
The researchers believe that their work paves the way for the development of LLMs that can truly understand and process information from multiple sources, just like humans can. This could lead to more natural and effective AI assistants, as well as new applications in fields like education and healthcare.
Technical Explanation
The researchers first curated the LibriSQA dataset, which consists of 107,000 spoken question-answering (SQA) pairs from the Librispeech corpus. The dataset includes two parts: Part I with natural conversational formats, and Part II with multiple-choice questions, answers, and analytical segments.
To tackle the SQA task on this dataset, the researchers propose a lightweight, end-to-end framework. By reforming automatic speech recognition (ASR) into the SQA format, the framework demonstrates its capability in handling both SQA and ASR tasks.
The key innovation of the framework is its ability to tightly align and deeply integrate speech and text features, which is crucial for effective multimodal understanding. The researchers' empirical findings show that their framework can significantly outperform existing speech-text LLMs on the LibriSQA dataset.
The researchers' work contributes to the growing body of research on developing versatile multimodal LLMs that can seamlessly process and comprehend information from different modalities, like speech and text. This could lead to more natural and effective AI systems that can better assist humans in a variety of tasks and scenarios.
Critical Analysis
The researchers have made a valuable contribution to the field of multimodal language understanding by curating the LibriSQA dataset and proposing a novel framework to tackle the SQA task. However, there are a few areas that could be addressed in future research:
-
Scalability: The proposed framework is described as "lightweight," but it's unclear how it would scale to larger, more complex datasets or real-world applications. Further research could explore ways to improve the framework's efficiency and robustness.
-
Generalization: The evaluation of the framework is limited to the LibriSQA dataset, which has a specific format and distribution. It would be beneficial to test the framework's performance on other SQA datasets or real-world scenarios to assess its generalization capabilities.
-
Multimodal Alignment: The researchers emphasize the importance of tight alignment and deep integration between speech and text features, but the specific mechanisms behind this alignment process are not fully explained. Deeper insights into the multimodal alignment techniques could help advance the field.
Overall, the researchers have made a valuable contribution to the field of multimodal language understanding, and their work serves as a promising foundation for future research in this area.
