Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
2404.02588
0
0
💬
Abstract
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores how large language models can be used to expand spoken language understanding systems to new languages.
- It investigates techniques for adapting language models trained on high-resource languages to low-resource languages, enabling the development of spoken language understanding capabilities in a wider range of languages.
- The research aims to address the challenge of limited availability of annotated data for training spoken language understanding models in many languages.
Plain English Explanation
Large language models are powerful artificial intelligence systems that can understand and generate human-like text. These models are typically trained on massive amounts of text data in one or more high-resource languages, such as English or Mandarin Chinese.
The researchers in this paper wanted to see if they could use these large language models to help build spoken language understanding systems for languages that don't have as much available data, known as low-resource languages. Spoken language understanding is the ability of a computer system to interpret and understand human speech.
Building these spoken language understanding systems can be challenging in low-resource languages because there isn't as much annotated data available to train the models. The researchers explored techniques to adapt the large language models trained on high-resource languages to work better for low-resource languages.
By leveraging the capabilities of large language models, the researchers aimed to enable the development of spoken language understanding systems in a wider range of languages, even those with limited available data. This could help make these technologies more accessible and inclusive for speakers of diverse languages around the world.
Technical Explanation
The paper presents a method for expanding spoken language understanding systems to new languages by leveraging large language models. The key elements of the research include:
Experiment Design: The researchers evaluated their approach on several low-resource languages, including Hindi, Vietnamese, and Amharic. They compared the performance of spoken language understanding models trained using their adaptation techniques to models trained solely on limited annotated data in the target low-resource languages.
Architecture: The researchers used a two-stage approach. First, they fine-tuned a pre-trained large language model on the target low-resource language using unsupervised pretraining. Then, they used this adapted language model to initialize a spoken language understanding model, which was further fine-tuned on any available annotated data in the low-resource language.
Key Insights: The results showed that the adapted language model-based approach significantly outperformed models trained solely on limited annotated data in the low-resource languages. This demonstrates the effectiveness of leveraging large language models to expand spoken language understanding capabilities to new languages with limited resources.
Critical Analysis
The paper acknowledges several caveats and limitations of the research. First, the performance improvements were dependent on the availability of some annotated data in the target low-resource languages, even if relatively small. The researchers note that further work is needed to reduce the reliance on any annotated data in the target language.
Additionally, the paper does not provide a detailed analysis of the types of errors or failures that may occur when applying this approach to very low-resource languages with highly distinctive linguistic characteristics. More research may be needed to understand the boundaries of when this technique can be effectively applied.
While the results are promising, the paper could have provided a more thorough discussion of potential ethical and societal implications of expanding spoken language understanding to a wider range of languages. Considerations around equitable access, privacy, and the risk of perpetuating biases in the underlying language models should be explored further.
Conclusion
This research demonstrates the potential of leveraging large language models to enable the expansion of spoken language understanding capabilities to low-resource languages. By adapting these powerful AI systems, the researchers were able to significantly improve performance on spoken language understanding tasks compared to models trained solely on limited data in the target languages.
