OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding

0

Sign in to get full access
Overview
- The paper proposes a new benchmark called OpenScan for evaluating generalized open-vocabulary 3D scene understanding.
- OpenScan aims to enable the development of models that can understand and describe arbitrary 3D scenes using natural language.
- The benchmark includes a diverse dataset of 3D scenes and a set of language-based tasks for evaluating model performance.
Plain English Explanation
The researchers created a new tool called OpenScan to help develop AI models that can understand and describe 3D scenes using regular language. This is different from current 3D understanding models, which are often limited to a fixed set of predefined object categories.
With OpenScan, the goal is to create AI systems that can interact with 3D environments the way humans do - by using open-ended language to describe what they see, ask questions, and give instructions. The OpenScan benchmark includes a diverse dataset of 3D scenes and a set of language-based tasks that can be used to evaluate how well AI models perform at this type of open-vocabulary 3D understanding.
By developing models that can understand 3D scenes in this more natural, human-like way, the researchers hope to unlock new applications in areas like 3D scene reconstruction, object detection, and human-robot interaction.
Technical Explanation
The key innovation of this work is the introduction of the OpenScan benchmark for evaluating open-vocabulary 3D scene understanding. The benchmark includes a diverse dataset of 3D scenes captured from a variety of real-world environments.
The dataset covers a wide range of object categories and scene configurations, going beyond the limited scope of most existing 3D understanding datasets. Importantly, the scenes are annotated with open-ended natural language descriptions, enabling the evaluation of models on language-based tasks.
The paper defines several benchmark tasks, including scene description, question answering, and instruction following. These tasks are designed to assess a model's ability to understand and interact with 3D scenes using natural language in a flexible, generalizable way.
The authors also provide baseline model results on the OpenScan benchmark, demonstrating the challenges of this new task. They find that current state-of-the-art 3D and language models struggle to perform well on the open-vocabulary 3D understanding tasks, highlighting the need for further research in this area.
Critical Analysis
The OpenScan benchmark is a valuable contribution that could drive progress in generalized 3D scene understanding. By focusing on open-vocabulary interactions, it pushes beyond the limitations of current 3D perception systems, which are often constrained to predefined object categories.
However, the paper does not address some important considerations. For example, it is unclear how the benchmark dataset was curated and how representative it is of real-world 3D environments. There are also open questions about the scalability and robustness of the language-based evaluation tasks.
Additionally, while the baseline model results demonstrate the difficulty of the OpenScan tasks, the paper does not provide a deep analysis of the underlying challenges or propose concrete directions for future research. More insights into the shortcomings of existing approaches would be valuable for guiding the development of more capable open-vocabulary 3D understanding models.
Conclusion
The OpenScan benchmark represents an important step towards developing AI systems that can understand and interact with 3D environments in a more natural, human-like way. By focusing on open-vocabulary tasks, it challenges the field to move beyond the constraints of predefined object categories and create models that can truly comprehend the rich complexity of the 3D world.
While the benchmark has some limitations, it opens up new research directions and could catalyze the development of more flexible, generalizable 3D perception and language understanding capabilities. Ultimately, the ability to bridge the gap between textual and visual representations of 3D scenes has the potential to unlock a wide range of applications in areas like robotics, augmented reality, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Youjun Zhao, Jiaying Lin, Shuquan Ye, Qianshi Pang, Rynson W. H. Lau
Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient to provide a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named OpenScan, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, material, and more. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark, and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed by simply scaling up object classes during training. We highlight the limitations of existing methodologies and explore a promising direction to overcome the identified shortcomings. Data and code are available at https://github.com/YoujunZhao/OpenScan
Read more8/21/2024
0
Open-Vocabulary SAM3D: Understand Any 3D Scene
Hanchen Tai, Qingdong He, Jiangning Zhang, Yijie Qian, Zhenyu Zhang, Xiaobin Hu, Xiangtai Li, Yabiao Wang, Yong Liu
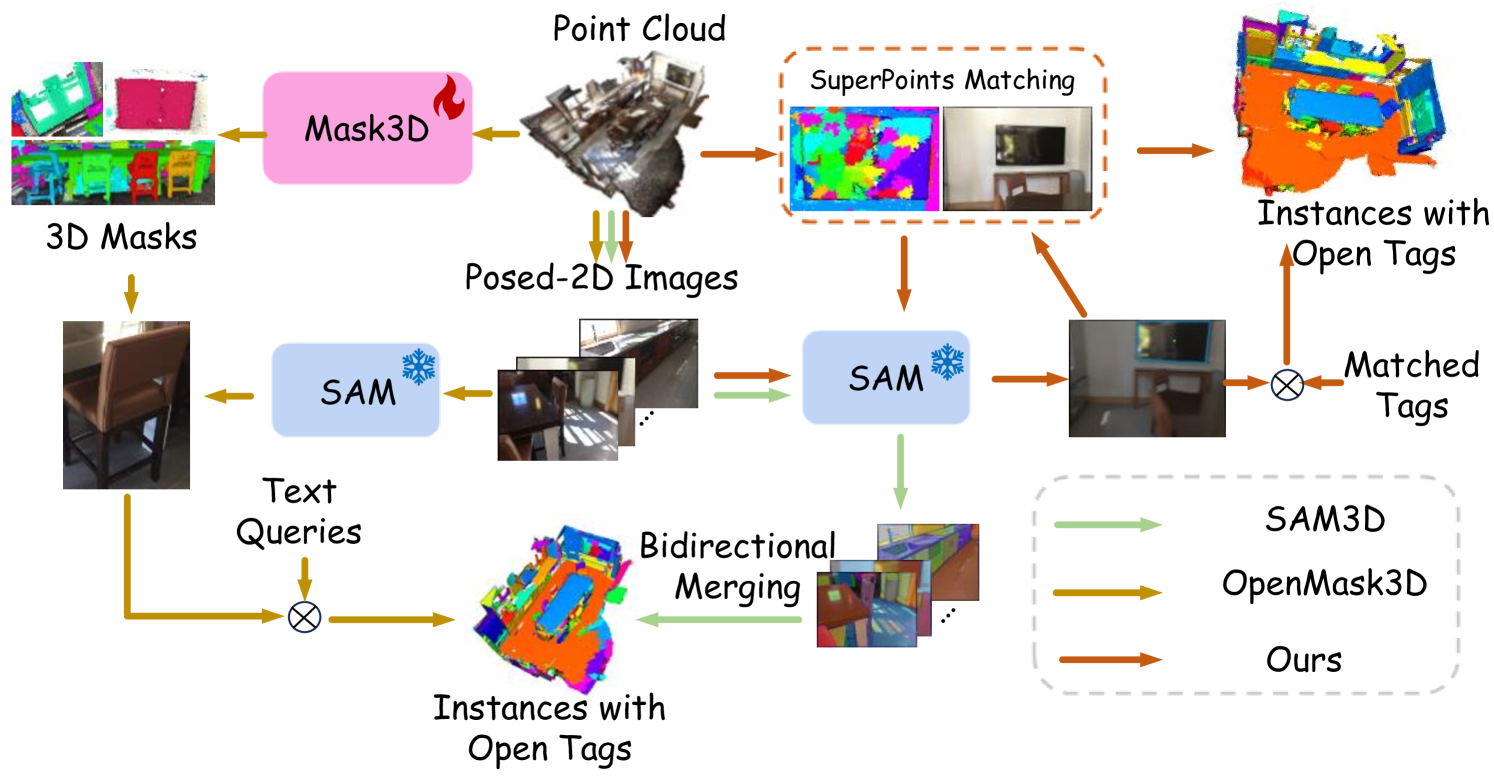
Open-vocabulary 3D scene understanding presents a significant challenge in the field. Recent works have sought to transfer knowledge embedded in vision-language models from 2D to 3D domains. However, these approaches often require prior knowledge from specific 3D scene datasets, limiting their applicability in open-world scenarios. The Segment Anything Model (SAM) has demonstrated remarkable zero-shot segmentation capabilities, prompting us to investigate its potential for comprehending 3D scenes without training. In this paper, we introduce OV-SAM3D, a training-free method that contains a universal framework for understanding open-vocabulary 3D scenes. This framework is designed to perform understanding tasks for any 3D scene without requiring prior knowledge of the scene. Specifically, our method is composed of two key sub-modules: First, we initiate the process by generating superpoints as the initial 3D prompts and refine these prompts using segment masks derived from SAM. Moreover, we then integrate a specially designed overlapping score table with open tags from the Recognize Anything Model (RAM) to produce final 3D instances with open-world labels. Empirical evaluations on the ScanNet200 and nuScenes datasets demonstrate that our approach surpasses existing open-vocabulary methods in unknown open-world environments.
Read more9/6/2024

