A Novel Joint DRL-Based Utility Optimization for UAV Data Services
2406.10664
0
0
Abstract
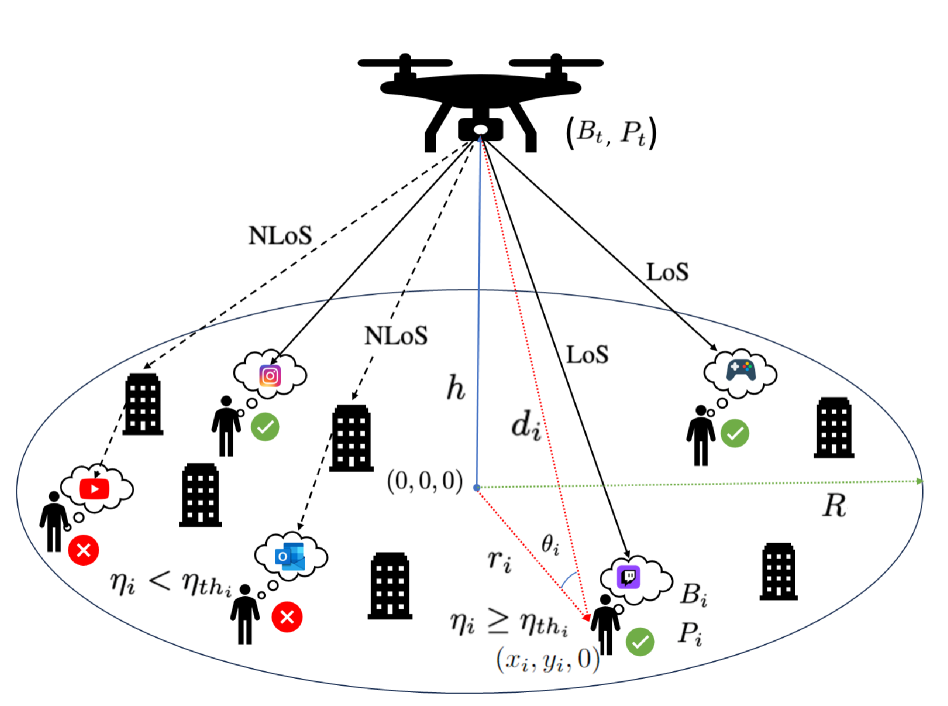
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Create account to get full access
Overview
• This paper presents a novel joint deep reinforcement learning (DRL)-based utility optimization approach for unmanned aerial vehicle (UAV) data services.
• The proposed solution aims to optimize the utility of UAV data services by jointly considering various factors, including Rayleigh and Rician fading, line-of-sight (LoS) and non-line-of-sight (NLoS) conditions, and deep Q-network (DQN) and deep deterministic policy gradient (DDPG) algorithms.
Plain English Explanation
• Unmanned aerial vehicles (UAVs) are becoming increasingly useful for providing data services, such as wireless communication and internet access, to areas with limited infrastructure.
• However, the quality of these data services can be affected by factors like signal fading (where the signal strength decreases over distance) and whether there is a direct line-of-sight between the UAV and the user.
• This paper introduces a new approach that uses deep reinforcement learning (a type of machine learning) to optimize the utility or usefulness of the data services provided by UAVs.
• The approach considers different types of signal fading, as well as whether there is a direct line-of-sight or not, and uses two specific deep reinforcement learning algorithms (DQN and DDPG) to make decisions that maximize the overall utility of the UAV data services.
Technical Explanation
• The paper presents a system model that captures the UAV data service environment, including factors like Rayleigh and Rician fading, LoS and NLoS conditions, and the use of DQN and DDPG algorithms.
• The authors formulate the problem as a utility optimization task, aiming to maximize the overall utility of the UAV data services while considering the various environmental factors.
• To solve this problem, the authors propose a joint DRL-based approach that combines the DQN and DDPG algorithms to make optimal decisions for the UAV data service operations.
• The proposed solution is evaluated through simulations, and the results demonstrate the effectiveness of the joint DRL-based approach in improving the utility of UAV data services compared to other benchmark methods.
Critical Analysis
• The paper provides a comprehensive and technical explanation of the proposed solution, but it does not address potential limitations or areas for further research in detail.
• While the simulation results are promising, it would be helpful to understand the computational complexity and feasibility of implementing the joint DRL-based approach in real-world UAV data service scenarios.
• Additionally, the paper could benefit from a more thorough discussion of the potential challenges and trade-offs involved in balancing the optimization of utility with other important factors, such as energy consumption, network coverage, and user experience.
Conclusion
• This paper introduces a novel joint DRL-based approach for optimizing the utility of UAV data services, considering various environmental factors such as signal fading and line-of-sight conditions.
