Open Problem: Order Optimal Regret Bounds for Kernel-Based Reinforcement Learning
2406.15250
0
0
🏅
Abstract
Reinforcement Learning (RL) has shown great empirical success in various application domains. The theoretical aspects of the problem have been extensively studied over past decades, particularly under tabular and linear Markov Decision Process structures. Recently, non-linear function approximation using kernel-based prediction has gained traction. This approach is particularly interesting as it naturally extends the linear structure, and helps explain the behavior of neural-network-based models at their infinite width limit. The analytical results however do not adequately address the performance guarantees for this case. We will highlight this open problem, overview existing partial results, and discuss related challenges.
Create account to get full access
Overview
- This paper proposes a new approach to reinforcement learning (RL) that aims to achieve order-optimal regret bounds, which measure the performance of an RL algorithm compared to the optimal policy.
- The authors focus on episodic Markov Decision Processes (MDPs), where an agent interacts with an environment for a fixed number of time steps and then the episode ends.
- They develop a kernel-based RL algorithm that leverages function approximation to learn the optimal policy, with the goal of achieving regret bounds that are optimal in terms of the underlying problem parameters.
Plain English Explanation
The paper is about a new approach to reinforcement learning, which is a type of machine learning where an agent (like a robot or computer program) learns to make decisions by interacting with an environment and receiving rewards or penalties. The researchers are particularly interested in a setting called "episodic MDPs," where the agent interacts with the environment for a fixed number of time steps, and then the interaction ends and starts over.
The key idea is to use a technique called "kernel-based function approximation" to help the agent learn the optimal policy (the best way to make decisions) more efficiently. Kernel-based methods are a way of representing complex functions using a simple set of basis functions, which can make the learning process faster and more accurate.
The researchers' goal is to develop an RL algorithm that can achieve "order-optimal regret bounds," which means that the algorithm's performance is as good as the best possible algorithm for that problem, up to a constant factor. This is an important goal because it means the algorithm is leveraging all the available information in the most efficient way possible.
By achieving order-optimal regret bounds, the researchers hope to advance the state of the art in reinforcement learning and enable more effective and reliable decision-making in a wide range of applications, from robotics to finance to healthcare.
Technical Explanation
The paper focuses on the problem of reinforcement learning in episodic Markov Decision Processes (MDPs), where an agent interacts with an environment for a fixed number of time steps, and then the episode ends, and a new episode begins.
The authors propose a kernel-based RL algorithm that uses function approximation to learn the optimal policy. The key idea is to represent the value function (which measures the expected future reward for a given state-action pair) as a linear combination of kernel functions, which can capture complex nonlinear relationships in the data.
The authors analyze the regret of their proposed algorithm, which measures how much worse it performs compared to the optimal policy. They show that their algorithm can achieve order-optimal regret bounds, meaning that its regret is within a constant factor of the best possible regret for that problem. This is an important result, as it means the algorithm is leveraging all the available information as efficiently as possible.
The authors' analysis builds on recent advances in offline reinforcement learning and linear function approximation, as well as techniques from kernel-based learning and black-box optimization.
Critical Analysis
The paper presents a promising approach to achieving order-optimal regret bounds in episodic MDPs, but there are a few potential limitations and areas for further research:
-
Dependence on Kernel Functions: The algorithm's performance relies heavily on the choice of kernel function, which can be challenging to optimize in practice. The authors acknowledge this and suggest exploring more adaptive kernel selection methods.
-
Computational Complexity: The algorithm may have high computational requirements, especially as the size of the state and action spaces grow. The authors mention that further work is needed to address the scalability of the approach.
-
Sensitivity to Hyperparameters: The algorithm likely has several hyperparameters (e.g., kernel parameters, regularization coefficients) that need to be tuned carefully for good performance. The authors do not provide extensive guidance on how to set these hyperparameters in practice.
-
Assumption of Known Kernel Bandwidth: The analysis assumes that the kernel bandwidth (a parameter that controls the smoothness of the value function approximation) is known in advance. In many real-world applications, this may not be the case, and the algorithm may need to be extended to handle unknown kernel bandwidths.
Despite these potential limitations, the paper represents an important step forward in the development of RL algorithms with strong theoretical guarantees. By leveraging kernel-based function approximation and building on recent advances in offline RL and linear function approximation, the authors have proposed a promising approach that could have significant impact on the field.
Conclusion
The paper "Open Problem: Order Optimal Regret Bounds for Kernel-Based Reinforcement Learning" presents a new kernel-based reinforcement learning algorithm that can achieve order-optimal regret bounds in episodic Markov Decision Processes. This is an important result, as it means the algorithm can learn the optimal policy as efficiently as possible, within a constant factor of the best possible performance.
