Controllable Image Generation With Composed Parallel Token Prediction
2405.06535
0
0
🖼️
Abstract
Compositional image generation requires models to generalise well in situations where two or more input concepts do not necessarily appear together in training (compositional generalisation). Despite recent progress in compositional image generation via composing continuous sampling processes such as diffusion and energy-based models, composing discrete generative processes has remained an open challenge, with the promise of providing improvements in efficiency, interpretability and simplicity. To this end, we propose a formulation for controllable conditional generation of images via composing the log-probability outputs of discrete generative models of the latent space. Our approach, when applied alongside VQ-VAE and VQ-GAN, achieves state-of-the-art generation accuracy in three distinct settings (FFHQ, Positional CLEVR and Relational CLEVR) while attaining competitive Fr'echet Inception Distance (FID) scores. Our method attains an average generation accuracy of $80.71%$ across the studied settings. Our method also outperforms the next-best approach (ranked by accuracy) in terms of FID in seven out of nine experiments, with an average FID of $24.23$ (an average improvement of $-9.58$). Furthermore, our method offers a $2.3times$ to $12times$ speedup over comparable continuous compositional methods on our hardware. We find that our method can generalise to combinations of input conditions that lie outside the training data (e.g. more objects per image) in addition to offering an interpretable dimension of controllability via concept weighting. We further demonstrate that our approach can be readily applied to an open pre-trained discrete text-to-image model without any fine-tuning, allowing for fine-grained control of text-to-image generation.
Create account to get full access
Overview
- The paper proposes a method for controllable conditional generation of images by composing the log-probability outputs of discrete generative models of the latent space.
- This approach is applied to VQ-VAE and VQ-GAN models, achieving state-of-the-art generation accuracy in several settings while also attaining competitive FID scores.
- The method offers improvements in efficiency, interpretability, and simplicity compared to continuous compositional methods.
- The approach can generalize to combinations of input conditions outside the training data and offers fine-grained control of text-to-image generation.
Plain English Explanation
The paper describes a new way to generate images that combines the power of different machine learning models. Traditionally, generating images by combining multiple concepts (like an image of a red car and a blue house) has been challenging, as the models may not have seen those specific combinations before.
The researchers propose a method that uses the outputs of discrete generative models (models that work with discrete or "digital" representations) to create these combined images. This approach is more efficient, easier to understand, and simpler to use than previous methods that relied on continuous processes.
When applied to existing models like VQ-VAE and VQ-GAN, this new method achieves top-notch performance in generating accurate images that match the desired concept combinations. It can also handle combinations that were not seen during training, and it allows for fine-grained control over the generation process, such as adjusting the relative importance of different concepts.
The key insight is that by composing the log-probability outputs of discrete generative models, the researchers can create images that combine multiple input concepts in a flexible and efficient way. This opens up new possibilities for applications that require precise control over the generated images, such as text-to-image generation.
Technical Explanation
The paper proposes a formulation for controllable conditional generation of images by composing the log-probability outputs of discrete generative models of the latent space. This approach is applied to VQ-VAE and VQ-GAN models, achieving state-of-the-art generation accuracy in three distinct settings (FFHQ, Positional CLEVR, and Relational CLEVR) while also attaining competitive Fréchet Inception Distance (FID) scores.
The key idea is to leverage the discrete nature of the latent representations learned by these models to enable efficient and interpretable compositional generation. This stands in contrast to previous work that has focused on composing continuous sampling processes, such as diffusion models and energy-based models.
The researchers find that their method can generalize to combinations of input conditions that lie outside the training data, in addition to offering an interpretable dimension of controllability via concept weighting. They also demonstrate that the approach can be readily applied to an open pre-trained discrete text-to-image model without any fine-tuning, allowing for fine-grained control of text-to-image generation.
Compared to previous continuous compositional methods, the proposed approach achieves a 2.3x to 12x speedup on the researchers' hardware, highlighting its efficiency and potential for real-world applications.
Critical Analysis
The paper presents a compelling approach to compositional image generation, which addresses an important challenge in the field. The authors demonstrate the effectiveness of their method across several benchmark tasks, and the results are impressive, both in terms of generation accuracy and efficiency.
One potential limitation is that the paper focuses on discrete generative models, which may not be as expressive or flexible as continuous models in certain scenarios. The authors acknowledge this and suggest that future work could explore hybrid approaches that combine the strengths of both discrete and continuous models.
