Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
2308.12517
0
0
👁️
Abstract
Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.
Create account to get full access
Overview
- The paper proposes a novel reinforcement learning framework for training neural network controllers for complex robotic systems using both rewards and constraints.
- This approach allows engineers to more easily reflect their design intent through constraints and handle them efficiently, reducing the need for extensive reward engineering.
- The framework is applied to train locomotion controllers for various legged robots, demonstrating impressive performance on challenging terrains with significantly less reward engineering.
Plain English Explanation
The researchers have developed a new way to train robotic systems to move and navigate complex environments. Traditionally, this has been done by carefully designing many different reward signals, or "rewards," that the robot tries to maximize during the training process. This reward engineering is a time-consuming and difficult task.
The researchers' approach instead uses a combination of rewards and constraints. Constraints are rules or guidelines that the robot must follow, rather than just maximizing rewards. This allows the engineers to more easily express their design intent for the robot's behavior.
The researchers demonstrated this new training framework by using it to teach several different legged robots, with various body shapes and physical properties, how to traverse challenging terrains. They found that the robots could be trained to move very effectively while requiring much less time spent designing the reward functions, by instead focusing on defining the appropriate constraints.
This is an important advance, as it can make the process of training high-performing robotic controllers more straightforward and accessible. The use of constraints also makes the resulting controllers more interpretable and generalizable, which are key considerations for real-world robotic applications.
Technical Explanation
The paper proposes a novel reinforcement learning framework for training neural network controllers for complex robotic systems. In contrast to prior work that relied heavily on extensive reward engineering, this approach combines both rewards and constraints to guide the learning process.
The researchers introduce two types of constraints: equality constraints, which enforce strict rules, and inequality constraints, which define bounds on the robot's behavior. An efficient policy optimization algorithm is used to handle these constraints during training.
The framework is applied to train locomotion controllers for a variety of legged robots, including those with different morphologies and physical attributes, bipedal robots, and humanoid systems. Through extensive simulation and real-world experiments, the researchers demonstrate that high-performing controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient.
Additionally, the use of constraints allows for a more straightforward and intuitive engineering process, as the designers can more easily reflect their intent. The constraints also improve the interpretability and generalizability of the resulting controllers, which is crucial for real-world legged manipulation and locomotion tasks.
Critical Analysis
The paper presents a compelling approach to reducing the burden of reward engineering in training complex robotic controllers. The use of constraints in addition to rewards is a promising direction, as it allows engineers to more directly express their design intent.
One potential limitation is the reliance on simulation-based training, which may not fully capture the complexity of real-world environments. While the researchers do present some real-world experiments, further validation on a broader range of physical systems would be valuable.
Additionally, the paper does not provide a detailed analysis of the computational overhead or training time required for the constrained optimization approach, compared to more traditional reward-only methods. This information would be helpful for assessing the practicality of the framework in real-world applications.
Overall, the researchers have made an important contribution by demonstrating the benefits of incorporating constraints into the reinforcement learning process for robotic control. The approach shows promise for making the development of high-performing robotic systems more accessible and intuitive.
Conclusion
This paper presents a novel reinforcement learning framework that combines rewards and constraints to train neural network controllers for complex robotic systems. By allowing engineers to more easily reflect their design intent through constraints, the approach reduces the need for extensive reward engineering, a common bottleneck in developing high-performing robotic controllers.
The researchers demonstrate the effectiveness of this framework by applying it to train locomotion controllers for various legged robots, showing impressive performance on challenging terrains. The use of constraints also enhances the interpretability and generalizability of the resulting controllers, which is a key consideration for real-world robotic applications.
This work represents an important step forward in making the development of advanced robotic systems more accessible and efficient. The integration of rewards and constraints in the reinforcement learning process has the potential to unlock new possibilities in robotic control and navigation, with important implications for a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
Joonho Lee, Marko Bjelonic, Alexander Reske, Lorenz Wellhausen, Takahiro Miki, Marco Hutter
0
0
Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
5/6/2024
🏅
Agile and versatile bipedal robot tracking control through reinforcement learning
Jiayi Li, Linqi Ye, Yi Cheng, Houde Liu, Bin Liang
0
0
The remarkable athletic intelligence displayed by humans in complex dynamic movements such as dancing and gymnastics suggests that the balance mechanism in biological beings is decoupled from specific movement patterns. This decoupling allows for the execution of both learned and unlearned movements under certain constraints while maintaining balance through minor whole-body coordination. To replicate this balance ability and body agility, this paper proposes a versatile controller for bipedal robots. This controller achieves ankle and body trajectory tracking across a wide range of gaits using a single small-scale neural network, which is based on a model-based IK solver and reinforcement learning. We consider a single step as the smallest control unit and design a universally applicable control input form suitable for any single-step variation. Highly flexible gait control can be achieved by combining these minimal control units with high-level policy through our extensible control interface. To enhance the trajectory-tracking capability of our controller, we utilize a three-stage training curriculum. After training, the robot can move freely between target footholds at varying distances and heights. The robot can also maintain static balance without repeated stepping to adjust posture. Finally, we evaluate the tracking accuracy of our controller on various bipedal tasks, and the effectiveness of our control framework is verified in the simulation environment.
