One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features

0

Sign in to get full access
Overview
- This paper proposes a one-stage open-vocabulary temporal action detection model that leverages temporal multi-scale and action label features.
- The model aims to detect temporal action instances in untrimmed videos without relying on pre-defined action classes.
- It introduces several key innovations, including a multi-scale temporal feature pyramid and an action label feature module, to enhance the model's performance.
Plain English Explanation
The paper describes a new approach for automatically detecting and locating specific actions within longer video clips. This is an important task in computer vision, as it allows systems to understand the activities occurring in a video and when they happen.
The proposed model is "one-stage", meaning it can perform the detection and localization in a single step, without requiring multiple separate stages. It is also "open-vocabulary", which means it can detect actions without being limited to a pre-defined set of action classes. This makes the model more flexible and adaptable to different domains.
The key innovations in the model include:
-
Temporal Multi-scale Features: The model extracts features at multiple time scales within the video, allowing it to capture both short-term and long-term patterns in the actions.
-
Action Label Features: The model also incorporates information about the specific action labels, which helps it better distinguish between different types of activities.
By leveraging these multi-scale temporal features and action-specific information, the model is able to more accurately and efficiently detect and localize actions in untrimmed video clips, without being constrained to a fixed set of predefined actions.
Technical Explanation
The paper introduces a One-Stage Open-Vocabulary Temporal Action Detection (OS-OVTAD) model that can detect and localize actions in untrimmed videos without relying on pre-defined action classes. The key innovations of the model include:
-
Temporal Multi-scale Feature Pyramid: The model uses a feature pyramid network to extract features at multiple temporal scales, allowing it to capture both short-term and long-term patterns in the video. This is in contrast to prior work that often only used features at a single time scale.
-
Action Label Feature Module: In addition to the visual features, the model also incorporates action label features, which provide additional semantic information about the specific actions being performed. This helps the model better distinguish between different types of activities.
The model is trained in an end-to-end fashion, optimizing both the temporal action detection and the open-vocabulary classification simultaneously. The authors evaluate the OS-OVTAD model on several standard action detection benchmarks, demonstrating significant improvements over previous state-of-the-art methods.
Critical Analysis
The authors have made a strong contribution to the field of temporal action detection by developing a flexible, open-vocabulary model that can operate in a single stage. The use of multi-scale temporal features and action label features is a clever approach to enhance the model's performance.
However, the paper does not address some potential limitations of the approach. For instance, the model may struggle with long-range dependencies or actions that occur over very extended durations in the video. Additionally, the open-vocabulary capability relies on having a diverse set of action labels available during training, which may not always be the case in real-world scenarios.
Further research could explore ways to make the model more robust to these types of challenges, such as by incorporating attention mechanisms or few-shot learning techniques. Evaluating the model's performance on more diverse and realistic video datasets would also help validate its practical applicability.
Conclusion
This paper presents a novel one-stage, open-vocabulary temporal action detection model that leverages temporal multi-scale features and action label information. The key innovations, including the feature pyramid and action label modules, allow the model to outperform previous state-of-the-art methods on benchmark datasets.
While the paper makes a valuable contribution to the field, there are still opportunities to further improve the model's capabilities and robustness. Ongoing research in this area has the potential to enable more sophisticated and adaptable video understanding systems that can be applied across a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, Ichiro Ide
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
Read more5/1/2024
0
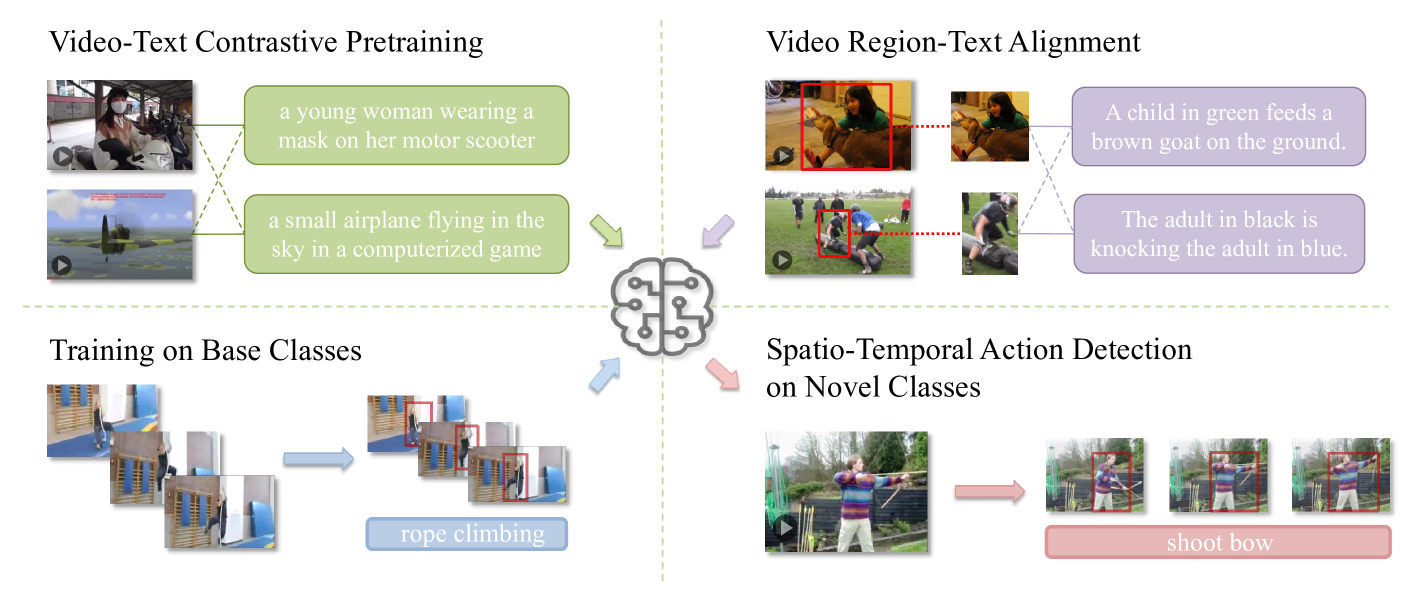
Open-Vocabulary Spatio-Temporal Action Detection
Tao Wu, Shuqiu Ge, Jie Qin, Gangshan Wu, Limin Wang
Spatio-temporal action detection (STAD) is an important fine-grained video understanding task. Current methods require box and label supervision for all action classes in advance. However, in real-world applications, it is very likely to come across new action classes not seen in training because the action category space is large and hard to enumerate. Also, the cost of data annotation and model training for new classes is extremely high for traditional methods, as we need to perform detailed box annotations and re-train the whole network from scratch. In this paper, we propose a new challenging setting by performing open-vocabulary STAD to better mimic the situation of action detection in an open world. Open-vocabulary spatio-temporal action detection (OV-STAD) requires training a model on a limited set of base classes with box and label supervision, which is expected to yield good generalization performance on novel action classes. For OV-STAD, we build two benchmarks based on the existing STAD datasets and propose a simple but effective method based on pretrained video-language models (VLM). To better adapt the holistic VLM for the fine-grained action detection task, we carefully fine-tune it on the localized video region-text pairs. This customized fine-tuning endows the VLM with better motion understanding, thus contributing to a more accurate alignment between video regions and texts. Local region feature and global video feature fusion before alignment is adopted to further improve the action detection performance by providing global context. Our method achieves a promising performance on novel classes.
Read more5/20/2024

