NIR-Assisted Image Denoising: A Selective Fusion Approach and A Real-World Benchmark Datase
2404.08514
0
0

Abstract
Despite the significant progress in image denoising, it is still challenging to restore fine-scale details while removing noise, especially in extremely low-light environments. Leveraging near-infrared (NIR) images to assist visible RGB image denoising shows the potential to address this issue, becoming a promising technology. Nonetheless, existing works still struggle with taking advantage of NIR information effectively for real-world image denoising, due to the content inconsistency between NIR-RGB images and the scarcity of real-world paired datasets. To alleviate the problem, we propose an efficient Selective Fusion Module (SFM), which can be plug-and-played into the advanced denoising networks to merge the deep NIR-RGB features. Specifically, we sequentially perform the global and local modulation for NIR and RGB features, and then integrate the two modulated features. Furthermore, we present a Real-world NIR-Assisted Image Denoising (Real-NAID) dataset, which covers diverse scenarios as well as various noise levels. Extensive experiments on both synthetic and our real-world datasets demonstrate that the proposed method achieves better results than state-of-the-art ones. The dataset, codes, and pre-trained models will be publicly available at https://github.com/ronjonxu/NAID.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This research paper presents a novel approach for denoising images using Near-Infrared (NIR) information as an additional input, along with a real-world benchmark dataset for evaluating NIR-assisted image denoising techniques.
• The proposed method, called VIFNet, involves a selective fusion strategy that effectively combines the visible and NIR information to produce high-quality denoised images.
• The authors also introduce a new dataset, called NITEDR, which consists of real-world image pairs captured under various lighting conditions, including low-light and rainy scenarios, to benchmark the performance of NIR-assisted denoising algorithms.
Plain English Explanation
The research paper introduces a new way to improve the quality of noisy images using additional information from Near-Infrared (NIR) cameras. Normally, when an image is taken in low-light or poor weather conditions, it can become blurry and grainy. The proposed VIFNet method combines the visible light information from the regular camera with the infrared information from the NIR camera to create a cleaner, sharper image.
The key idea is to selectively fuse the visible and NIR data in a smart way, so that the strengths of each type of information can be leveraged to improve the final result. For example, the NIR camera may be better at capturing details in the shadows, while the visible camera is better at capturing color and texture.
To test this approach, the researchers also created a new dataset called NITEDR, which contains real-world image pairs taken in various challenging conditions, like low light and rain. This dataset can be used to evaluate and compare different denoising techniques that use NIR information.
Technical Explanation
The paper proposes a novel end-to-end framework called VIFNet for NIR-assisted image denoising. The network consists of two parallel branches, one for processing the visible image and one for the NIR image. These branches are then selectively fused using a attention-based mechanism to combine the complementary information from both modalities.
The authors also introduce a new real-world benchmark dataset called NITEDR, which includes image pairs captured under various challenging conditions, such as low-light and rainy scenarios. This dataset is designed to evaluate the performance of NIR-assisted denoising algorithms in realistic settings, going beyond traditional synthetic noise models.
Experiments on the proposed NITEDR dataset show that the VIFNet model outperforms state-of-the-art denoising methods, demonstrating the benefits of leveraging NIR information for image enhancement in real-world conditions.
Critical Analysis
The research presented in this paper makes several important contributions to the field of image denoising. The VIFNet framework provides a novel and effective way to fuse visible and NIR information for improved denoising performance, going beyond previous approaches that simply concatenate the two modalities.
The introduction of the NITEDR dataset is also a significant contribution, as it provides a more realistic and challenging benchmark for evaluating denoising algorithms in real-world conditions, compared to synthetic noise models.
However, the paper could benefit from a more in-depth discussion of the limitations of the proposed approach. For example, the authors do not address how the VIFNet model would perform in scenarios with severe sensor misalignment or when the visible and NIR images are not perfectly registered. Additionally, the NITEDR dataset, while valuable, may not capture the full range of real-world challenges faced by denoising algorithms.
Further research could also explore the potential of hybrid training techniques or implicit multi-spectral fusion approaches to improve the robustness and generalization of NIR-assisted denoising methods.
Conclusion
This research paper presents a novel approach for NIR-assisted image denoising, called VIFNet, along with a new real-world benchmark dataset called NITEDR. The proposed method effectively combines visible and NIR information to produce high-quality denoised images, outperforming state-of-the-art denoising techniques in realistic settings.
