OmniControlNet: Dual-stage Integration for Conditional Image Generation
2406.05871
0
0

Abstract
We provide a two-way integration for the widely adopted ControlNet by integrating external condition generation algorithms into a single dense prediction method and incorporating its individually trained image generation processes into a single model. Despite its tremendous success, the ControlNet of a two-stage pipeline bears limitations in being not self-contained (e.g. calls the external condition generation algorithms) with a large model redundancy (separately trained models for different types of conditioning inputs). Our proposed OmniControlNet consolidates 1) the condition generation (e.g., HED edges, depth maps, user scribble, and animal pose) by a single multi-tasking dense prediction algorithm under the task embedding guidance and 2) the image generation process for different conditioning types under the textual embedding guidance. OmniControlNet achieves significantly reduced model complexity and redundancy while capable of producing images of comparable quality for conditioned text-to-image generation.
Create account to get full access
Overview
- This paper introduces OmniControlNet, a dual-stage integration approach for conditional image generation that aims to improve control and consistency.
- OmniControlNet builds on previous work like ControlNet, SmartControl, and OmniControl to provide more flexible and efficient control over generated images.
- The system incorporates parallel token prediction and a modular design to enable control over various semantic attributes and visual elements at different stages of the generation process.
Plain English Explanation
OmniControlNet is a new approach for generating images based on specific instructions or conditions. It builds on previous research to give users more control and consistency over the generated images.
The key idea is to have a two-stage process. In the first stage, the system predicts different "tokens" or elements of the image in parallel. This allows it to capture various semantic attributes and visual details independently.
In the second stage, these tokens are integrated together in a modular fashion. This modular design provides flexibility - the user can control different aspects of the image, like the scene, objects, textures, etc., by adjusting the corresponding tokens.
Compared to earlier work, OmniControlNet offers more fine-grained and reliable control over the generated images. This could be useful for applications like controllable image generation, where users want to create specific images based on their instructions.
Technical Explanation
OmniControlNet builds on prior research like ControlNet, SmartControl, and OmniControl to introduce a dual-stage integration approach for conditional image generation.
The core architecture consists of two main components:
- Parallel Token Prediction: In the first stage, the system predicts various semantic and visual "tokens" in parallel. This includes scene, object, texture, and other relevant elements.
- Modular Integration: The predicted tokens are then integrated in a modular fashion in the second stage. This allows flexible control over different aspects of the generated image.
The modular design enables users to adjust specific tokens to control the corresponding visual elements. This provides more fine-grained and reliable control compared to earlier work.
The authors evaluate OmniControlNet on several standard image generation benchmarks and demonstrate improved performance in terms of control, consistency, and visual quality compared to state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and technically sound approach to conditional image generation. The dual-stage architecture with parallel token prediction and modular integration is a clever way to enhance control and consistency.
However, the authors do not address some potential limitations. For example, the computational complexity of the parallel token prediction stage may be a concern, especially for real-time applications. Additionally, the paper does not explore the limits of the system's control capabilities - there may be certain types of images or conditions that are difficult to generate with the current approach.
Further research could investigate ways to optimize the efficiency of the parallel prediction stage, as well as expand the range of controllable attributes and visual elements. Exploring the failure modes and robustness of the system under various input conditions would also be valuable.
Overall, OmniControlNet represents a significant advancement in conditional image generation, but there are still opportunities for improvement and further exploration.
Conclusion
In summary, the OmniControlNet paper introduces a novel dual-stage approach for conditional image generation that aims to provide more flexible and reliable control over the generated outputs. By incorporating parallel token prediction and a modular integration design, the system offers fine-grained control over various semantic and visual aspects of the images.
The technical evaluation demonstrates the effectiveness of this approach, and the modular nature of the architecture suggests potential for further enhancements and applications. While the paper does not address all possible limitations, it represents an important step forward in the field of controllable image generation, with promising implications for a wide range of visual AI systems and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen
0
0
To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.
4/12/2024

SmartControl: Enhancing ControlNet for Handling Rough Visual Conditions
Xiaoyu Liu, Yuxiang Wei, Ming Liu, Xianhui Lin, Peiran Ren, Xuansong Xie, Wangmeng Zuo
0
0
Human visual imagination usually begins with analogies or rough sketches. For example, given an image with a girl playing guitar before a building, one may analogously imagine how it seems like if Iron Man playing guitar before Pyramid in Egypt. Nonetheless, visual condition may not be precisely aligned with the imaginary result indicated by text prompt, and existing layout-controllable text-to-image (T2I) generation models is prone to producing degraded generated results with obvious artifacts. To address this issue, we present a novel T2I generation method dubbed SmartControl, which is designed to modify the rough visual conditions for adapting to text prompt. The key idea of our SmartControl is to relax the visual condition on the areas that are conflicted with text prompts. In specific, a Control Scale Predictor (CSP) is designed to identify the conflict regions and predict the local control scales, while a dataset with text prompts and rough visual conditions is constructed for training CSP. It is worth noting that, even with a limited number (e.g., 1,000~2,000) of training samples, our SmartControl can generalize well to unseen objects. Extensive experiments on four typical visual condition types clearly show the efficacy of our SmartControl against state-of-the-arts. Source code, pre-trained models, and datasets are available at https://github.com/liuxiaoyu1104/SmartControl.