Conclusion
The researchers have addressed a critical challenge in the development of large language models (LLMs) by curating the LibriSQA dataset and proposing a lightweight, end-to-end framework to tackle the spoken question answering (SQA) task. Their work demonstrates the potential for LLMs to align and comprehend multimodal information, paving the way for the creation of more versatile and effective AI systems that can seamlessly process and understand speech and text together.
The implications of this research span various domains, from more natural and intuitive AI assistants to innovative applications in education, healthcare, and beyond. By continuing to push the boundaries of multimodal language understanding, researchers can unlock new possibilities for how humans and machines interact and collaborate, ultimately leading to more meaningful and impactful technological advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
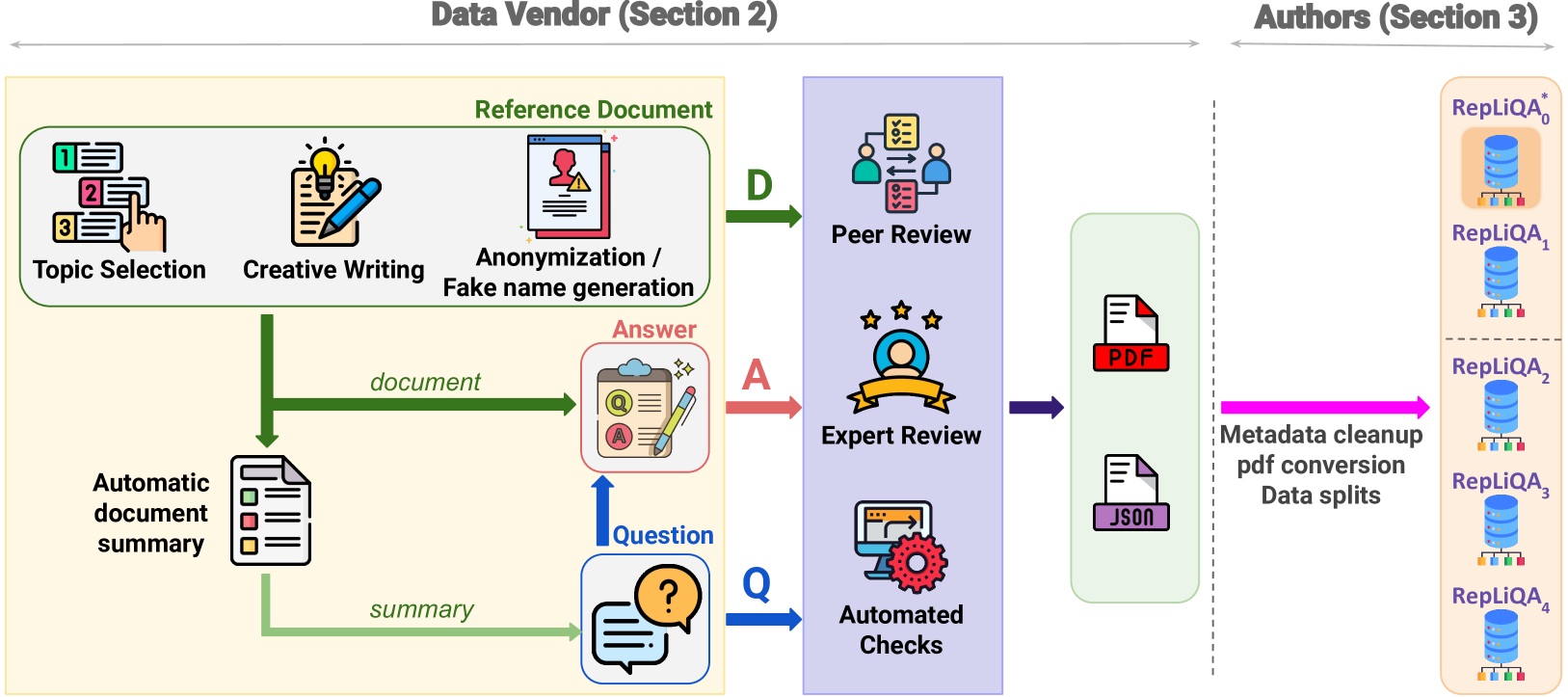
RepLiQA: A Question-Answering Dataset for Benchmarking LLMs on Unseen Reference Content
Joao Monteiro, Pierre-Andre Noel, Etienne Marcotte, Sai Rajeswar, Valentina Zantedeschi, David Vazquez, Nicolas Chapados, Christopher Pal, Perouz Taslakian
0
0
Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data includes encyclopedic documents that harbor a vast amount of general knowledge (e.g., Wikipedia) but also potentially overlap with benchmark datasets used for evaluating LLMs. Consequently, evaluating models on test splits that might have leaked into the training set is prone to misleading conclusions. To foster sound evaluation of language models, we introduce a new test dataset named RepLiQA, suited for question-answering and topic retrieval tasks. RepLiQA is a collection of five splits of test sets, four of which have not been released to the internet or exposed to LLM APIs prior to this publication. Each sample in RepLiQA comprises (1) a reference document crafted by a human annotator and depicting an imaginary scenario (e.g., a news article) absent from the internet; (2) a question about the document's topic; (3) a ground-truth answer derived directly from the information in the document; and (4) the paragraph extracted from the reference document containing the answer. As such, accurate answers can only be generated if a model can find relevant content within the provided document. We run a large-scale benchmark comprising several state-of-the-art LLMs to uncover differences in performance across models of various types and sizes in a context-conditional language modeling setting. Released splits of RepLiQA can be found here: https://huggingface.co/datasets/ServiceNow/repliqa.