The introduction of the NITEDR dataset is a significant contribution, as it provides a more challenging and representative benchmark for evaluating the performance of NIR-assisted denoising algorithms. The findings of this research have important implications for various applications, such as low-light photography, surveillance, and autonomous driving, where high-quality image denoising is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
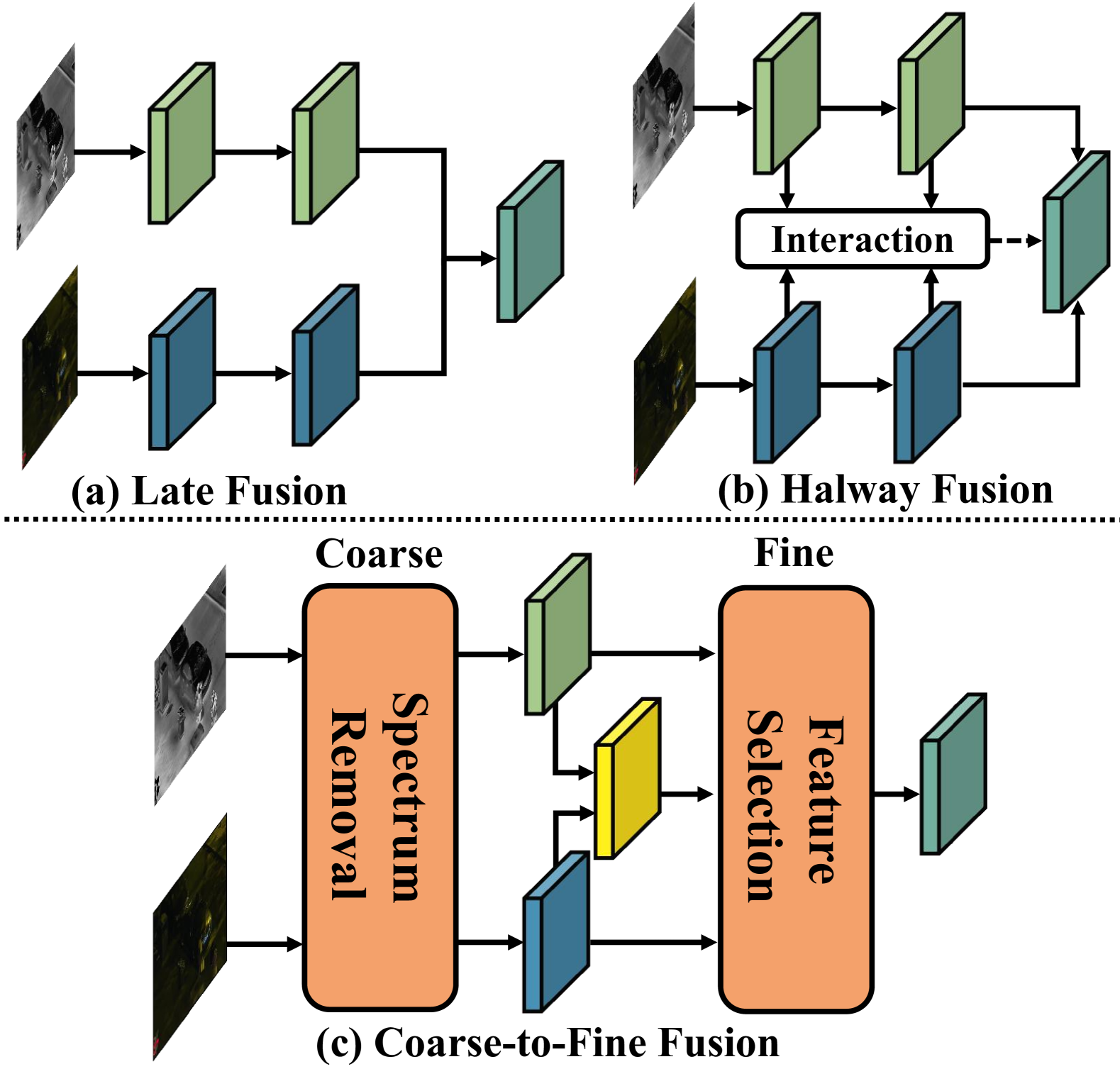
Removal and Selection: Improving RGB-Infrared Object Detection via Coarse-to-Fine Fusion
Tianyi Zhao, Maoxun Yuan, Feng Jiang, Nan Wang, Xingxing Wei
0
0
Object detection in visible (RGB) and infrared (IR) images has been widely applied in recent years. Leveraging the complementary characteristics of RGB and IR images, the object detector provides reliable and robust object localization from day to night. Most existing fusion strategies directly input RGB and IR images into deep neural networks, leading to inferior detection performance. However, the RGB and IR features have modality-specific noise, these strategies will exacerbate the fused features along with the propagation. Inspired by the mechanism of the human brain processing multimodal information, in this paper, we introduce a new coarse-to-fine perspective to purify and fuse two modality features. Specifically, following this perspective, we design a Redundant Spectrum Removal module to coarsely remove interfering information within each modality and a Dynamic Feature Selection module to finely select the desired features for feature fusion. To verify the effectiveness of the coarse-to-fine fusion strategy, we construct a new object detector called the Removal and Selection Detector (RSDet). Extensive experiments on three RGB-IR object detection datasets verify the superior performance of our method.
