UAV-enabled Collaborative Beamforming via Multi-Agent Deep Reinforcement Learning
2404.07453
0
0

Abstract
In this paper, we investigate an unmanned aerial vehicle (UAV)-assistant air-to-ground communication system, where multiple UAVs form a UAV-enabled virtual antenna array (UVAA) to communicate with remote base stations by utilizing collaborative beamforming. To improve the work efficiency of the UVAA, we formulate a UAV-enabled collaborative beamforming multi-objective optimization problem (UCBMOP) to simultaneously maximize the transmission rate of the UVAA and minimize the energy consumption of all UAVs by optimizing the positions and excitation current weights of all UAVs. This problem is challenging because these two optimization objectives conflict with each other, and they are non-concave to the optimization variables. Moreover, the system is dynamic, and the cooperation among UAVs is complex, making traditional methods take much time to compute the optimization solution for a single task. In addition, as the task changes, the previously obtained solution will become obsolete and invalid. To handle these issues, we leverage the multi-agent deep reinforcement learning (MADRL) to address the UCBMOP. Specifically, we use the heterogeneous-agent trust region policy optimization (HATRPO) as the basic framework, and then propose an improved HATRPO algorithm, namely HATRPO-UCB, where three techniques are introduced to enhance the performance. Simulation results demonstrate that the proposed algorithm can learn a better strategy compared with other methods. Moreover, extensive experiments also demonstrate the effectiveness of the proposed techniques.
Create account to get full access
Overview
- This paper explores the use of unmanned aerial vehicles (UAVs) for collaborative beamforming, a technique that can improve the energy efficiency of wireless communications.
- The researchers propose a multi-agent deep reinforcement learning approach to coordinate the actions of multiple UAVs in a decentralized manner, enabling them to collaboratively form beams that optimize overall network performance.
- The paper evaluates the proposed method through simulations and compares its performance to other benchmarks, demonstrating its advantages in terms of energy efficiency and communication quality.
Plain English Explanation
Wireless communications often rely on beamforming, a technique that focuses the transmitted signal in a specific direction to improve its strength and efficiency. In this paper, the researchers explore a way to make beamforming even more effective by using multiple UAVs (unmanned aerial vehicles) to collaborate on the process.
The key idea is to have a swarm of UAVs work together, each adjusting its position and transmission parameters to collectively form the optimal beam for communicating with ground-based devices. This collaborative approach can lead to significant improvements in energy efficiency and communication quality compared to having a single UAV or ground-based system handle the beamforming.
To coordinate the actions of the UAVs, the researchers use a multi-agent deep reinforcement learning algorithm. This allows the UAVs to learn the optimal behaviors through trial-and-error, without the need for centralized control or detailed prior knowledge of the environment.
The researchers evaluate their proposed method through computer simulations, comparing its performance to other beamforming techniques. They demonstrate that their approach can achieve better energy efficiency and communication quality, making it a promising solution for various applications that rely on wireless communications, such as secure aerial communications or ground-space communications.
Technical Explanation
The paper presents a novel approach for UAV-enabled collaborative beamforming using multi-agent deep reinforcement learning (MADRL). The key idea is to leverage a swarm of UAVs to collectively form an optimal beam for wireless communications, rather than relying on a single UAV or ground-based system.
The researchers formulate the problem as a multi-agent Markov Decision Process (MDP), where each UAV is an autonomous agent that learns to adjust its position and transmission parameters to contribute to the overall beamforming objective. They propose a MADRL algorithm based on the Trust Region Policy Optimization (TRPO) method, which allows the UAVs to learn the optimal behaviors through trial-and-error without the need for centralized control or detailed prior knowledge of the environment.
The MADRL approach enables the UAVs to learn a collaborative beamforming policy that jointly maximizes the energy efficiency and communication quality of the overall system. The researchers evaluate their proposed method through extensive simulations, comparing its performance to other beamforming techniques, such as codebook-based beam tracking and a baseline single-UAV beamforming approach.
The results demonstrate that the UAV-enabled collaborative beamforming method outperforms the benchmarks in terms of energy efficiency and communication quality, particularly in scenarios with dynamic channel conditions or the presence of obstacles. The researchers attribute the performance gains to the collective intelligence and adaptability of the multi-agent system, which can better cope with the challenges of wireless communications in complex environments.
Critical Analysis
The paper presents a promising approach for improving the energy efficiency and performance of wireless communications through the use of collaborative beamforming with UAVs. The MADRL-based method allows the UAVs to learn optimal behaviors in a decentralized manner, which is an interesting and practical solution given the challenges of coordinating a swarm of autonomous agents.
