Locomotion Generation for a Rat Robot based on Environmental Changes via Reinforcement Learning
2403.11788
0
0

Abstract
This research focuses on developing reinforcement learning approaches for the locomotion generation of small-size quadruped robots. The rat robot NeRmo is employed as the experimental platform. Due to the constrained volume, small-size quadruped robots typically possess fewer and weaker sensors, resulting in difficulty in accurately perceiving and responding to environmental changes. In this context, insufficient and imprecise feedback data from sensors makes it difficult to generate adaptive locomotion based on reinforcement learning. To overcome these challenges, this paper proposes a novel reinforcement learning approach that focuses on extracting effective perceptual information to enhance the environmental adaptability of small-size quadruped robots. According to the frequency of a robot's gait stride, key information of sensor data is analyzed utilizing sinusoidal functions derived from Fourier transform results. Additionally, a multifunctional reward mechanism is proposed to generate adaptive locomotion in different tasks. Extensive simulations are conducted to assess the effectiveness of the proposed reinforcement learning approach in generating rat robot locomotion in various environments. The experiment results illustrate the capability of the proposed approach to maintain stable locomotion of a rat robot across different terrains, including ramps, stairs, and spiral stairs.
Create account to get full access
Overview
- The paper explores a reinforcement learning approach to generate locomotion for a rat-inspired robot based on environmental changes.
- The robot is equipped with sensors to perceive its surroundings and uses this information to adaptively adjust its locomotion patterns.
- The goal is to enable the robot to navigate different environments effectively by learning to modify its movement strategies.
Plain English Explanation
The researchers have developed a rat-inspired robot that can adapt its walking and movement based on the changes in its environment. The robot has sensors that allow it to detect and understand its surroundings. Using a machine learning technique called reinforcement learning, the robot learns to adjust its locomotion patterns to navigate different environments more efficiently.
For example, if the robot encounters a rocky, uneven surface, it may need to take smaller, more cautious steps to maintain stability. In a smooth, flat area, it could switch to longer, more confident strides. The reinforcement learning approach allows the robot to continuously learn and improve its movement strategies based on the feedback it receives from the environment.
This type of adaptive locomotion is useful for robots that need to operate in a variety of settings, such as search and rescue missions, exploration of hazardous areas, or even household chores. By being able to adjust its movement in response to changing conditions, the robot can navigate more effectively and complete its tasks more reliably.
Technical Explanation
The paper presents a reinforcement learning-based approach to generate adaptive locomotion for a rat-inspired robot. The robot is equipped with a range of sensors, including cameras, touch sensors, and proprioceptive sensors, which allow it to perceive its environment and the effects of its own actions.
The researchers use a deep reinforcement learning algorithm, specifically a proximal policy optimization (PPO) method, to train the robot to learn optimal locomotion strategies based on the sensory feedback it receives. The robot's actions, such as joint movements and body posture, are represented as the policy, which the algorithm aims to optimize to maximize a reward signal that captures the robot's ability to navigate the environment effectively.
The experimental setup involves the robot navigating through different terrains, including flat surfaces, steps, and uneven terrain. The robot's performance is evaluated based on metrics such as the distance traveled, energy consumption, and stability. The results demonstrate that the reinforcement learning approach enables the robot to adapt its locomotion patterns to the changing environmental conditions, outperforming a baseline controller that uses a fixed gait.
The authors also discuss the potential applications of this technology, such as in search and rescue operations, exploration of hazardous areas, and household robotics, where the ability to adapt to different environments is crucial for effective task completion.
Critical Analysis
The research presented in the paper is a promising step towards developing more versatile and adaptive robots. The use of reinforcement learning to generate locomotion strategies based on environmental feedback is a compelling approach that could lead to significant advancements in robot mobility and navigation.
One potential limitation of the study is the relatively simple and controlled environments used in the experiments. While the researchers demonstrate the robot's ability to adapt to different terrains, it would be valuable to evaluate the system's performance in more complex, real-world scenarios with unpredictable obstacles and dynamic conditions.
