Order-Optimal Instance-Dependent Bounds for Offline Reinforcement Learning with Preference Feedback

0
Sign in to get full access
Overview
- This paper presents a new approach for offline reinforcement learning (RL) using preference feedback, where the agent learns from comparisons between trajectories rather than numeric rewards.
- The authors provide order-optimal instance-dependent bounds for the sample complexity of their method, showing it can achieve near-optimal performance compared to the best possible offline RL algorithm.
- The proposed algorithm extends previous work on online bandit learning from offline preference data and unified linear programming for offline reward learning.
Plain English Explanation
The paper tackles the problem of reinforcement learning (RL) in a setting where the agent doesn't have access to numeric rewards, but instead can only compare different trajectories or sequences of actions. This is a more realistic scenario in many real-world applications, where humans may provide feedback in the form of preferences rather than precise numerical scores.
The key innovation is a new algorithm that can learn an optimal policy from this "preference feedback" data, without requiring the full numeric reward function. The authors prove that their method can achieve near-optimal performance, meaning it performs almost as well as the best possible algorithm that could be designed for this problem.
This builds on previous work that has looked at learning from offline preference data in bandit problems and at unified frameworks for offline reward learning. The new algorithm extends these ideas to the more complex setting of full reinforcement learning.
Technical Explanation
The core technical contribution of the paper is a new algorithm for offline RL with preference feedback. The key steps are:
- The agent first collects a dataset of preference comparisons between different trajectories, without access to the true reward function.
- The algorithm then uses a novel linear programming formulation to learn a reward function that is consistent with the observed preferences.
- Finally, the agent plans an optimal policy using this learned reward function, in a manner similar to offline policy evaluation techniques.
The authors provide a thorough theoretical analysis, proving order-optimal instance-dependent bounds on the sample complexity of this approach. This means the number of preference comparisons required scales optimally with the problem complexity, matching the best possible performance that could be achieved.
The algorithm also has connections to online iterative RL from human feedback and primal-dual methods for offline constrained RL, but with key differences tailored to the preference feedback setting.
Critical Analysis
The paper makes a compelling theoretical contribution, but as with any research, there are some caveats and limitations to consider:
- The analysis assumes the preference dataset satisfies certain structural properties, which may not always hold in practice. Further empirical validation would be helpful.
- The algorithm requires solving a challenging linear program, which could be computationally expensive for large problems. More efficient approximate solvers may be needed.