However, the paper does not address several important considerations that could limit the real-world applicability of the proposed approach. For instance, the simulations assume perfect knowledge of the channel state information and do not consider the impact of imperfect or noisy channel estimation, which can be a significant challenge in practical wireless systems.
Additionally, the paper does not discuss the computational and communication overhead required for the MADRL training and execution, which could be a concern for resource-constrained UAV platforms. The scalability of the approach as the number of UAVs and ground users increases is also not thoroughly explored.
Further research would be needed to address these limitations and investigate the feasibility of implementing the proposed collaborative beamforming solution in real-world wireless networks. Factors such as the reliability, latency, and robustness of the multi-agent coordination, as well as the impact of UAV mobility constraints and energy limitations, should be carefully considered.
Conclusion
This paper presents a novel approach for UAV-enabled collaborative beamforming using multi-agent deep reinforcement learning. The key idea is to leverage a swarm of UAVs to collectively form an optimal beam for wireless communications, which can improve energy efficiency and communication quality compared to single-UAV or ground-based beamforming solutions.
The MADRL-based method allows the UAVs to learn the optimal behaviors in a decentralized manner, without the need for centralized control or detailed prior knowledge of the environment. The simulation results demonstrate the advantages of the proposed approach, particularly in dynamic and complex wireless scenarios.
While the paper presents a promising solution, further research is needed to address practical considerations such as the impact of imperfect channel estimation, the computational and communication overhead, and the scalability of the approach. Nonetheless, the concept of UAV-enabled collaborative beamforming has significant potential to enhance the performance and energy efficiency of future wireless communication systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Multi-Agent Reinforcement Learning for Offloading Cellular Communications with Cooperating UAVs
Abhishek Mondal, Deepak Mishra, Ganesh Prasad, George C. Alexandropoulos, Azzam Alnahari, Riku Jantti
0
0
Effective solutions for intelligent data collection in terrestrial cellular networks are crucial, especially in the context of Internet of Things applications. The limited spectrum and coverage area of terrestrial base stations pose challenges in meeting the escalating data rate demands of network users. Unmanned aerial vehicles, known for their high agility, mobility, and flexibility, present an alternative means to offload data traffic from terrestrial BSs, serving as additional access points. This paper introduces a novel approach to efficiently maximize the utilization of multiple UAVs for data traffic offloading from terrestrial BSs. Specifically, the focus is on maximizing user association with UAVs by jointly optimizing UAV trajectories and users association indicators under quality of service constraints. Since, the formulated UAVs control problem is nonconvex and combinatorial, this study leverages the multi agent reinforcement learning framework. In this framework, each UAV acts as an independent agent, aiming to maintain inter UAV cooperative behavior. The proposed approach utilizes the finite state Markov decision process to account for UAVs velocity constraints and the relationship between their trajectories and state space. A low complexity distributed state action reward state action algorithm is presented to determine UAVs optimal sequential decision making policies over training episodes. The extensive simulation results validate the proposed analysis and offer valuable insights into the optimal UAV trajectories. The derived trajectories demonstrate superior average UAV association performance compared to benchmark techniques such as Q learning and particle swarm optimization.
6/4/2024
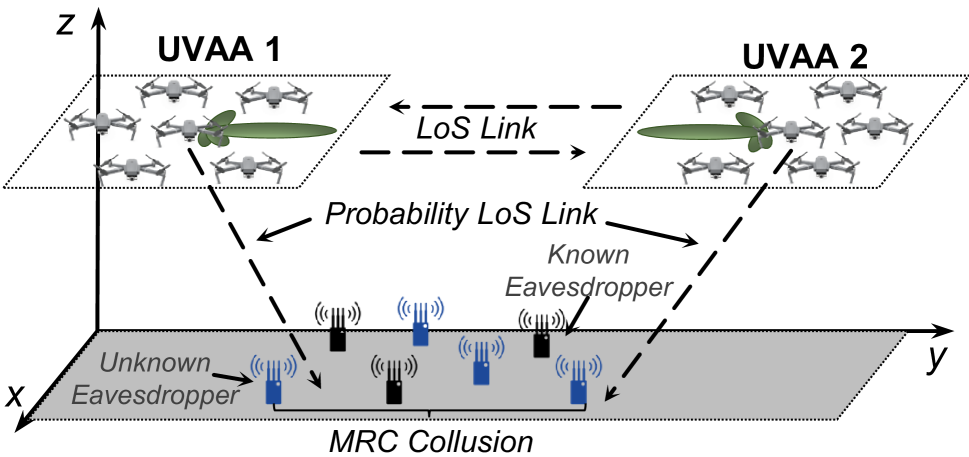
Two-Way Aerial Secure Communications via Distributed Collaborative Beamforming under Eavesdropper Collusion
Jiahui Li, Geng Sun, Qingqing Wu, Shuang Liang, Pengfei Wang, Dusit Niyato
0
0