The authors' approach builds on recent advances in offline reinforcement learning, linear function approximation, and kernel-based learning, demonstrating the power of combining these techniques. While the algorithm may have some practical limitations, such as sensitivity to hyperparameters and computational complexity, the paper represents a significant contribution to the field of reinforcement learning and could pave the way for more efficient and reliable decision-making in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Asymptotically Optimal Regret for Black-Box Predict-then-Optimize
Samuel Tan, Peter I. Frazier
0
0
We consider the predict-then-optimize paradigm for decision-making in which a practitioner (1) trains a supervised learning model on historical data of decisions, contexts, and rewards, and then (2) uses the resulting model to make future binary decisions for new contexts by finding the decision that maximizes the model's predicted reward. This approach is common in industry. Past analysis assumes that rewards are observed for all actions for all historical contexts, which is possible only in problems with special structure. Motivated by problems from ads targeting and recommender systems, we study new black-box predict-then-optimize problems that lack this special structure and where we only observe the reward from the action taken. We present a novel loss function, which we call Empirical Soft Regret (ESR), designed to significantly improve reward when used in training compared to classical accuracy-based metrics like mean-squared error. This loss function targets the regret achieved when taking a suboptimal decision; because the regret is generally not differentiable, we propose a differentiable soft regret term that allows the use of neural networks and other flexible machine learning models dependent on gradient-based training. In the particular case of paired data, we show theoretically that optimizing our loss function yields asymptotically optimal regret within the class of supervised learning models. We also show our approach significantly outperforms state-of-the-art algorithms on real-world decision-making problems in news recommendation and personalized healthcare compared to benchmark methods from contextual bandits and conditional average treatment effect estimation.
6/13/2024
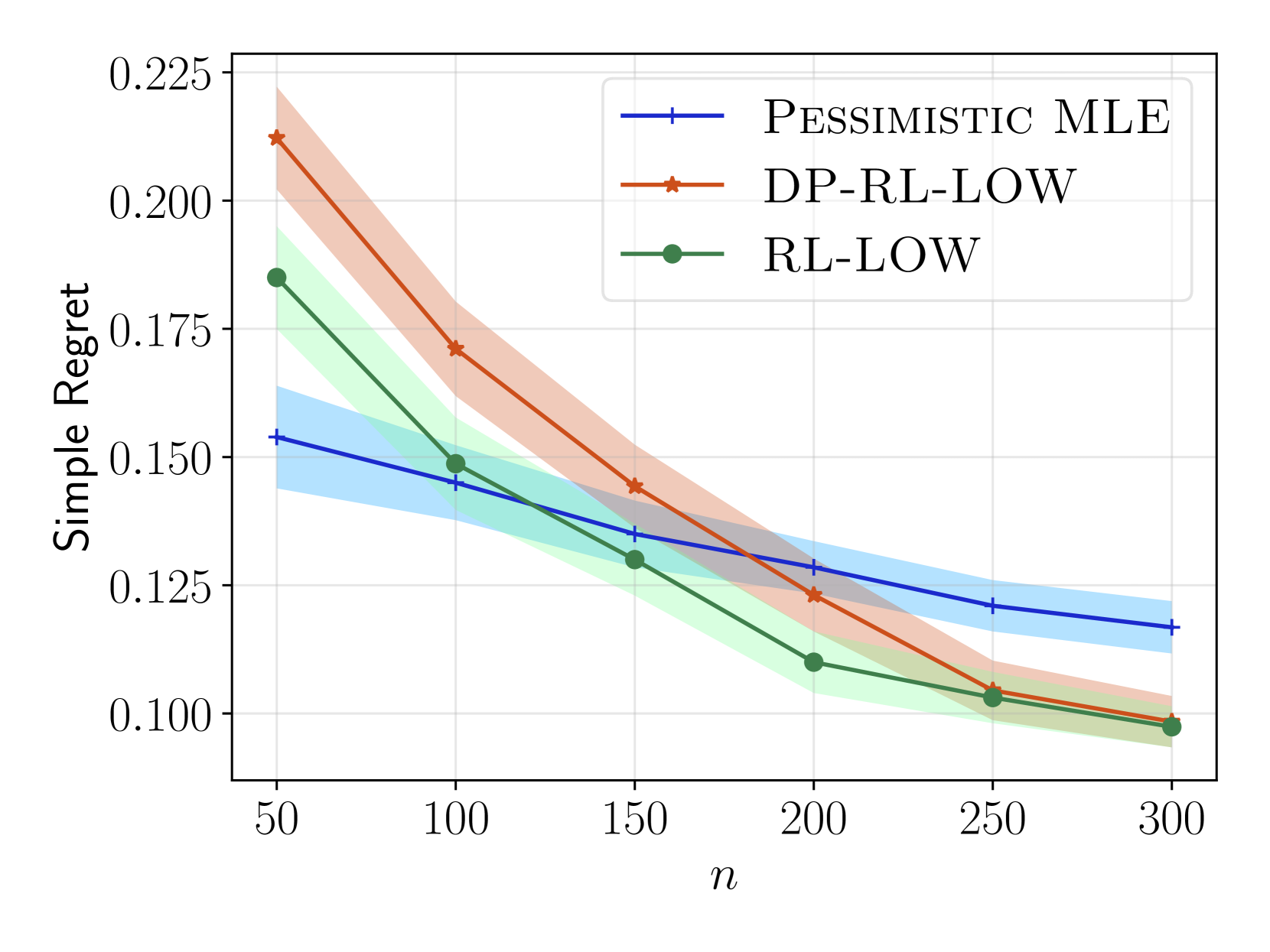
Order-Optimal Instance-Dependent Bounds for Offline Reinforcement Learning with Preference Feedback
Zhirui Chen, Vincent Y. F. Tan
0
0
We consider offline reinforcement learning (RL) with preference feedback in which the implicit reward is a linear function of an unknown parameter. Given an offline dataset, our objective consists in ascertaining the optimal action for each state, with the ultimate goal of minimizing the {em simple regret}. We propose an algorithm, underline{RL} with underline{L}ocally underline{O}ptimal underline{W}eights or {sc RL-LOW}, which yields a simple regret of $exp ( - Omega(n/H) )$ where $n$ is the number of data samples and $H$ denotes an instance-dependent hardness quantity that depends explicitly on the suboptimality gap of each action. Furthermore, we derive a first-of-its-kind instance-dependent lower bound in offline RL with preference