Transpose Attack: Stealing Datasets with Bidirectional Training
2311.07389
0
0
🏋️
Abstract
Deep neural networks are normally executed in the forward direction. However, in this work, we identify a vulnerability that enables models to be trained in both directions and on different tasks. Adversaries can exploit this capability to hide rogue models within seemingly legitimate models. In addition, in this work we show that neural networks can be taught to systematically memorize and retrieve specific samples from datasets. Together, these findings expose a novel method in which adversaries can exfiltrate datasets from protected learning environments under the guise of legitimate models. We focus on the data exfiltration attack and show that modern architectures can be used to secretly exfiltrate tens of thousands of samples with high fidelity, high enough to compromise data privacy and even train new models. Moreover, to mitigate this threat we propose a novel approach for detecting infected models.
Create account to get full access
Overview
- Deep neural networks are typically trained to operate in a forward direction, but this research identifies a vulnerability that allows models to be trained in both directions and on different tasks.
- Adversaries can exploit this capability to hide rogue models within seemingly legitimate models.
- The research also shows that neural networks can be taught to systematically memorize and retrieve specific samples from datasets.
- Together, these findings expose a novel method in which adversaries can exfiltrate datasets from protected learning environments under the guise of legitimate models.
Plain English Explanation
Deep neural networks are a type of machine learning model that are commonly used for tasks like image recognition and natural language processing. Normally, these models are trained to operate in a single "forward" direction, taking input data and producing an output.
However, the research presented in this paper has identified a vulnerability in deep neural networks that allows them to be trained in both the forward and "backward" directions. This means adversaries could potentially hide rogue or malicious models within seemingly legitimate models, using the bidirectional training capability as a way to conceal their true purpose.
In addition, the researchers found that neural networks can be trained to systematically memorize and retrieve specific data samples from the datasets they are trained on. This allows adversaries to use these models as a way to secretly exfiltrate or extract data from protected learning environments, under the guise of a normal, legitimate model.
Technical Explanation
The key finding of this research is the discovery of a vulnerability in deep neural networks that allows them to be trained in both the forward and backward directions. Normally, these models are only trained to operate in the forward direction, taking input data and producing an output.
However, the researchers found that by using a novel training approach, they could teach the neural networks to also operate in the backward direction. This means the models could take an output and work backwards to reconstruct the original input data.
The researchers also discovered that neural networks can be trained to systematically memorize and retrieve specific data samples from the datasets they are trained on. This allows adversaries to use these models as a way to secretly exfiltrate or extract data from protected learning environments, under the guise of a normal, legitimate model.
To mitigate this threat, the researchers propose a novel approach for detecting infected models.
Critical Analysis
While the research presented in this paper uncovers a significant vulnerability in deep neural networks, it's important to note that the researchers focused primarily on the data exfiltration attack. There may be other potential attacks or misuses of the bidirectional training capability that were not explored in depth.
Additionally, the proposed detection method for infected models may have limitations or require further refinement to be effective in real-world scenarios. Continued research and testing will be necessary to fully understand the implications and potential mitigations for this vulnerability.
It's also worth considering the broader ethical and societal implications of this research. While the findings are technically interesting, they also highlight the potential for adversaries to misuse machine learning models in ways that could compromise data privacy and security. Ongoing discussions and guidelines around the responsible development and deployment of AI systems will be crucial.
Conclusion
This research paper has uncovered a significant vulnerability in deep neural networks, showing that they can be trained to operate in both the forward and backward directions. Adversaries can exploit this capability to hide rogue models within seemingly legitimate models and secretly exfiltrate data from protected learning environments.
The researchers have proposed a novel detection method to help mitigate this threat, but further work will be needed to fully address the implications of this vulnerability. As the use of deep neural networks continues to grow, it will be critical for the research community, industry, and policymakers to work together to ensure the responsible and secure development of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Stealing Image-to-Image Translation Models With a Single Query
Nurit Spingarn-Eliezer, Tomer Michaeli
0
0
Training deep neural networks requires significant computational resources and large datasets that are often confidential or expensive to collect. As a result, owners tend to protect their models by allowing access only via an API. Many works demonstrated the possibility of stealing such protected models by repeatedly querying the API. However, to date, research has predominantly focused on stealing classification models, for which a very large number of queries has been found necessary. In this paper, we study the possibility of stealing image-to-image models. Surprisingly, we find that many such models can be stolen with as little as a single, small-sized, query image using simple distillation. We study this phenomenon on a wide variety of model architectures, datasets, and tasks, including denoising, deblurring, deraining, super-resolution, and biological image-to-image translation. Remarkably, we find that the vulnerability to stealing attacks is shared by CNNs and by models with attention mechanisms, and that stealing is commonly possible even without knowing the architecture of the target model.