- The paper does not consider potential biases or noise in the preference feedback provided by humans. Robust approaches to handling imperfect preference data would be an important direction.
Overall, the work represents an important advance in offline RL, showing how powerful algorithms can be developed even when the agent has access to preference information rather than numeric rewards. But there remain opportunities to further refine and expand on these techniques for real-world applicability.
Conclusion
This paper presents a novel approach for offline reinforcement learning using preference feedback, with strong theoretical guarantees on its performance. By shifting the problem formulation away from numeric rewards and towards relative comparisons, the authors have opened up new possibilities for RL in settings where precise rewards may be difficult to obtain.
The core technical innovation - a linear programming-based algorithm with order-optimal sample complexity - extends previous work on bandit learning and offline reward learning. While some practical challenges remain, this research represents an important step towards making reinforcement learning more accessible and applicable in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Order-Optimal Instance-Dependent Bounds for Offline Reinforcement Learning with Preference Feedback
Zhirui Chen, Vincent Y. F. Tan
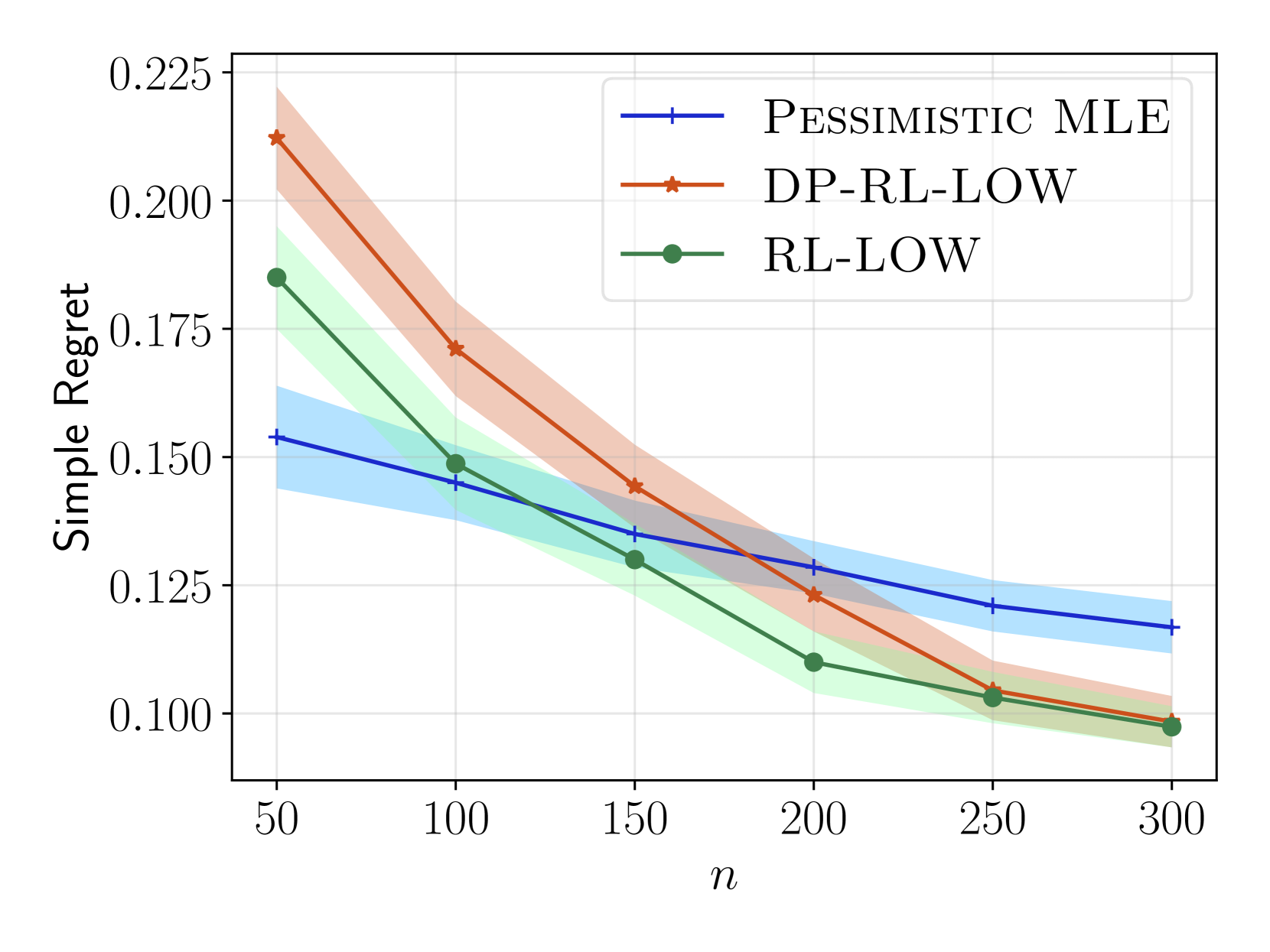
We consider offline reinforcement learning (RL) with preference feedback in which the implicit reward is a linear function of an unknown parameter. Given an offline dataset, our objective consists in ascertaining the optimal action for each state, with the ultimate goal of minimizing the {em simple regret}. We propose an algorithm, underline{RL} with underline{L}ocally underline{O}ptimal underline{W}eights or {sc RL-LOW}, which yields a simple regret of $exp ( - Omega(n/H) )$ where $n$ is the number of data samples and $H$ denotes an instance-dependent hardness quantity that depends explicitly on the suboptimality gap of each action. Furthermore, we derive a first-of-its-kind instance-dependent lower bound in offline RL with preference feedback. Interestingly, we observe that the lower and upper bounds on the simple regret match order-wise in the exponent, demonstrating order-wise optimality of {sc RL-LOW}. In view of privacy considerations in practical applications, we also extend {sc RL-LOW} to the setting of $(varepsilon,delta)$-differential privacy and show, somewhat surprisingly, that the hardness parameter $H$ is unchanged in the asymptotic regime as $n$ tends to infinity; this underscores the inherent efficiency of {sc RL-LOW} in terms of preserving the privacy of the observed rewards. Given our focus on establishing instance-dependent bounds, our work stands in stark contrast to previous works that focus on establishing worst-case regrets for offline RL with preference feedback.
Read more6/19/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024

0
Online Bandit Learning with Offline Preference Data
Akhil Agnihotri, Rahul Jain, Deepak Ramachandran, Zheng Wen
Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose $texttt{warmPref-PS}$, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.
Read more6/17/2024
🐍
0
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
Read more6/5/2024