• The proposed solution demonstrates the potential of deep reinforcement learning techniques to enhance the performance and reliability of UAV-based data services, which could have significant implications for the development of future wireless communication and internet access solutions, especially in areas with limited infrastructure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-UAV Multi-RIS QoS-Aware Aerial Communication Systems using DRL and PSO
Marwan Dhuheir, Aiman Erbad, Ala Al-Fuqaha, Mohsen Guizani
0
0
Recently, Unmanned Aerial Vehicles (UAVs) have attracted the attention of researchers in academia and industry for providing wireless services to ground users in diverse scenarios like festivals, large sporting events, natural and man-made disasters due to their advantages in terms of versatility and maneuverability. However, the limited resources of UAVs (e.g., energy budget and different service requirements) can pose challenges for adopting UAVs for such applications. Our system model considers a UAV swarm that navigates an area, providing wireless communication to ground users with RIS support to improve the coverage of the UAVs. In this work, we introduce an optimization model with the aim of maximizing the throughput and UAVs coverage through optimal path planning of UAVs and multi-RIS phase configurations. The formulated optimization is challenging to solve using standard linear programming techniques, limiting its applicability in real-time decision-making. Therefore, we introduce a two-step solution using deep reinforcement learning and particle swarm optimization. We conduct extensive simulations and compare our approach to two competitive solutions presented in the recent literature. Our simulation results demonstrate that our adopted approach is 20 % better than the brute-force approach and 30% better than the baseline solution in terms of QoS.
6/26/2024
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Ze Yu Zhao, Yue Ling Che, Sheng Luo, Gege Luo, Kaishun Wu, Victor C. M. Leung
0
0
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.
6/10/2024
🏅
Multi-Agent Reinforcement Learning for Offloading Cellular Communications with Cooperating UAVs
Abhishek Mondal, Deepak Mishra, Ganesh Prasad, George C. Alexandropoulos, Azzam Alnahari, Riku Jantti
0
0
Effective solutions for intelligent data collection in terrestrial cellular networks are crucial, especially in the context of Internet of Things applications. The limited spectrum and coverage area of terrestrial base stations pose challenges in meeting the escalating data rate demands of network users. Unmanned aerial vehicles, known for their high agility, mobility, and flexibility, present an alternative means to offload data traffic from terrestrial BSs, serving as additional access points. This paper introduces a novel approach to efficiently maximize the utilization of multiple UAVs for data traffic offloading from terrestrial BSs. Specifically, the focus is on maximizing user association with UAVs by jointly optimizing UAV trajectories and users association indicators under quality of service constraints. Since, the formulated UAVs control problem is nonconvex and combinatorial, this study leverages the multi agent reinforcement learning framework. In this framework, each UAV acts as an independent agent, aiming to maintain inter UAV cooperative behavior. The proposed approach utilizes the finite state Markov decision process to account for UAVs velocity constraints and the relationship between their trajectories and state space. A low complexity distributed state action reward state action algorithm is presented to determine UAVs optimal sequential decision making policies over training episodes. The extensive simulation results validate the proposed analysis and offer valuable insights into the optimal UAV trajectories. The derived trajectories demonstrate superior average UAV association performance compared to benchmark techniques such as Q learning and particle swarm optimization.
6/4/2024

UAV-enabled Collaborative Beamforming via Multi-Agent Deep Reinforcement Learning
Saichao Liu, Geng Sun, Jiahui Li, Shuang Liang, Qingqing Wu, Pengfei Wang, Dusit Niyato
0
0
In this paper, we investigate an unmanned aerial vehicle (UAV)-assistant air-to-ground communication system, where multiple UAVs form a UAV-enabled virtual antenna array (UVAA) to communicate with remote base stations by utilizing collaborative beamforming. To improve the work efficiency of the UVAA, we formulate a UAV-enabled collaborative beamforming multi-objective optimization problem (UCBMOP) to simultaneously maximize the transmission rate of the UVAA and minimize the energy consumption of all UAVs by optimizing the positions and excitation current weights of all UAVs. This problem is challenging because these two optimization objectives conflict with each other, and they are non-concave to the optimization variables. Moreover, the system is dynamic, and the cooperation among UAVs is complex, making traditional methods take much time to compute the optimization solution for a single task. In addition, as the task changes, the previously obtained solution will become obsolete and invalid. To handle these issues, we leverage the multi-agent deep reinforcement learning (MADRL) to address the UCBMOP. Specifically, we use the heterogeneous-agent trust region policy optimization (HATRPO) as the basic framework, and then propose an improved HATRPO algorithm, namely HATRPO-UCB, where three techniques are introduced to enhance the performance. Simulation results demonstrate that the proposed algorithm can learn a better strategy compared with other methods. Moreover, extensive experiments also demonstrate the effectiveness of the proposed techniques.
4/12/2024