6/4/2024
🌐
Partial train and isolate, mitigate backdoor attack
Yong Li, Han Gao
0
0
Neural networks are widely known to be vulnerable to backdoor attacks, a method that poisons a portion of the training data to make the target model perform well on normal data sets, while outputting attacker-specified or random categories on the poisoned samples. Backdoor attacks are full of threats. Poisoned samples are becoming more and more similar to corresponding normal samples, and even the human eye cannot easily distinguish them. On the other hand, the accuracy of models carrying backdoors on normal samples is no different from that of clean models.In this article, by observing the characteristics of backdoor attacks, We provide a new model training method (PT) that freezes part of the model to train a model that can isolate suspicious samples. Then, on this basis, a clean model is fine-tuned to resist backdoor attacks.
6/7/2024
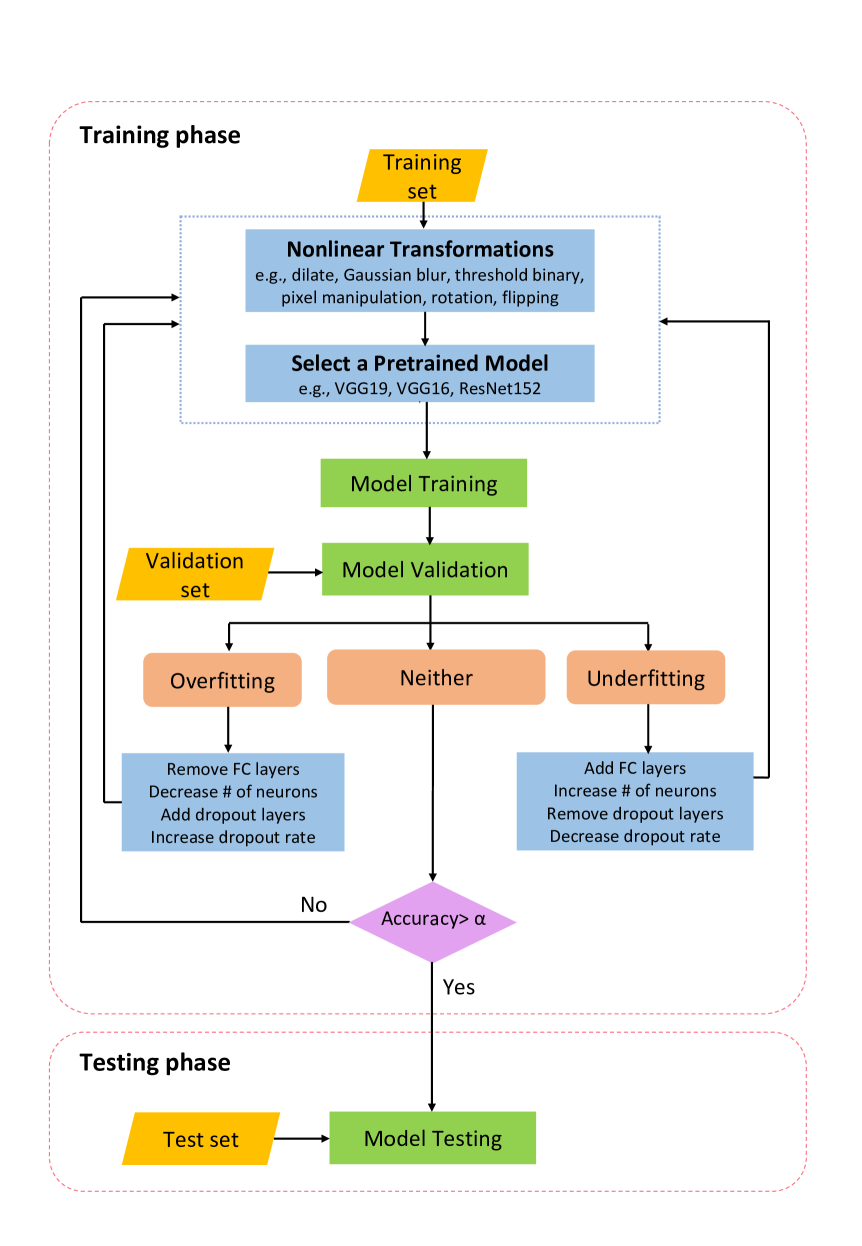
Nonlinear Transformations Against Unlearnable Datasets
Thushari Hapuarachchi, Jing Lin, Kaiqi Xiong, Mohamed Rahouti, Gitte Ost
0
0
Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called unlearnable examples, are prevented learning by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.
6/6/2024
🏋️
When Machine Learning Models Leak: An Exploration of Synthetic Training Data
Manel Slokom, Peter-Paul de Wolf, Martha Larson
0
0
We investigate an attack on a machine learning model that predicts whether a person or household will relocate in the next two years, i.e., a propensity-to-move classifier. The attack assumes that the attacker can query the model to obtain predictions and that the marginal distribution of the data on which the model was trained is publicly available. The attack also assumes that the attacker has obtained the values of non-sensitive attributes for a certain number of target individuals. The objective of the attack is to infer the values of sensitive attributes for these target individuals. We explore how replacing the original data with synthetic data when training the model impacts how successfully the attacker can infer sensitive attributes.
5/21/2024