Octopus: On-device language model for function calling of software APIs
2404.01549
0
0
Abstract
In the rapidly evolving domain of artificial intelligence, Large Language Models (LLMs) play a crucial role due to their advanced text processing and generation abilities. This study introduces a new strategy aimed at harnessing on-device LLMs in invoking software APIs. We meticulously compile a dataset derived from software API documentation and apply fine-tuning to LLMs with capacities of 2B, 3B and 7B parameters, specifically to enhance their proficiency in software API interactions. Our approach concentrates on refining the models' grasp of API structures and syntax, significantly enhancing the accuracy of API function calls. Additionally, we propose textit{conditional masking} techniques to ensure outputs in the desired formats and reduce error rates while maintaining inference speeds. We also propose a novel benchmark designed to evaluate the effectiveness of LLMs in API interactions, establishing a foundation for subsequent research. Octopus, the fine-tuned model, is proved to have better performance than GPT-4 for the software APIs calling. This research aims to advance automated software development and API integration, representing substantial progress in aligning LLM capabilities with the demands of practical software engineering applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Octopus is an on-device language model designed to assist software developers in calling API functions more efficiently.
- It aims to provide personalized API function recommendations based on the developer's current context and previous interactions.
- The key innovation is using a lightweight language model that can run directly on the developer's device, rather than requiring a remote server.
Plain English Explanation
Octopus is a tool that helps software developers write code more easily. When developers are working on a project, they often need to use pre-built functions, called APIs, provided by other software. Remembering all the different API functions and how to use them can be challenging.
Octopus uses artificial intelligence to learn about the developer's coding habits and preferences. It can then suggest relevant API functions the developer might want to use, based on the code they are currently writing. This saves the developer time and effort compared to manually searching through API documentation.
The key advantage of Octopus is that it runs directly on the developer's own computer or device. Many AI-based tools require sending data to a remote server for processing, but Octopus keeps everything local. This makes it faster and more secure, as the developer's code and information never leaves their device.
Technical Explanation
Octopus is built using a lightweight neural network language model that can be efficiently deployed on the developer's device. The model is trained on a large corpus of open-source code to learn patterns and associations between API function calls and the surrounding code context.
During use, Octopus monitors the developer's current code and uses the language model to predict which API functions would be most relevant to suggest next. It ranks the suggestions based on factors like code similarity, API call frequency, and the developer's personal usage history.
The researchers evaluated Octopus in a user study with professional developers. They found that using Octopus led to significantly faster API function discovery and higher developer productivity, compared to a baseline of manually searching API documentation.
Critical Analysis
The paper provides a thorough technical description of the Octopus system and presents compelling empirical results. However, some potential limitations are not addressed:
- The language model was trained on open-source code, which may not fully capture the unique coding styles and API usage patterns of individual developers or organizations. Further personalization may be required.
- The user study was relatively small in scale, so broader real-world validation is still needed to assess Octopus's generalizability and long-term impact.
- The paper does not discuss potential privacy or security concerns around Octopus monitoring developers' code, even if processing is done locally. Transparency and user control features may be important.
Overall, Octopus represents an innovative approach to enhancing developer productivity through on-device AI assistance. With further research and refinement, it could become a valuable tool in the software engineering workflow.
Conclusion
Octopus is an AI-powered system that helps software developers more efficiently discover and use API functions relevant to their current coding tasks. By running a compact language model directly on the developer's device, Octopus can provide personalized recommendations without compromising privacy or performance.
