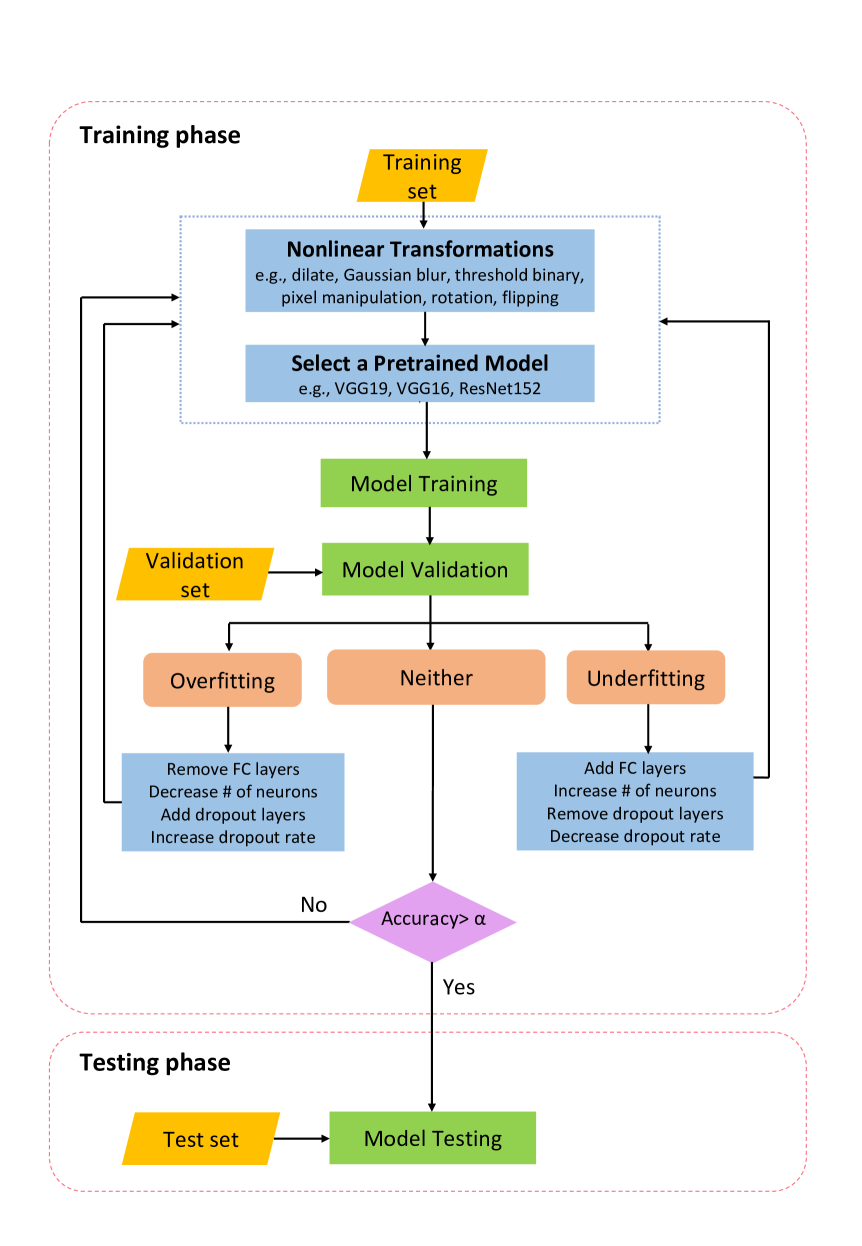
Nonlinear Transformations Against Unlearnable Datasets
2406.02883
0
0
Abstract
Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called unlearnable examples, are prevented learning by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.
Create account to get full access
Overview
- This paper explores nonlinear transformations as a way to create "unlearnable datasets" - datasets that are difficult or impossible for machine learning models to learn from.
- The authors propose a novel technique to generate "ungeneralizable examples" by applying nonlinear transformations to existing datasets.
- They demonstrate this approach can be used to "corrupt convolution-based unlearnable datasets" and "probe unlearned diffusion models with transferable adversarial attacks".
- The paper also introduces a "transpose attack" that can be used to "steal" datasets from bidirectional training models.
Plain English Explanation
This research focuses on creating datasets that are difficult for machine learning models to learn from. The key idea is to apply nonlinear transformations to existing datasets, which can make them effectively "unlearnable" - the models struggle to extract useful patterns from the data.
The researchers demonstrate several ways to apply this approach. For example, they show how nonlinear transformations can be used to corrupt datasets that are already designed to be unlearnable by convolution-based models. They also explore using these transformations to probe diffusion models, which are a type of AI that generates new data, and find that the transformed datasets can be used to attack these models in a way that transfers between different models.
