OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation

0

Sign in to get full access
Overview
- This paper introduces OpenVid-1M, a large-scale, high-quality dataset for text-to-video generation.
- The dataset contains over 1 million video-text pairs, with diverse video content and corresponding captions.
- The dataset aims to enable research on text-to-video generation and other video-language tasks.
Plain English Explanation
The researchers have created a new dataset called OpenVid-1M that contains over 1 million short video clips along with their corresponding captions or descriptions. This dataset is designed to help researchers develop and test AI systems that can generate videos based on text prompts.
The key features of the OpenVid-1M dataset are:
-
Large Scale: With over 1 million video-text pairs, it is one of the largest datasets of its kind, providing a rich source of data for training and evaluating text-to-video generation models.
-
High Quality: The video clips are of high visual quality, captured at 1080p resolution, which is important for creating realistic and compelling generated videos.
-
Diverse Content: The videos cover a wide range of topics and scenes, from everyday activities to creative and imaginative scenarios, allowing models to learn to generate a broad variety of video content.
By making this dataset publicly available, the researchers hope to spur further advancements in the field of text-to-video generation, where AI systems can automatically create video content based on textual descriptions or prompts. This could have applications in areas like video production, educational content creation, and interactive storytelling.
Technical Explanation
The OpenVid-1M dataset was created by the researchers to address the lack of large-scale, high-quality datasets for text-to-video generation. Previous datasets tended to be either small in scale or of lower visual quality, limiting the ability of AI models to learn to generate realistic and diverse video content.
To build OpenVid-1M, the researchers curated a massive collection of video clips from the internet, along with their corresponding captions or descriptions. They carefully filtered and processed the data to ensure high visual quality, with all videos captured at 1080p resolution. The final dataset contains over 1 million video-text pairs, making it one of the largest of its kind.
The researchers have made the OpenVid-1M dataset publicly available, allowing researchers to use it for training and evaluating text-to-video generation models. They envision the dataset being a valuable resource for advancing the state-of-the-art in this field, as well as enabling the development of new applications that leverage AI-generated video content.
Critical Analysis
The OpenVid-1M dataset represents a significant contribution to the field of text-to-video generation. By providing a large-scale, high-quality dataset, the researchers have addressed a key limitation in the existing research landscape. The diverse content and high visual quality of the videos should enable the development of more sophisticated and capable text-to-video generation models.
However, the paper does not provide much detail on the specific process used to curate and filter the dataset. It would be helpful to know more about the sources of the video clips, the criteria used for selection, and the steps taken to ensure the quality and diversity of the content.
Additionally, the paper does not discuss potential biases or limitations in the dataset. It is important to consider how the dataset might reflect certain demographic or cultural biases, which could impact the performance and fairness of the AI models trained on it.
As the field of text-to-video generation continues to evolve, it will be crucial to develop a range of diverse and representative datasets to train and evaluate these models. The OpenVid-1M dataset is a valuable step in this direction, but further research and innovation will be needed to fully realize the potential of this technology.
Conclusion
The OpenVid-1M dataset introduced in this paper represents a significant advancement in the field of text-to-video generation. By providing a large-scale, high-quality dataset of over 1 million video-text pairs, the researchers have created a valuable resource for researchers and developers working on AI-powered video creation.
The diverse content and high visual quality of the videos in the dataset should enable the development of more sophisticated and capable text-to-video generation models, with potential applications in areas such as video production, educational content creation, and interactive storytelling.
While the paper does not delve into all the details of the dataset curation process, the availability of OpenVid-1M is a positive step towards addressing the lack of large-scale, high-quality datasets in this field. As the research in text-to-video generation continues to evolve, this dataset and others like it will be crucial in driving further advancements and unlocking new possibilities for AI-generated video content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, Ying Tai
Text-to-video (T2V) generation has recently garnered significant attention thanks to the large multi-modality model Sora. However, T2V generation still faces two important challenges: 1) Lacking a precise open sourced high-quality dataset. The previous popular video datasets, e.g. WebVid-10M and Panda-70M, are either with low quality or too large for most research institutions. Therefore, it is challenging but crucial to collect a precise high-quality text-video pairs for T2V generation. 2) Ignoring to fully utilize textual information. Recent T2V methods have focused on vision transformers, using a simple cross attention module for video generation, which falls short of thoroughly extracting semantic information from text prompt. To address these issues, we introduce OpenVid-1M, a precise high-quality dataset with expressive captions. This open-scenario dataset contains over 1 million text-video pairs, facilitating research on T2V generation. Furthermore, we curate 433K 1080p videos from OpenVid-1M to create OpenVidHD-0.4M, advancing high-definition video generation. Additionally, we propose a novel Multi-modal Video Diffusion Transformer (MVDiT) capable of mining both structure information from visual tokens and semantic information from text tokens. Extensive experiments and ablation studies verify the superiority of OpenVid-1M over previous datasets and the effectiveness of our MVDiT.
Read more8/6/2024