Additionally, while the paper showcases the ability to generalize to unseen combinations of input conditions, it would be interesting to see how the method performs on more open-ended and diverse image generation tasks, where the range of possible compositions is even broader.
The authors also note that their approach offers an interpretable dimension of controllability, which is a valuable property. However, further research could explore ways to make the control mechanism even more intuitive and user-friendly, especially for non-technical users.
Overall, the paper presents a significant contribution to the field of compositional image generation, and the proposed method offers a promising direction for future research and real-world applications. Readers are encouraged to critically evaluate the work and consider its implications in the context of their own interests and needs.
Conclusion
The paper introduces a novel approach for controllable conditional generation of images by composing the log-probability outputs of discrete generative models. This method addresses the challenge of compositional generalization, where models need to combine multiple input concepts that may not have appeared together during training.
The proposed approach, when applied to VQ-VAE and VQ-GAN models, achieves state-of-the-art generation accuracy while also attaining competitive FID scores. It offers advantages in terms of efficiency, interpretability, and simplicity compared to previous continuous compositional methods.
The researchers demonstrate that their method can generalize to combinations of input conditions outside the training data and provide fine-grained control over text-to-image generation. This work opens up new possibilities for applications that require precise control over generated images, such as personalized content creation and multi-aspect controllable generation.
The paper's contributions and insights contribute to the ongoing efforts in the field of compositional image generation, paving the way for further advancements and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024
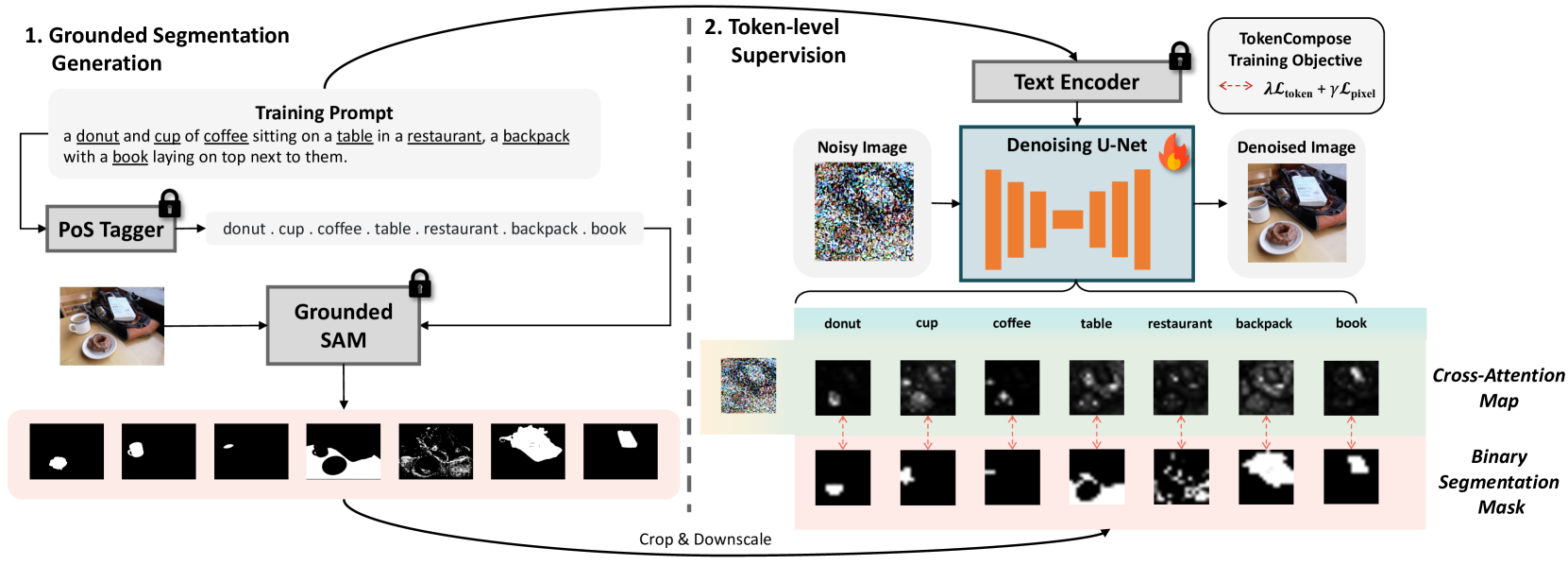
TokenCompose: Text-to-Image Diffusion with Token-level Supervision
Zirui Wang, Zhizhou Sha, Zheng Ding, Yilin Wang, Zhuowen Tu
0
0
We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images. Project link: https://mlpc-ucsd.github.io/TokenCompose
6/26/2024
🛸
GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, Deva Ramanan
0
0
While text-to-visual models now produce photo-realistic images and videos, they struggle with compositional text prompts involving attributes, relationships, and higher-order reasoning such as logic and comparison. In this work, we conduct an extensive human study on GenAI-Bench to evaluate the performance of leading image and video generation models in various aspects of compositional text-to-visual generation. We also compare automated evaluation metrics against our collected human ratings and find that VQAScore -- a metric measuring the likelihood that a VQA model views an image as accurately depicting the prompt -- significantly outperforms previous metrics such as CLIPScore. In addition, VQAScore can improve generation in a black-box manner (without finetuning) via simply ranking a few (3 to 9) candidate images. Ranking by VQAScore is 2x to 3x more effective than other scoring methods like PickScore, HPSv2, and ImageReward at improving human alignment ratings for DALL-E 3 and Stable Diffusion, especially on compositional prompts that require advanced visio-linguistic reasoning. We will release a new GenAI-Rank benchmark with over 40,000 human ratings to evaluate scoring metrics on ranking images generated from the same prompt. Lastly, we discuss promising areas for improvement in VQAScore, such as addressing fine-grained visual details. We will release all human ratings (over 80,000) to facilitate scientific benchmarking of both generative models and automated metrics.
