Open-Set Multivariate Time-Series Anomaly Detection

0

Sign in to get full access
Overview
- This paper proposes a new method for classifying time series data.
- The method involves a feature extractor and a multi-head network.
- The key ideas are using self-supervised learning to extract features and using a multi-task approach to make multiple predictions.
Plain English Explanation
The paper describes a new way to analyze time series data, which is data that changes over time, like stock prices or sensor readings. The main idea is to use machine learning to automatically find important patterns in the data, and then use those patterns to make predictions about the data.
The first step is to use self-supervised learning to extract features from the time series data. This means the model learns to identify important characteristics of the data without being told what they are ahead of time. The second step is to use a multi-head network, which means the model makes multiple predictions at the same time, each one focusing on a different aspect of the data. This allows the model to capture the complexity of the time series data more effectively.
The key advantage of this approach is that it can work well even when you don't have a lot of labeled data, which is often the case with time series data. The self-supervised feature extraction and multi-task learning allow the model to learn useful representations and make accurate predictions without needing a lot of human-labeled examples.
Technical Explanation
The paper proposes a new time series classification method that uses a feature extractor and a multi-head network.
The feature extractor uses self-supervised learning to automatically identify important characteristics of the input time series data. This involves training the model to predict future time steps in the data, which forces it to learn useful representations without any human labeling.
The multi-head network takes the features extracted by the feature extractor and uses them to make multiple predictions simultaneously. Each "head" of the network focuses on a different prediction task, such as classifying the time series into categories or forecasting future values. This multi-task approach allows the model to capture more nuanced relationships in the data compared to making a single prediction.
By combining the self-supervised feature extractor and the multi-head network, the proposed method can effectively classify time series data even when labeled examples are scarce. The feature extractor learns powerful representations, and the multi-head network leverages those representations to make accurate predictions on multiple relevant tasks.
Critical Analysis
The paper provides a compelling approach to time series classification, addressing the common challenge of limited labeled data. The use of self-supervised learning to extract features is a promising technique, as it can uncover useful patterns without relying on human annotations.
However, the authors do not extensively discuss potential limitations or areas for further research. For example, the performance of the method on different types of time series data, the computational cost of the feature extractor, or the interpretation of the multi-head predictions could be explored further.
Additionally, while the multi-task approach is a strength, the paper could benefit from a deeper analysis of how the different prediction heads interact and influence each other. Understanding these relationships could lead to insights about the underlying structure of the time series data.
Overall, the paper presents a well-designed and potentially impactful method for time series classification, but additional investigation into the technique's robustness, scalability, and interpretability could further strengthen the research.
Conclusion
This paper introduces a novel approach to time series classification that leverages self-supervised feature extraction and multi-task learning. By automatically learning useful representations of the data and making multiple related predictions, the proposed method can effectively classify time series data even when labeled examples are scarce.
The key contributions of this work are the integration of self-supervised learning and multi-head networks, which enables the model to capture the complexity of time series data more effectively than traditional single-task approaches. This has important implications for applications where labeled data is limited, such as anomaly detection, forecasting, and decision support systems.
While the paper demonstrates the effectiveness of the proposed method, further research is needed to fully characterize its strengths, limitations, and potential areas of improvement. Nonetheless, this work represents an important step forward in the field of time series analysis and classification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open-Set Multivariate Time-Series Anomaly Detection
Thomas Lai, Thi Kieu Khanh Ho, Narges Armanfard
Numerous methods for time-series anomaly detection (TSAD) have emerged in recent years, most of which are unsupervised and assume that only normal samples are available during the training phase, due to the challenge of obtaining abnormal data in real-world scenarios. Still, limited samples of abnormal data are often available, albeit they are far from representative of all possible anomalies. Supervised methods can be utilized to classify normal and seen anomalies, but they tend to overfit to the seen anomalies present during training, hence, they fail to generalize to unseen anomalies. We propose the first algorithm to address the open-set TSAD problem, called Multivariate Open-Set Time-Series Anomaly Detector (MOSAD), that leverages only a few shots of labeled anomalies during the training phase in order to achieve superior anomaly detection performance compared to both supervised and unsupervised TSAD algorithms. MOSAD is a novel multi-head TSAD framework with a shared representation space and specialized heads, including the Generative head, the Discriminative head, and the Anomaly-Aware Contrastive head. The latter produces a superior representation space for anomaly detection compared to conventional supervised contrastive learning. Extensive experiments on three real-world datasets establish MOSAD as a new state-of-the-art in the TSAD field.
Read more8/9/2024