0
VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
Wenhao Wang, Yi Yang
The arrival of Sora marks a new era for text-to-video diffusion models, bringing significant advancements in video generation and potential applications. However, Sora, along with other text-to-video diffusion models, is highly reliant on prompts, and there is no publicly available dataset that features a study of text-to-video prompts. In this paper, we introduce VidProM, the first large-scale dataset comprising 1.67 Million unique text-to-Video Prompts from real users. Additionally, this dataset includes 6.69 million videos generated by four state-of-the-art diffusion models, alongside some related data. We initially discuss the curation of this large-scale dataset, a process that is both time-consuming and costly. Subsequently, we underscore the need for a new prompt dataset specifically designed for text-to-video generation by illustrating how VidProM differs from DiffusionDB, a large-scale prompt-gallery dataset for image generation. Our extensive and diverse dataset also opens up many exciting new research areas. For instance, we suggest exploring text-to-video prompt engineering, efficient video generation, and video copy detection for diffusion models to develop better, more efficient, and safer models. The project (including the collected dataset VidProM and related code) is publicly available at https://vidprom.github.io under the CC-BY-NC 4.0 License.
Read more5/15/2024
0
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
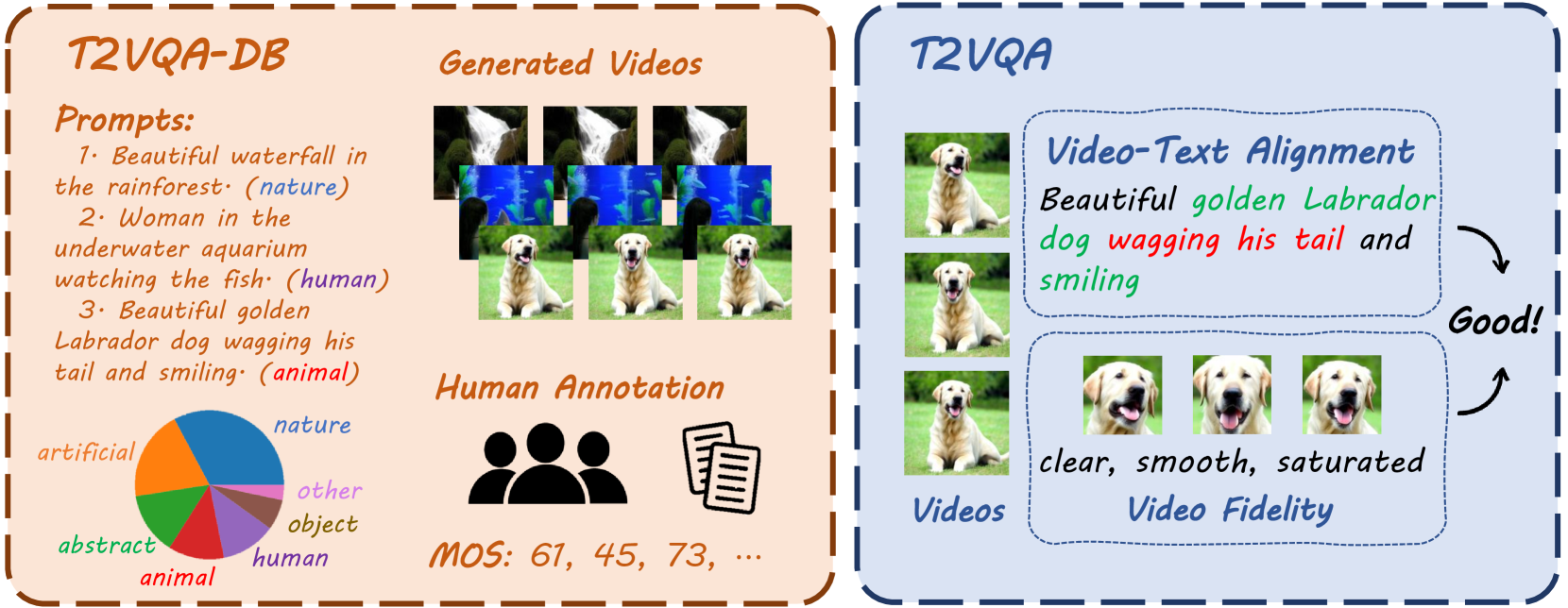
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
Read more8/9/2024
🛸
0
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
Xuan Ju, Yiming Gao, Zhaoyang Zhang, Ziyang Yuan, Xintao Wang, Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan
Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips. GPT-4V is employed to annotate structured captions, providing detailed descriptions from four different perspectives along with a summarized dense caption. To better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. MiraBench includes 150 evaluation prompts and 17 metrics covering temporal consistency, motion strength, 3D consistency, visual quality, text-video alignment, and distribution similarity. To demonstrate the utility and effectiveness of MiraData, we conduct experiments using our DiT-based video generation model, MiraDiT. The experimental results on MiraBench demonstrate the superiority of MiraData, especially in motion strength.
Read more7/10/2024