Unmanned aerial vehicles (UAVs)-enabled aerial communication provides a flexible, reliable, and cost-effective solution for a range of wireless applications. However, due to the high line-of-sight (LoS) probability, aerial communications between UAVs are vulnerable to eavesdropping attacks, particularly when multiple eavesdroppers collude. In this work, we aim to introduce distributed collaborative beamforming (DCB) into UAV swarms and handle the eavesdropper collusion by controlling the corresponding signal distributions. Specifically, we consider a two-way DCB-enabled aerial communication between two UAV swarms and construct these swarms as two UAV virtual antenna arrays. Then, we minimize the two-way known secrecy capacity and the maximum sidelobe level to avoid information leakage from the known and unknown eavesdroppers, respectively. Simultaneously, we also minimize the energy consumption of UAVs for constructing virtual antenna arrays. Due to the conflicting relationships between secure performance and energy efficiency, we consider these objectives as a multi-objective optimization problem. Following this, we propose an enhanced multi-objective swarm intelligence algorithm via the characterized properties of the problem. Simulation results show that our proposed algorithm can obtain a set of informative solutions and outperform other state-of-the-art baseline algorithms. Experimental tests demonstrate that our method can be deployed in limited computing power platforms of UAVs and is beneficial for saving computational resources.
4/12/2024

Collaborative Ground-Space Communications via Evolutionary Multi-objective Deep Reinforcement Learning
Jiahui Li, Geng Sun, Qingqing Wu, Dusit Niyato, Jiawen Kang, Abbas Jamalipour, Victor C. M. Leung
0
0
In this paper, we propose a distributed collaborative beamforming (DCB)-based uplink communication paradigm for enabling ground-space direct communications. Specifically, DCB treats the terminals that are unable to establish efficient direct connections with the low Earth orbit (LEO) satellites as distributed antennas, forming a virtual antenna array to enhance the terminal-to-satellite uplink achievable rates and durations. However, such systems need multiple trade-off policies that variously balance the terminal-satellite uplink achievable rate, energy consumption of terminals, and satellite switching frequency to satisfy the scenario requirement changes. Thus, we perform a multi-objective optimization analysis and formulate a long-term optimization problem. To address availability in different terminal cluster scales, we reformulate this problem into an action space-reduced and universal multi-objective Markov decision process. Then, we propose an evolutionary multi-objective deep reinforcement learning algorithm to obtain the desirable policies, in which the low-value actions are masked to speed up the training process. As such, the applicability of a one-time trained model can cover more changing terminal-satellite uplink scenarios. Simulation results show that the proposed algorithm outmatches various baselines, and draw some useful insights. Specifically, it is found that DCB enables terminals that cannot reach the uplink achievable threshold to achieve efficient direct uplink transmission, which thus reveals that DCB is an effective solution for enabling direct ground-space communications. Moreover, it reveals that the proposed algorithm achieves multiple policies favoring different objectives and achieving near-optimal uplink achievable rates with low switching frequency.
4/12/2024

Multi-UAV Multi-RIS QoS-Aware Aerial Communication Systems using DRL and PSO
Marwan Dhuheir, Aiman Erbad, Ala Al-Fuqaha, Mohsen Guizani
0
0
Recently, Unmanned Aerial Vehicles (UAVs) have attracted the attention of researchers in academia and industry for providing wireless services to ground users in diverse scenarios like festivals, large sporting events, natural and man-made disasters due to their advantages in terms of versatility and maneuverability. However, the limited resources of UAVs (e.g., energy budget and different service requirements) can pose challenges for adopting UAVs for such applications. Our system model considers a UAV swarm that navigates an area, providing wireless communication to ground users with RIS support to improve the coverage of the UAVs. In this work, we introduce an optimization model with the aim of maximizing the throughput and UAVs coverage through optimal path planning of UAVs and multi-RIS phase configurations. The formulated optimization is challenging to solve using standard linear programming techniques, limiting its applicability in real-time decision-making. Therefore, we introduce a two-step solution using deep reinforcement learning and particle swarm optimization. We conduct extensive simulations and compare our approach to two competitive solutions presented in the recent literature. Our simulation results demonstrate that our adopted approach is 20 % better than the brute-force approach and 30% better than the baseline solution in terms of QoS.
6/26/2024