0
Open-Vocabulary Temporal Action Localization using Multimodal Guidance
Akshita Gupta, Aditya Arora, Sanath Narayan, Salman Khan, Fahad Shahbaz Khan, Graham W. Taylor
Open-Vocabulary Temporal Action Localization (OVTAL) enables a model to recognize any desired action category in videos without the need to explicitly curate training data for all categories. However, this flexibility poses significant challenges, as the model must recognize not only the action categories seen during training but also novel categories specified at inference. Unlike standard temporal action localization, where training and test categories are predetermined, OVTAL requires understanding contextual cues that reveal the semantics of novel categories. To address these challenges, we introduce OVFormer, a novel open-vocabulary framework extending ActionFormer with three key contributions. First, we employ task-specific prompts as input to a large language model to obtain rich class-specific descriptions for action categories. Second, we introduce a cross-attention mechanism to learn the alignment between class representations and frame-level video features, facilitating the multimodal guided features. Third, we propose a two-stage training strategy which includes training with a larger vocabulary dataset and finetuning to downstream data to generalize to novel categories. OVFormer extends existing TAL methods to open-vocabulary settings. Comprehensive evaluations on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our method. Code and pretrained models will be publicly released.
Read more6/26/2024

0
Harnessing Temporal Causality for Advanced Temporal Action Detection
Shuming Liu, Lin Sui, Chen-Lin Zhang, Fangzhou Mu, Chen Zhao, Bernard Ghanem
As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
Read more7/29/2024