4/15/2024

Revisiting Reward Design and Evaluation for Robust Humanoid Standing and Walking
Bart van Marum, Aayam Shrestha, Helei Duan, Pranay Dugar, Jeremy Dao, Alan Fern
0
0
A necessary capability for humanoid robots is the ability to stand and walk while rejecting natural disturbances. Recent progress has been made using sim-to-real reinforcement learning (RL) to train such locomotion controllers, with approaches differing mainly in their reward functions. However, prior works lack a clear method to systematically test new reward functions and compare controller performance through repeatable experiments. This limits our understanding of the trade-offs between approaches and hinders progress. To address this, we propose a low-cost, quantitative benchmarking method to evaluate and compare the real-world performance of standing and walking (SaW) controllers on metrics like command following, disturbance recovery, and energy efficiency. We also revisit reward function design and construct a minimally constraining reward function to train SaW controllers. We experimentally verify that our benchmarking framework can identify areas for improvement, which can be systematically addressed to enhance the policies. We also compare our new controller to state-of-the-art controllers on the Digit humanoid robot. The results provide clear quantitative trade-offs among the controllers and suggest directions for future improvements to the reward functions and expansion of the benchmarks.
5/1/2024
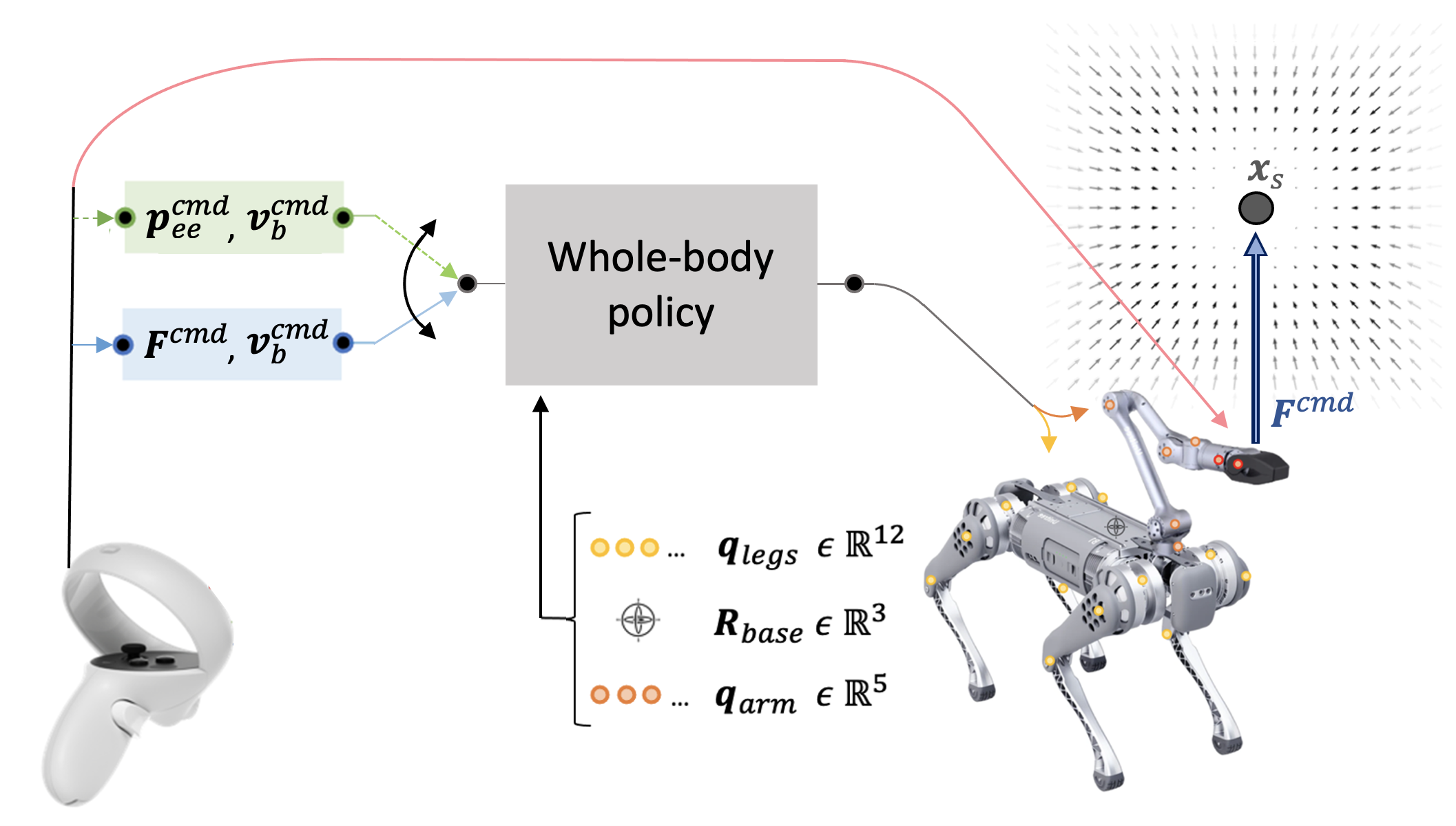
Learning Force Control for Legged Manipulation
Tifanny Portela, Gabriel B. Margolis, Yandong Ji, Pulkit Agrawal
0
0
Controlling contact forces during interactions is critical for locomotion and manipulation tasks. While sim-to-real reinforcement learning (RL) has succeeded in many contact-rich problems, current RL methods achieve forceful interactions implicitly without explicitly regulating forces. We propose a method for training RL policies for direct force control without requiring access to force sensing. We showcase our method on a whole-body control platform of a quadruped robot with an arm. Such force control enables us to perform gravity compensation and impedance control, unlocking compliant whole-body manipulation. The learned whole-body controller with variable compliance makes it intuitive for humans to teleoperate the robot by only commanding the manipulator, and the robot's body adjusts automatically to achieve the desired position and force. Consequently, a human teleoperator can easily demonstrate a wide variety of loco-manipulation tasks. To the best of our knowledge, we provide the first deployment of learned whole-body force control in legged manipulators, paving the way for more versatile and adaptable legged robots.
5/21/2024