0
Unlocking Textual and Visual Wisdom: Open-Vocabulary 3D Object Detection Enhanced by Comprehensive Guidance from Text and Image
Pengkun Jiao, Na Zhao, Jingjing Chen, Yu-Gang Jiang
Open-vocabulary 3D object detection (OV-3DDet) aims to localize and recognize both seen and previously unseen object categories within any new 3D scene. While language and vision foundation models have achieved success in handling various open-vocabulary tasks with abundant training data, OV-3DDet faces a significant challenge due to the limited availability of training data. Although some pioneering efforts have integrated vision-language models (VLM) knowledge into OV-3DDet learning, the full potential of these foundational models has yet to be fully exploited. In this paper, we unlock the textual and visual wisdom to tackle the open-vocabulary 3D detection task by leveraging the language and vision foundation models. We leverage a vision foundation model to provide image-wise guidance for discovering novel classes in 3D scenes. Specifically, we utilize a object detection vision foundation model to enable the zero-shot discovery of objects in images, which serves as the initial seeds and filtering guidance to identify novel 3D objects. Additionally, to align the 3D space with the powerful vision-language space, we introduce a hierarchical alignment approach, where the 3D feature space is aligned with the vision-language feature space using a pre-trained VLM at the instance, category, and scene levels. Through extensive experimentation, we demonstrate significant improvements in accuracy and generalization, highlighting the potential of foundation models in advancing open-vocabulary 3D object detection in real-world scenarios.
Read more7/18/2024

0
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Qingdong He, Jinlong Peng, Zhengkai Jiang, Kai Wu, Xiaozhong Ji, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Mingang Chen, Yunsheng Wu
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Read more4/23/2024