6/18/2024
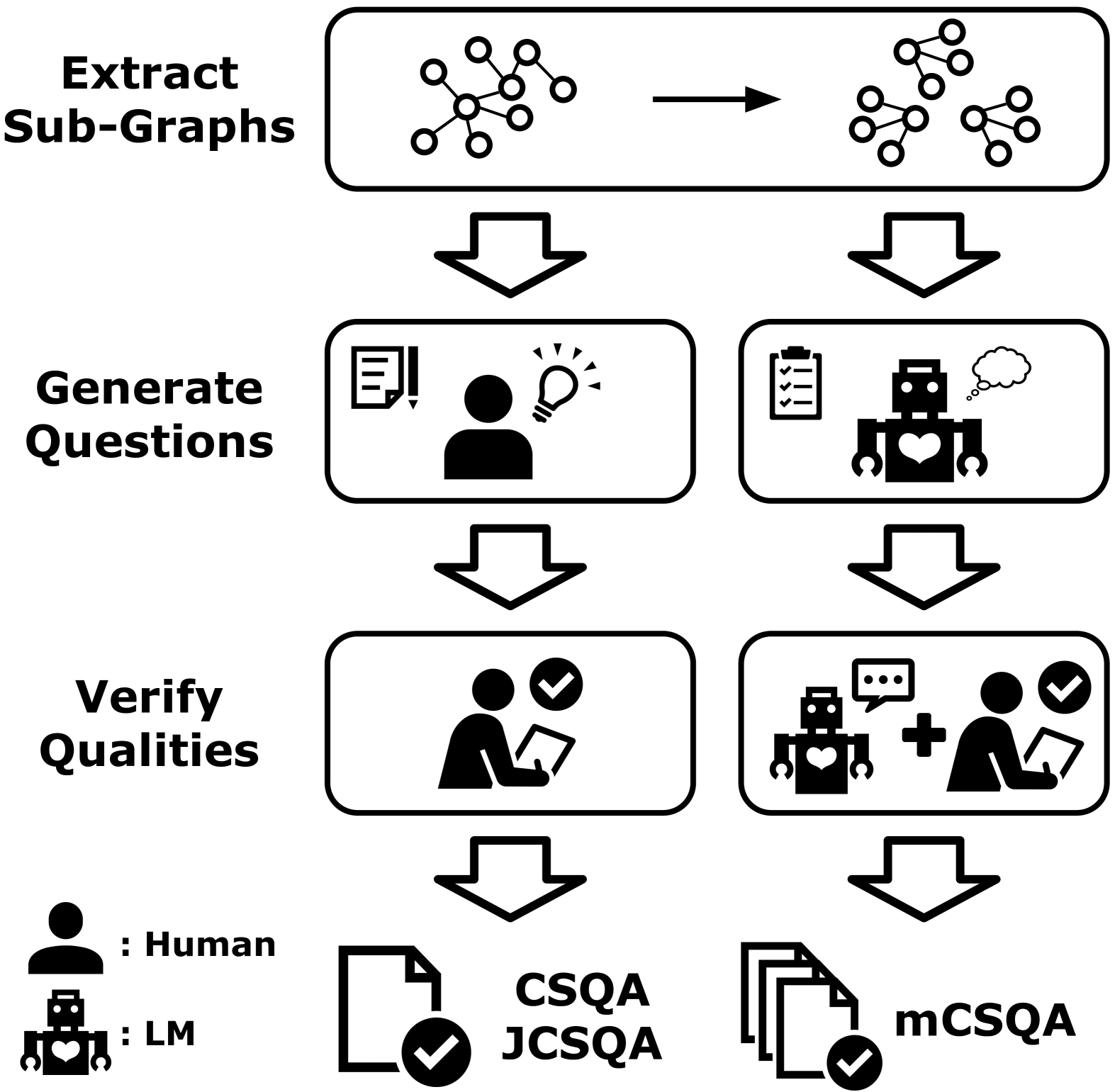
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024
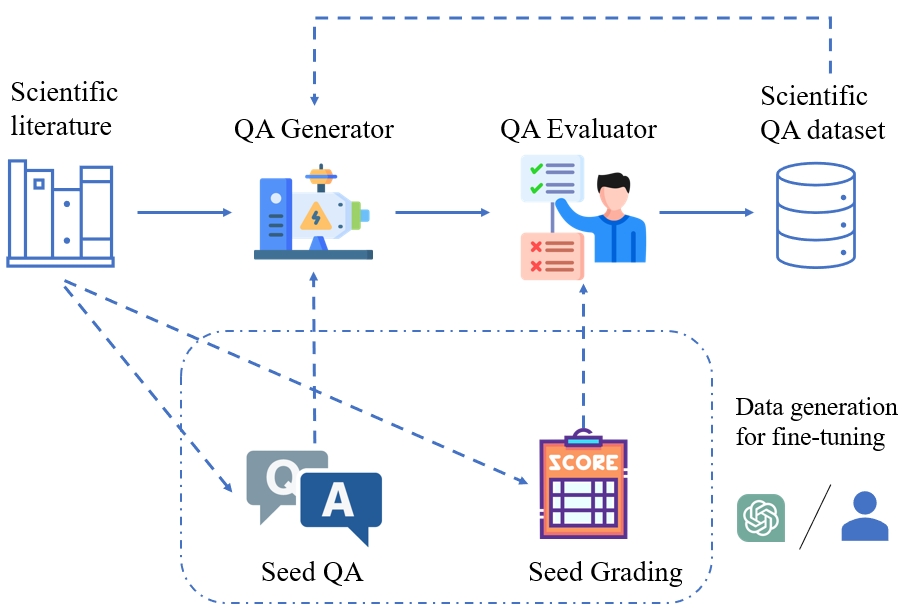
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Aswathy Ajith, Yixuan Liu, Ke Lu, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
0
0
The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
5/17/2024