Additionally, the paper does not provide a detailed analysis of the computational requirements and training time needed for the reinforcement learning algorithm. This information would be useful for assessing the practical feasibility of deploying such systems in real-world applications, where resource constraints and deployment timelines may be critical factors.
Further research could explore the scalability of the approach, the robustness of the learned locomotion strategies to sensor noise and uncertainties, and the potential for transfer learning to allow the robot to adapt to new environments more efficiently. Incorporating insights from related work on agile bipedal robot tracking control, adaptive energy-based gait transitions, and multi-agent reinforcement learning for chemotaxis could also provide valuable cross-pollination of ideas.
Conclusion
The paper presents a compelling approach to generating adaptive locomotion for a rat-inspired robot using reinforcement learning. By equipping the robot with sensors to perceive its environment and training it to optimize its movement strategies based on this feedback, the researchers have demonstrated the potential for robots to navigate a variety of terrains more effectively.
This work has important implications for the development of robots that can operate in complex, unstructured environments, such as in long-horizon locomotion and manipulation tasks for quadrupedal robots or learning agile soccer skills for bipedal robots. As this field continues to evolve, the ability of robots to adapt to their surroundings will be crucial for expanding their capabilities and realizing their full potential in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
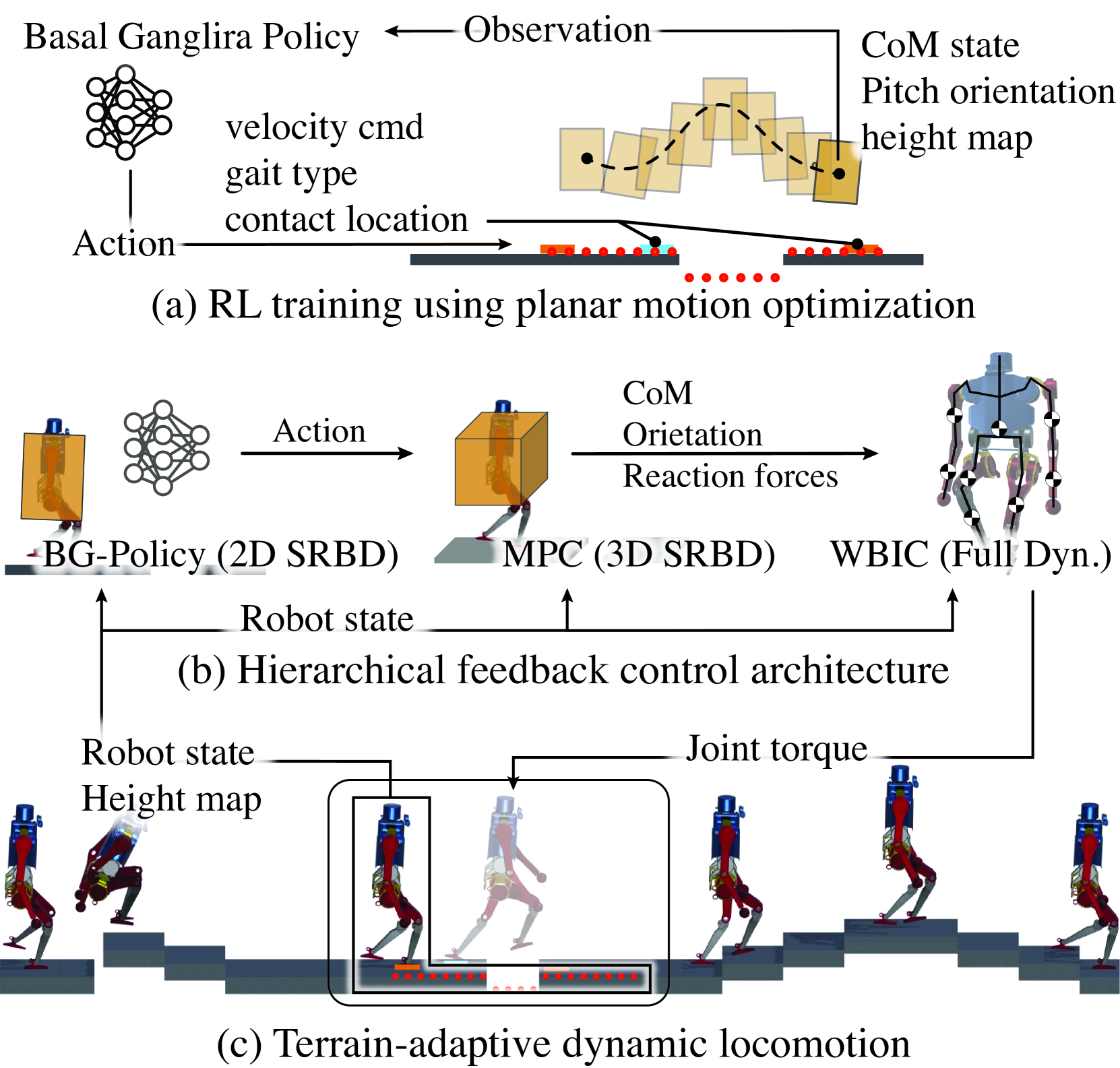
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
0
0