The technical work described in this paper demonstrates the potential for on-device AI to augment human abilities in software development and other knowledge-intensive domains. As AI systems become more sophisticated and accessible, integrating them seamlessly into users' workflows will be crucial. Octopus serves as an encouraging example of how this can be achieved.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Octopus v2: On-device language model for super agent
Wei Chen, Zhiyuan Li
0
0
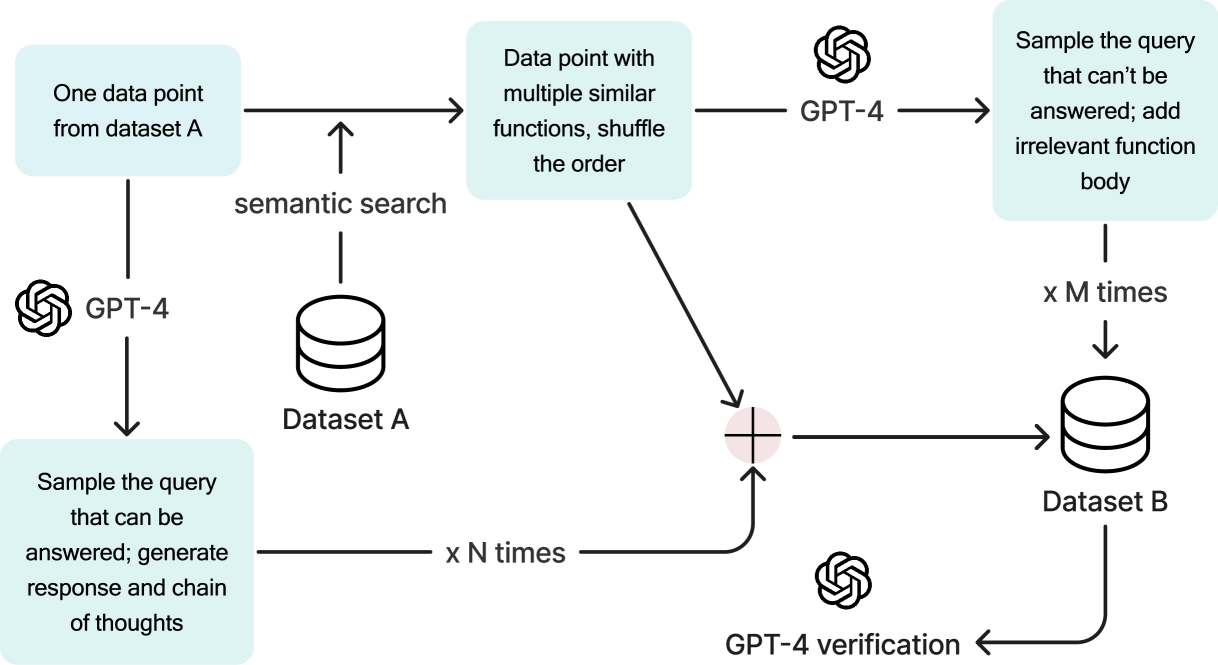
Language models have shown effectiveness in a variety of software applications, particularly in tasks related to automatic workflow. These models possess the crucial ability to call functions, which is essential in creating AI agents. Despite the high performance of large-scale language models in cloud environments, they are often associated with concerns over privacy and cost. Current on-device models for function calling face issues with latency and accuracy. Our research presents a new method that empowers an on-device model with 2 billion parameters to surpass the performance of GPT-4 in both accuracy and latency, and decrease the context length by 95%. When compared to Llama-7B with a RAG-based function calling mechanism, our method enhances latency by 35-fold. This method reduces the latency to levels deemed suitable for deployment across a variety of edge devices in production environments, aligning with the performance requisites for real-world applications.