6/26/2024
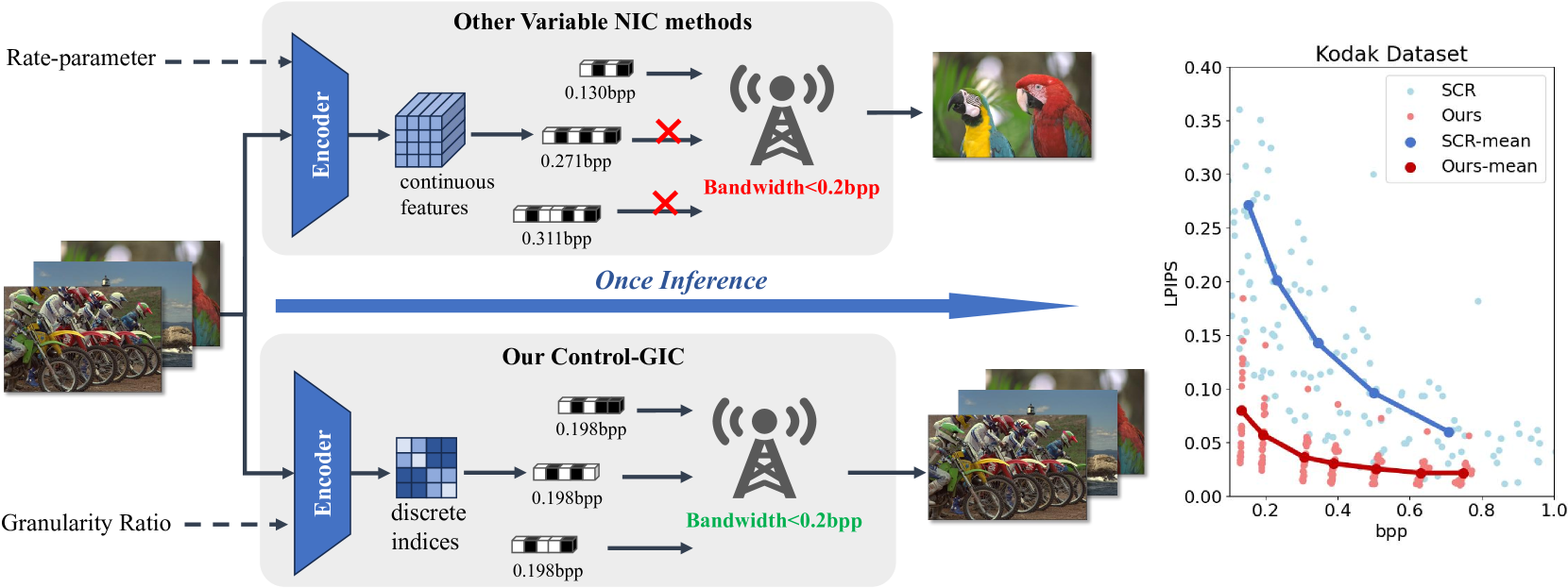
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Anqi Li, Yuxi Liu, Huihui Bai, Feng Li, Runmin Cong, Meng Wang, Yao Zhao
0
0
Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
6/6/2024