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
5/28/2024

Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
Joonho Lee, Marko Bjelonic, Alexander Reske, Lorenz Wellhausen, Takahiro Miki, Marco Hutter
0
0
Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
5/6/2024
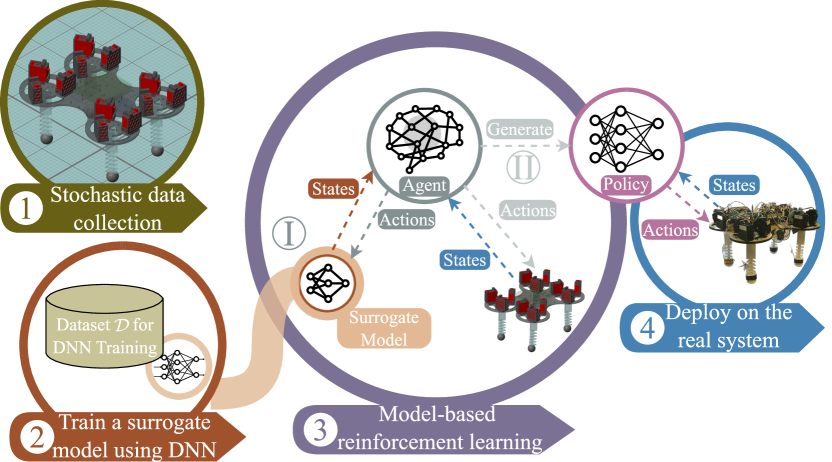
Optimal Gait Control for a Tendon-driven Soft Quadruped Robot by Model-based Reinforcement Learning
Xuezhi Niu, Kaige Tan, Lei Feng
0
0
This study presents an innovative approach to optimal gait control for a soft quadruped robot enabled by four Compressible Tendon-driven Soft Actuators (CTSAs). Improving our previous studies of using model-free reinforcement learning for gait control, we employ model-based reinforcement learning (MBRL) to further enhance the performance of the gait controller. Compared to rigid robots, the proposed soft quadruped robot has better safety, less weight, and a simpler mechanism for fabrication and control. However, the primary challenge lies in developing sophisticated control algorithms to attain optimal gait control for fast and stable locomotion. The research employs a multi-stage methodology, including state space restriction, data-driven model training, and reinforcement learning algorithm development. Compared to benchmark methods, the proposed MBRL algorithm, combined with post-training, significantly improves the efficiency and performance of gait control policies. The developed policy is both robust and adaptable to the robot's deformable morphology. The study concludes by highlighting the practical applicability of these findings in real-world scenarios.
6/12/2024
👁️
Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
Yunho Kim, Hyunsik Oh, Jeonghyun Lee, Jinhyeok Choi, Gwanghyeon Ji, Moonkyu Jung, Donghoon Youm, Jemin Hwangbo
0
0
Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.
5/7/2024