feedback. Interestingly, we observe that the lower and upper bounds on the simple regret match order-wise in the exponent, demonstrating order-wise optimality of {sc RL-LOW}. In view of privacy considerations in practical applications, we also extend {sc RL-LOW} to the setting of $(varepsilon,delta)$-differential privacy and show, somewhat surprisingly, that the hardness parameter $H$ is unchanged in the asymptotic regime as $n$ tends to infinity; this underscores the inherent efficiency of {sc RL-LOW} in terms of preserving the privacy of the observed rewards. Given our focus on establishing instance-dependent bounds, our work stands in stark contrast to previous works that focus on establishing worst-case regrets for offline RL with preference feedback.
6/19/2024
🏅
Provably Efficient Reinforcement Learning with Multinomial Logit Function Approximation
Long-Fei Li, Yu-Jie Zhang, Peng Zhao, Zhi-Hua Zhou
0
0
We study a new class of MDPs that employs multinomial logit (MNL) function approximation to ensure valid probability distributions over the state space. Despite its benefits, introducing non-linear function approximation raises significant challenges in both computational and statistical efficiency. The best-known method of Hwang and Oh [2023] has achieved an $widetilde{mathcal{O}}(kappa^{-1}dH^2sqrt{K})$ regret, where $kappa$ is a problem-dependent quantity, $d$ is the feature space dimension, $H$ is the episode length, and $K$ is the number of episodes. While this result attains the same rate in $K$ as the linear cases, the method requires storing all historical data and suffers from an $mathcal{O}(K)$ computation cost per episode. Moreover, the quantity $kappa$ can be exponentially small, leading to a significant gap for the regret compared to the linear cases. In this work, we first address the computational concerns by proposing an online algorithm that achieves the same regret with only $mathcal{O}(1)$ computation cost. Then, we design two algorithms that leverage local information to enhance statistical efficiency. They not only maintain an $mathcal{O}(1)$ computation cost per episode but achieve improved regrets of $widetilde{mathcal{O}}(kappa^{-1/2}dH^2sqrt{K})$ and $widetilde{mathcal{O}}(dH^2sqrt{K} + kappa^{-1}d^2H^2)$ respectively. Finally, we establish a lower bound, justifying the optimality of our results in $d$ and $K$. To the best of our knowledge, this is the first work that achieves almost the same computational and statistical efficiency as linear function approximation while employing non-linear function approximation for reinforcement learning.
5/28/2024
🛠️
Rate-Optimal Policy Optimization for Linear Markov Decision Processes
Uri Sherman, Alon Cohen, Tomer Koren, Yishay Mansour
0
0
We study regret minimization in online episodic linear Markov Decision Processes, and obtain rate-optimal $widetilde O (sqrt K)$ regret where $K$ denotes the number of episodes. Our work is the first to establish the optimal (w.r.t.~$K$) rate of convergence in the stochastic setting with bandit feedback using a policy optimization based approach, and the first to establish the optimal (w.r.t.~$K$) rate in the adversarial setup with full information feedback, for which no algorithm with an optimal rate guarantee is currently known.
5/17/2024