Additionally, the paper introduces a new type of attack called a "transpose attack" that can be used to steal datasets from certain machine learning models that are trained bidirectionally (in both directions).
The main significance of this work is that it provides new tools for making datasets that are resistant to machine learning. This could be useful for tasks like privacy protection, where you want to share data without letting the receiving model learn too much about the original data. It also raises interesting questions about the vulnerabilities of different AI models and the potential for adversarial attacks in machine learning.
Technical Explanation
The core idea behind this paper is to leverage nonlinear transformations as a way to create "unlearnable datasets" - datasets that are difficult or impossible for machine learning models to learn from.
The authors propose a general technique where they start with an existing dataset, apply a series of nonlinear transformations to it, and then use the transformed dataset as input to train machine learning models. Their experiments show that this approach can lead to "ungeneralizable examples" - data points that models struggle to learn patterns from, even when they are trained on the full transformed dataset.
They demonstrate the effectiveness of this technique in several specific scenarios. First, they show how it can be used to "corrupt convolution-based unlearnable datasets" - datasets that were already designed to be difficult for convolutional neural networks. Applying nonlinear transformations further degrades the model's ability to learn.
The authors also explore using transformed datasets to "probe unlearned diffusion models with transferable adversarial attacks". Diffusion models are a type of generative AI that learns to generate new data. The transformed datasets are used to find vulnerabilities in these models that can be exploited across different diffusion models.
Finally, the paper introduces a "transpose attack" - a technique for "stealing" datasets from machine learning models that are trained bidirectionally (in both the forward and reverse direction). This attack works by exploiting the symmetric nature of the bidirectional training process.
Critical Analysis
The research presented in this paper offers a novel approach to creating "unlearnable" datasets using nonlinear transformations. This is an interesting technique with potential applications in areas like privacy-preserving data sharing and adversarial machine learning research.
One limitation of the work is that the specific nonlinear transformations used in the experiments are not always fully explained. More details on the choice and design of these transformations would help readers understand the method more deeply.
Additionally, the paper does not provide a comprehensive analysis of the limitations or failure modes of the proposed approach. For example, it would be worth exploring whether there are certain types of models or datasets that are more resistant to these nonlinear transformations, or whether the transformed datasets can still be learned from using alternative training techniques.
The "transpose attack" introduced in the paper is a clever idea, but its broader applicability and potential for misuse should be carefully considered. While the attack demonstrates an interesting vulnerability in bidirectional training, the authors do not discuss potential safeguards or mitigations that could be developed to protect against such attacks.
Overall, this paper makes a valuable contribution to the understanding of machine learning vulnerabilities and the pursuit of "unlearnable" datasets. However, further research is needed to fully explore the implications and limitations of this approach.
Conclusion
This paper presents a novel technique for creating "unlearnable" datasets using nonlinear transformations. The key idea is to apply a series of nonlinear transformations to existing datasets, which can make them effectively unlearnable for machine learning models.
The authors demonstrate the effectiveness of this approach in several scenarios, including corrupting existing unlearnable datasets, probing diffusion models with transferable adversarial attacks, and stealing datasets from bidirectionally trained models.
The significance of this work lies in its potential applications for privacy-preserving data sharing, adversarial machine learning research, and understanding the vulnerabilities of different AI models. By making datasets more resistant to learning, this technique could help address concerns about the misuse of sensitive data or the potential for adversarial attacks on machine learning systems.
However, the paper also raises important questions about the limitations and potential downsides of this approach. Further research is needed to fully explore the broader implications and to develop appropriate safeguards and mitigations against misuse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
Provably Unlearnable Examples
Derui Wang, Minhui Xue, Bo Li, Seyit Camtepe, Liming Zhu
0
0
The exploitation of publicly accessible data has led to escalating concerns regarding data privacy and intellectual property (IP) breaches in the age of artificial intelligence. As a strategy to safeguard both data privacy and IP-related domain knowledge, efforts have been undertaken to render shared data unlearnable for unauthorized models in the wild. Existing methods apply empirically optimized perturbations to the data in the hope of disrupting the correlation between the inputs and the corresponding labels such that the data samples are converted into Unlearnable Examples (UEs). Nevertheless, the absence of mechanisms that can verify how robust the UEs are against unknown unauthorized models and train-time techniques engenders several problems. First, the empirically optimized perturbations may suffer from the problem of cross-model generalization, which echoes the fact that the unauthorized models are usually unknown to the defender. Second, UEs can be mitigated by train-time techniques such as data augmentation and adversarial training. Furthermore, we find that a simple recovery attack can restore the clean-task performance of the classifiers trained on UEs by slightly perturbing the learned weights. To mitigate the aforementioned problems, in this paper, we propose a mechanism for certifying the so-called $(q, eta)$-Learnability of an unlearnable dataset via parametric smoothing. A lower certified $(q, eta)$-Learnability indicates a more robust protection over the dataset. Finally, we try to 1) improve the tightness of certified $(q, eta)$-Learnability and 2) design Provably Unlearnable Examples (PUEs) which have reduced $(q, eta)$-Learnability. According to experimental results, PUEs demonstrate both decreased certified $(q, eta)$-Learnability and enhanced empirical robustness compared to existing UEs.