4/17/2024
💬
Octopus v4: Graph of language models
Wei Chen, Zhiyuan Li
0
0
Language models have been effective in a wide range of applications, yet the most sophisticated models are often proprietary. For example, GPT-4 by OpenAI and various models by Anthropic are expensive and consume substantial energy. In contrast, the open-source community has produced competitive models, like Llama3. Furthermore, niche-specific smaller language models, such as those tailored for legal, medical or financial tasks, have outperformed their proprietary counterparts. This paper introduces a novel approach that employs textit{functional tokens} to integrate textbf{multiple open-source models}, each optimized for particular tasks. Our newly developed Octopus v4 model leverages textit{functional tokens} to intelligently direct user queries to the most appropriate vertical model and reformat the query to achieve the best performance. Octopus v4, an evolution of the Octopus v1, v2, and v3 models, excels in selection and parameter understanding and reformatting. Additionally, we explore the use of graph as a versatile data structure that effectively coordinates multiple open-source models by harnessing the capabilities of the Octopus model and textit{functional tokens}. Use our open-sourced GitHub (url{https://www.nexa4ai.com/}) to try Octopus v4 models (url{https://huggingface.co/NexaAIDev/Octopus-v4}), and contrite to a larger graph of language models. By activating models less than 10B parameters, we achieved SOTA MMLU score of 74.8 among the same level models.
5/1/2024
Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent
Wei Chen, Zhiyuan Li
0
0
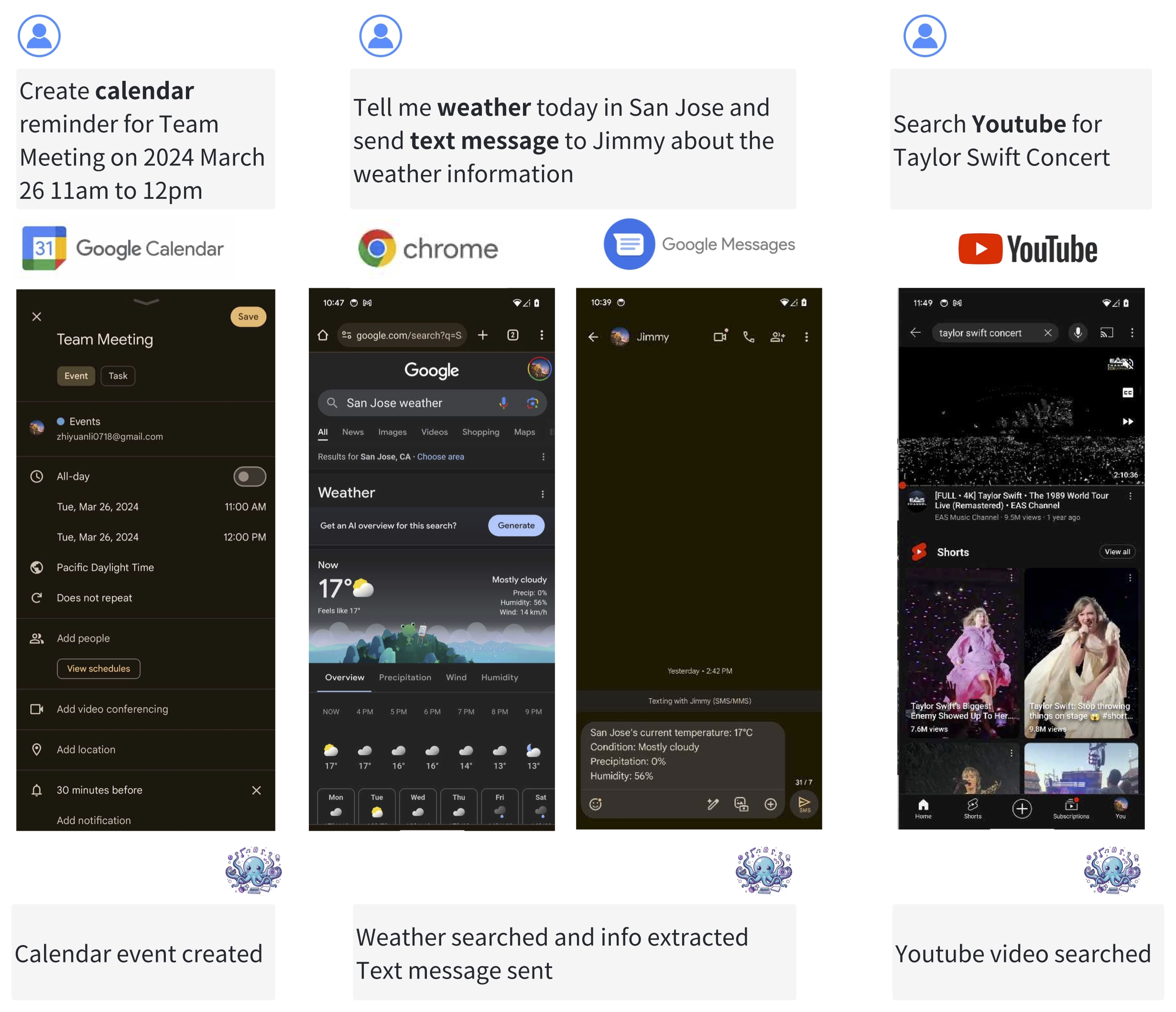
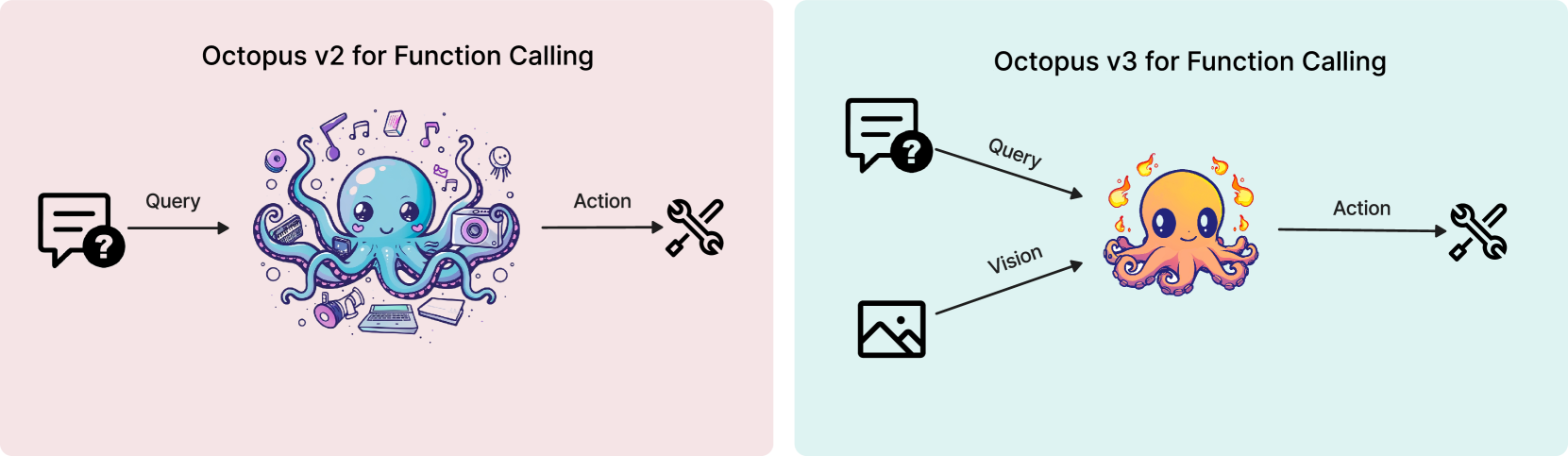
A multimodal AI agent is characterized by its ability to process and learn from various types of data, including natural language, visual, and audio inputs, to inform its actions. Despite advancements in large language models that incorporate visual data, such as GPT-4V, effectively translating image-based data into actionable outcomes for AI agents continues to be challenging. In this paper, we introduce a multimodal model that incorporates the concept of functional token specifically designed for AI agent applications. To ensure compatibility with edge devices, our model is optimized to a compact size of less than 1B parameters. Like GPT-4, our model can process both English and Chinese. We demonstrate that this model is capable of operating efficiently on a wide range of edge devices, including as constrained as a Raspberry Pi.
4/19/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024