4/10/2024
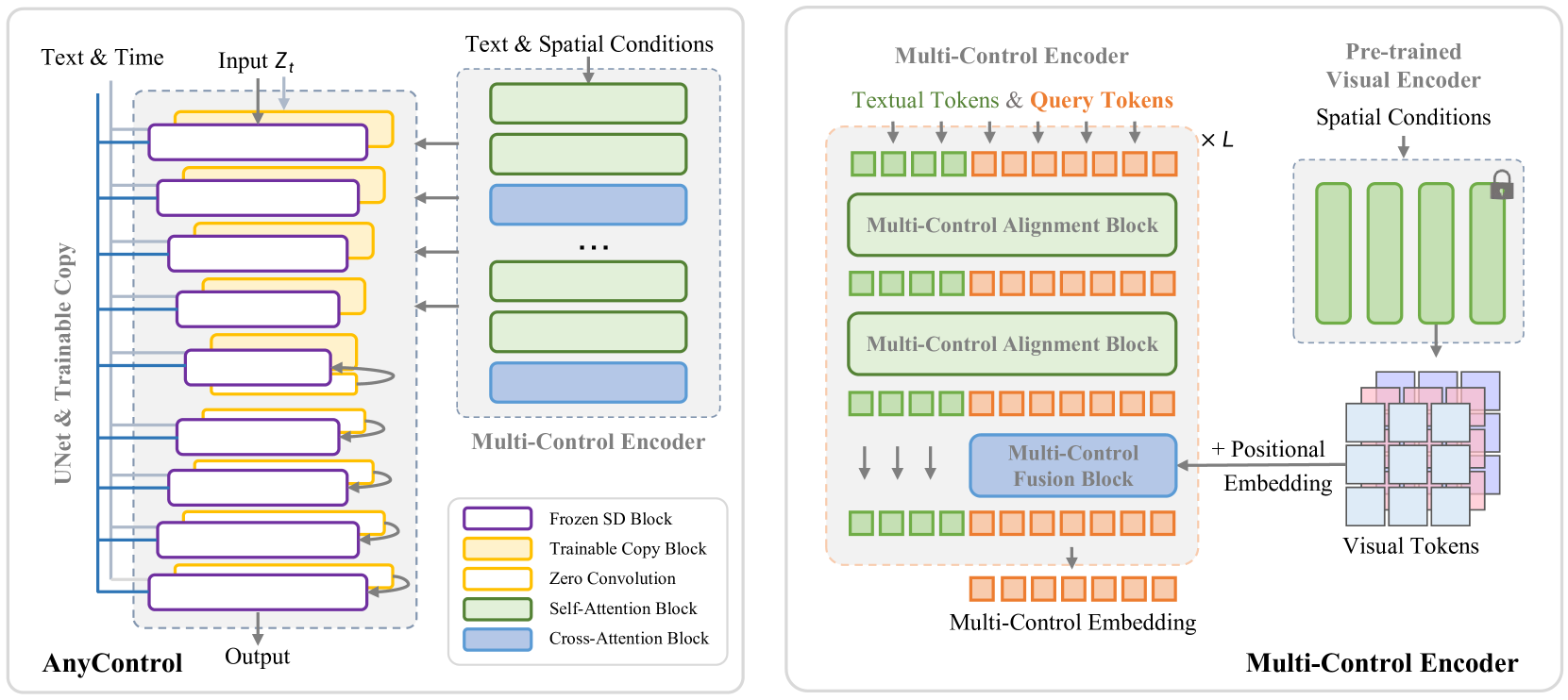
AnyControl: Create Your Artwork with Versatile Control on Text-to-Image Generation
Yanan Sun, Yanchen Liu, Yinhao Tang, Wenjie Pei, Kai Chen
0
0
The field of text-to-image (T2I) generation has made significant progress in recent years, largely driven by advancements in diffusion models. Linguistic control enables effective content creation, but struggles with fine-grained control over image generation. This challenge has been explored, to a great extent, by incorporating additional user-supplied spatial conditions, such as depth maps and edge maps, into pre-trained T2I models through extra encoding. However, multi-control image synthesis still faces several challenges. Specifically, current approaches are limited in handling free combinations of diverse input control signals, overlook the complex relationships among multiple spatial conditions, and often fail to maintain semantic alignment with provided textual prompts. This can lead to suboptimal user experiences. To address these challenges, we propose AnyControl, a multi-control image synthesis framework that supports arbitrary combinations of diverse control signals. AnyControl develops a novel Multi-Control Encoder that extracts a unified multi-modal embedding to guide the generation process. This approach enables a holistic understanding of user inputs, and produces high-quality, faithful results under versatile control signals, as demonstrated by extensive quantitative and qualitative evaluations. Our project page is available in https://any-control.github.io.
7/1/2024
🛸
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, Huaizu Jiang
0
0
We present a novel approach named OmniControl for incorporating flexible spatial control signals into a text-conditioned human motion generation model based on the diffusion process. Unlike previous methods that can only control the pelvis trajectory, OmniControl can incorporate flexible spatial control signals over different joints at different times with only one model. Specifically, we propose analytic spatial guidance that ensures the generated motion can tightly conform to the input control signals. At the same time, realism guidance is introduced to refine all the joints to generate more coherent motion. Both the spatial and realism guidance are essential and they are highly complementary for balancing control accuracy and motion realism. By combining them, OmniControl generates motions that are realistic, coherent, and consistent with the spatial constraints. Experiments on HumanML3D and KIT-ML datasets show that OmniControl not only achieves significant improvement over state-of-the-art methods on pelvis control but also shows promising results when incorporating the constraints over other joints.
4/16/2024