0
End-To-End Self-tuning Self-supervised Time Series Anomaly Detection
Boje Deforce, Meng-Chieh Lee, Bart Baesens, Estefan'ia Serral Asensio, Jaemin Yoo, Leman Akoglu
Time series anomaly detection (TSAD) finds many applications such as monitoring environmental sensors, industry KPIs, patient biomarkers, etc. A two-fold challenge for TSAD is a versatile and unsupervised model that can detect various different types of time series anomalies (spikes, discontinuities, trend shifts, etc.) without any labeled data. Modern neural networks have outstanding ability in modeling complex time series. Self-supervised models in particular tackle unsupervised TSAD by transforming the input via various augmentations to create pseudo anomalies for training. However, their performance is sensitive to the choice of augmentation, which is hard to choose in practice, while there exists no effort in the literature on data augmentation tuning for TSAD without labels. Our work aims to fill this gap. We introduce TSAP for TSA on autoPilot, which can (self-)tune augmentation hyperparameters end-to-end. It stands on two key components: a differentiable augmentation architecture and an unsupervised validation loss to effectively assess the alignment between augmentation type and anomaly type. Case studies show TSAP's ability to effectively select the (discrete) augmentation type and associated (continuous) hyperparameters. In turn, it outperforms established baselines, including SOTA self-supervised models, on diverse TSAD tasks exhibiting different anomaly types.
Read more4/4/2024
❗
0
Graph Anomaly Detection in Time Series: A Survey
Thi Kieu Khanh Ho, Ali Karami, Narges Armanfard
With the recent advances in technology, a wide range of systems continue to collect a large amount of data over time and thus generate time series. Time-Series Anomaly Detection (TSAD) is an important task in various time-series applications such as e-commerce, cybersecurity, vehicle maintenance, and healthcare monitoring. However, this task is very challenging as it requires considering both the intra-variable dependency and the inter-variable dependency, where a variable can be defined as an observation in time-series data. Recent graph-based approaches have made impressive progress in tackling the challenges of this field. In this survey, we conduct a comprehensive and up-to-date review of TSAD using graphs, referred to as G-TSAD. First, we explore the significant potential of graph representation learning for time-series data. Then, we review state-of-the-art graph anomaly detection techniques in the context of time series and discuss their strengths and drawbacks. Finally, we discuss the technical challenges and potential future directions for possible improvements in this research field.
Read more4/30/2024
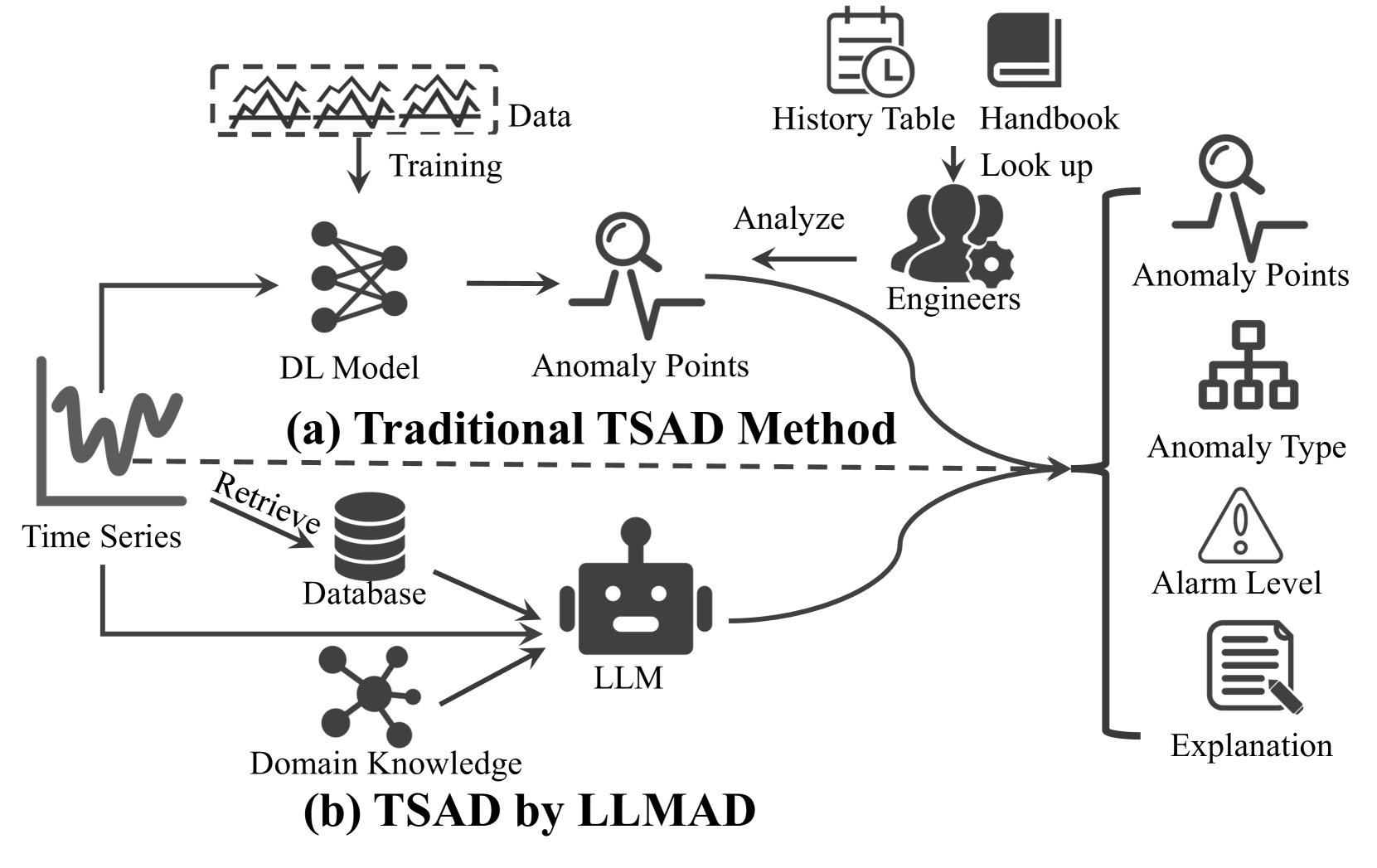
0
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
Read more5/27/2024