This work represents an important step towards making spoken language technologies more accessible and inclusive for speakers of diverse languages around the world. However, additional research is needed to further reduce the reliance on any annotated data in the target languages and to carefully consider the ethical implications of this approach. Overall, the findings in this paper offer a promising direction for advancing the state of the art in multilingual spoken language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
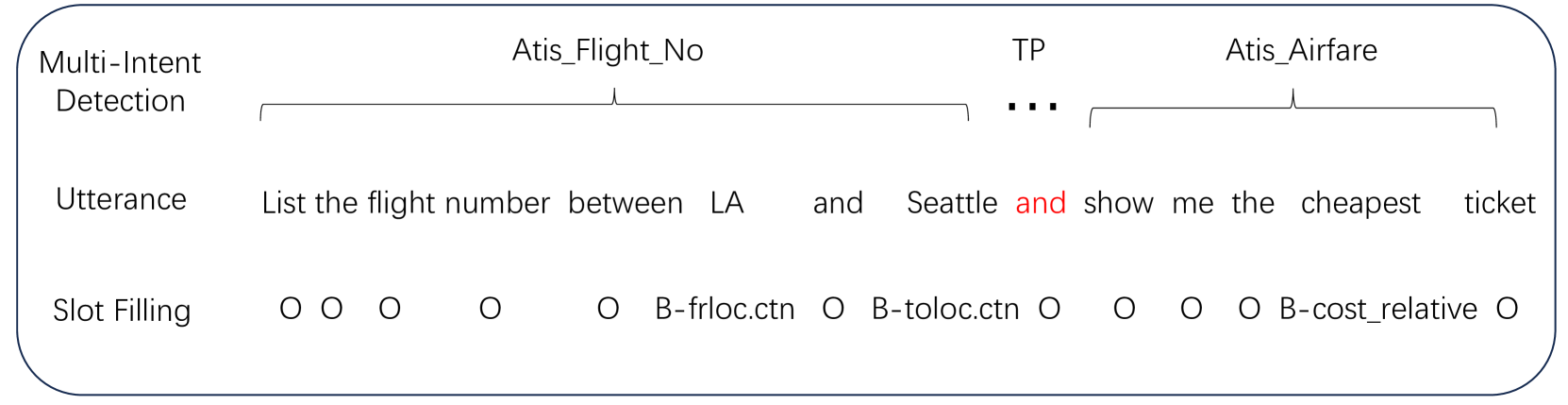
Do Large Language Model Understand Multi-Intent Spoken Language ?
Shangjian Yin, Peijie Huang, Yuhong Xu, Haojing Huang, Jiatian Chen
0
0
This research signifies a considerable breakthrough in leveraging Large Language Models (LLMs) for multi-intent spoken language understanding (SLU). Our approach re-imagines the use of entity slots in multi-intent SLU applications, making the most of the generative potential of LLMs within the SLU landscape, leading to the development of the EN-LLM series. Furthermore, we introduce the concept of Sub-Intent Instruction (SII) to amplify the analysis and interpretation of complex, multi-intent communications, which further supports the creation of the ENSI-LLM models series. Our novel datasets, identified as LM-MixATIS and LM-MixSNIPS, are synthesized from existing benchmarks. The study evidences that LLMs may match or even surpass the performance of the current best multi-intent SLU models. We also scrutinize the performance of LLMs across a spectrum of intent configurations and dataset distributions. On top of this, we present two revolutionary metrics - Entity Slot Accuracy (ESA) and Combined Semantic Accuracy (CSA) - to facilitate a detailed assessment of LLM competence in this multifaceted field. Our code and datasets are available at url{https://github.com/SJY8460/SLM}.
4/16/2024
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
💬
How good are Large Language Models on African Languages?
Jessica Ojo, Kelechi Ogueji, Pontus Stenetorp, David Ifeoluwa Adelani
0
0
Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on tasks and languages they are not trained on. However, their performance on African languages is largely understudied relative to high-resource languages. We present an analysis of four popular large language models (mT0, Aya, LLaMa 2, and GPT-4) on six tasks (topic classification, sentiment classification, machine translation, summarization, question answering, and named entity recognition) across 60 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce lower performance for African languages, and there is a large gap in performance compared to high-resource languages (such as English) for most tasks. We find that GPT-4 has an average to good performance on classification tasks, yet its performance on generative tasks such as machine translation and summarization is significantly lacking. Surprisingly, we find that mT0 had the best overall performance for cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Similarly, we find the recent Aya model to have comparable result to mT0 in almost all tasks except for topic classification where it outperform mT0. Overall, LLaMa 2 showed the worst performance, which we believe is due to its English and code-centric~(around 98%) pre-training corpus. Our findings confirms that performance on African languages continues to remain a hurdle for the current LLMs, underscoring the need for additional efforts to close this gap.
5/1/2024