5/8/2024

VIFNet: An End-to-end Visible-Infrared Fusion Network for Image Dehazing
Meng Yu, Te Cui, Haoyang Lu, Yufeng Yue
0
0
Image dehazing poses significant challenges in environmental perception. Recent research mainly focus on deep learning-based methods with single modality, while they may result in severe information loss especially in dense-haze scenarios. The infrared image exhibits robustness to the haze, however, existing methods have primarily treated the infrared modality as auxiliary information, failing to fully explore its rich information in dehazing. To address this challenge, the key insight of this study is to design a visible-infrared fusion network for image dehazing. In particular, we propose a multi-scale Deep Structure Feature Extraction (DSFE) module, which incorporates the Channel-Pixel Attention Block (CPAB) to restore more spatial and marginal information within the deep structural features. Additionally, we introduce an inconsistency weighted fusion strategy to merge the two modalities by leveraging the more reliable information. To validate this, we construct a visible-infrared multimodal dataset called AirSim-VID based on the AirSim simulation platform. Extensive experiments performed on challenging real and simulated image datasets demonstrate that VIFNet can outperform many state-of-the-art competing methods. The code and dataset are available at https://github.com/mengyu212/VIFNet_dehazing.
4/12/2024
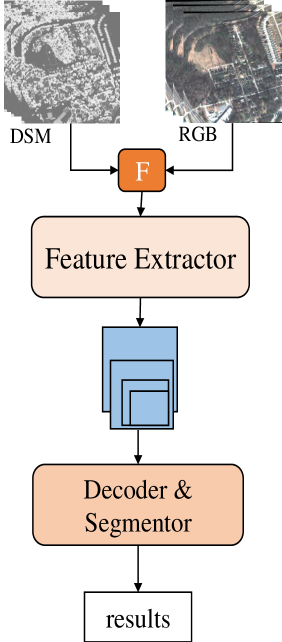
LMFNet: An Efficient Multimodal Fusion Approach for Semantic Segmentation in High-Resolution Remote Sensing
Tong Wang, Guanzhou Chen, Xiaodong Zhang, Chenxi Liu, Xiaoliang Tan, Jiaqi Wang, Chanjuan He, Wenlin Zhou
0
0
Despite the rapid evolution of semantic segmentation for land cover classification in high-resolution remote sensing imagery, integrating multiple data modalities such as Digital Surface Model (DSM), RGB, and Near-infrared (NIR) remains a challenge. Current methods often process only two types of data, missing out on the rich information that additional modalities can provide. Addressing this gap, we propose a novel textbf{L}ightweight textbf{M}ultimodal data textbf{F}usion textbf{Net}work (LMFNet) to accomplish the tasks of fusion and semantic segmentation of multimodal remote sensing images. LMFNet uniquely accommodates various data types simultaneously, including RGB, NirRG, and DSM, through a weight-sharing, multi-branch vision transformer that minimizes parameter count while ensuring robust feature extraction. Our proposed multimodal fusion module integrates a textit{Multimodal Feature Fusion Reconstruction Layer} and textit{Multimodal Feature Self-Attention Fusion Layer}, which can reconstruct and fuse multimodal features. Extensive testing on public datasets such as US3D, ISPRS Potsdam, and ISPRS Vaihingen demonstrates the effectiveness of LMFNet. Specifically, it achieves a mean Intersection over Union ($mIoU$) of 85.09% on the US3D dataset, marking a significant improvement over existing methods. Compared to unimodal approaches, LMFNet shows a 10% enhancement in $mIoU$ with only a 0.5M increase in parameter count. Furthermore, against bimodal methods, our approach with trilateral inputs enhances $mIoU$ by 0.46 percentage points.
4/23/2024
🖼️
UniRGB-IR: A Unified Framework for Visible-Infrared Downstream Tasks via Adapter Tuning
Maoxun Yuan, Bo Cui, Tianyi Zhao, Xingxing Wei
0
0
Semantic analysis on visible (RGB) and infrared (IR) images has gained attention for its ability to be more accurate and robust under low-illumination and complex weather conditions. Due to the lack of pre-trained foundation models on the large-scale infrared image datasets, existing methods prefer to design task-specific frameworks and directly fine-tune them with pre-trained foundation models on their RGB-IR semantic relevance datasets, which results in poor scalability and limited generalization. In this work, we propose a scalable and efficient framework called UniRGB-IR to unify RGB-IR downstream tasks, in which a novel adapter is developed to efficiently introduce richer RGB-IR features into the pre-trained RGB-based foundation model. Specifically, our framework consists of a vision transformer (ViT) foundation model, a Multi-modal Feature Pool (MFP) module and a Supplementary Feature Injector (SFI) module. The MFP and SFI modules cooperate with each other as an adpater to effectively complement the ViT features with the contextual multi-scale features. During training process, we freeze the entire foundation model to inherit prior knowledge and only optimize the MFP and SFI modules. Furthermore, to verify the effectiveness of our framework, we utilize the ViT-Base as the pre-trained foundation model to perform extensive experiments. Experimental results on various RGB-IR downstream tasks demonstrate that our method can achieve state-of-the-art performance. The source code and results are available at https://github.com/PoTsui99/UniRGB-IR.git.
4/29/2024