5/7/2024
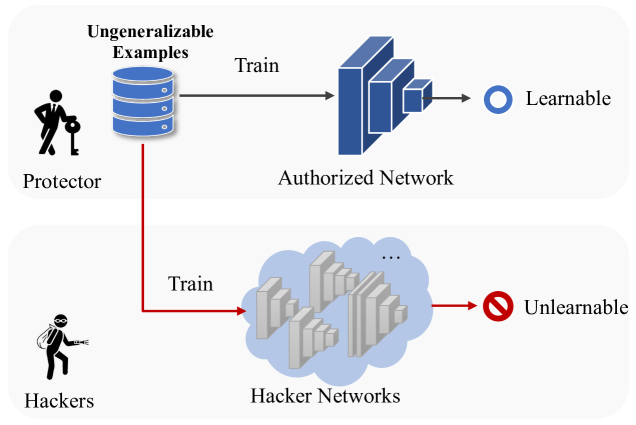
Ungeneralizable Examples
Jingwen Ye, Xinchao Wang
0
0
The training of contemporary deep learning models heavily relies on publicly available data, posing a risk of unauthorized access to online data and raising concerns about data privacy. Current approaches to creating unlearnable data involve incorporating small, specially designed noises, but these methods strictly limit data usability, overlooking its potential usage in authorized scenarios. In this paper, we extend the concept of unlearnable data to conditional data learnability and introduce textbf{U}ntextbf{G}eneralizable textbf{E}xamples (UGEs). UGEs exhibit learnability for authorized users while maintaining unlearnability for potential hackers. The protector defines the authorized network and optimizes UGEs to match the gradients of the original data and its ungeneralizable version, ensuring learnability. To prevent unauthorized learning, UGEs are trained by maximizing a designated distance loss in a common feature space. Additionally, to further safeguard the authorized side from potential attacks, we introduce additional undistillation optimization. Experimental results on multiple datasets and various networks demonstrate that the proposed UGEs framework preserves data usability while reducing training performance on hacker networks, even under different types of attacks.
4/23/2024

Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Xianlong Wang, Shengshan Hu, Minghui Li, Zhifei Yu, Ziqi Zhou, Leo Yu Zhang
0
0
Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $Theta_{imi}$, inter-class matrix consistency as $Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $Theta_{imi}$ and $Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.
4/3/2024
📊
Unlearnable Examples for Diffusion Models: Protect Data from Unauthorized Exploitation
Zhengyue Zhao, Jinhao Duan, Xing Hu, Kaidi Xu, Chenan Wang, Rui Zhang, Zidong Du, Qi Guo, Yunji Chen
0
0
Diffusion models have demonstrated remarkable performance in image generation tasks, paving the way for powerful AIGC applications. However, these widely-used generative models can also raise security and privacy concerns, such as copyright infringement, and sensitive data leakage. To tackle these issues, we propose a method, Unlearnable Diffusion Perturbation, to safeguard images from unauthorized exploitation. Our approach involves designing an algorithm to generate sample-wise perturbation noise for each image to be protected. This imperceptible protective noise makes the data almost unlearnable for diffusion models, i.e., diffusion models trained or fine-tuned on the protected data cannot generate high-quality and diverse images related to the protected training data. Theoretically, we frame this as a max-min optimization problem and introduce EUDP, a noise scheduler-based method to enhance the effectiveness of the protective noise. We evaluate our methods on both Denoising Diffusion Probabilistic Model and Latent Diffusion Models, demonstrating that training diffusion models on the protected data lead to a significant reduction in the quality of the generated images. Especially, the experimental results on Stable Diffusion demonstrate that our method effectively safeguards images from being used to train Diffusion Models in various tasks, such as training specific objects and styles. This achievement holds significant importance in real-world scenarios, as it contributes to the protection of privacy and copyright against AI-generated content.
6/26/2024