Optimal Parallelization of Boosting

0
🖼️
Sign in to get full access
Overview
- Parallelization of boosting algorithms can significantly speed up the training process
- This paper proposes an optimal parallelization strategy for boosting that achieves the best possible speedup
- The authors analyze the theoretical limits of parallelization for boosting and develop a parallel algorithm that matches these limits
Plain English Explanation
Boosting is a powerful machine learning technique that combines multiple "weak" models (like simple decision trees) into a single "strong" model. However, training boosting models can be computationally intensive, especially for large datasets.
The Parallel Weak-to-Strong Learning section explains that parallelizing the boosting training process can dramatically speed things up. The key insight is that the different "weak" models can be trained concurrently on separate processors, and then combined into the final strong model.
The paper examines the theoretical limits of how much parallelization can speed up boosting (Weak-to-Strong Learning). It then presents a parallel boosting algorithm that is able to achieve this optimal speedup (Technical Explanation).
The Critical Analysis discusses some potential limitations, such as the algorithm's reliance on having a large number of available processors. Overall, this research provides an important theoretical foundation for efficiently parallelizing boosting algorithms in practice.
Technical Explanation
The paper first analyzes the fundamental limits of parallelizing boosting algorithms. It shows that the minimum number of sequential steps required is proportional to the number of weak models (i.e., the number of "boosting rounds"). This establishes a theoretical upper bound on the achievable speedup from parallelization.
The authors then present a parallel boosting algorithm that is able to match this theoretical limit. The key idea is to have each processor train a different weak model in parallel, and then combine these models into the final strong model. Crucially, the algorithm is able to do this without requiring any communication between the processors during the training process.
The paper provides a detailed analysis of the algorithm's runtime and convergence properties, demonstrating that it achieves the optimal parallel speedup. Experiments on real-world datasets confirm these theoretical results, showing significant acceleration compared to standard sequential boosting.
Critical Analysis
One potential limitation of the proposed approach is its reliance on having a large number of available processors. The optimal speedup is only achievable with a number of processors equal to the number of boosting rounds. In practice, this may not always be feasible, especially for very large models.
The paper also does not address the issue of load balancing - ensuring that each processor has an equal amount of work to do. Uneven workloads could diminish the overall speedup. Extensions to handle this and other practical concerns would be valuable.
Additionally, the analysis focuses solely on the training phase of boosting. The inference (or prediction) phase is also an important consideration, and parallelization strategies for this stage could provide further efficiency gains.
Conclusion
This paper presents a theoretically-grounded approach for parallelizing boosting algorithms to achieve optimal speedups. By carefully analyzing the limits of parallelization and developing a matching parallel algorithm, the authors have made an important contribution to the efficient implementation of boosting models.
While some practical limitations remain, this work lays the foundation for further research into scaling up boosting methods to handle ever-larger datasets and model sizes. As machine learning continues to have a growing impact across many domains, advancements like this will be crucial for enabling the widespread deployment of these powerful techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Optimal Parallelization of Boosting
Arthur da Cunha, Mikael M{o}ller H{o}gsgaard, Kasper Green Larsen
Recent works on the parallel complexity of Boosting have established strong lower bounds on the tradeoff between the number of training rounds $p$ and the total parallel work per round $t$. These works have also presented highly non-trivial parallel algorithms that shed light on different regions of this tradeoff. Despite these advancements, a significant gap persists between the theoretical lower bounds and the performance of these algorithms across much of the tradeoff space. In this work, we essentially close this gap by providing both improved lower bounds on the parallel complexity of weak-to-strong learners, and a parallel Boosting algorithm whose performance matches these bounds across the entire $p$ vs.~$t$ compromise spectrum, up to logarithmic factors. Ultimately, this work settles the true parallel complexity of Boosting algorithms that are nearly sample-optimal.
Read more8/30/2024
0
The Many Faces of Optimal Weak-to-Strong Learning
Mikael M{o}ller H{o}gsgaard, Kasper Green Larsen, Markus Engelund Mathiasen
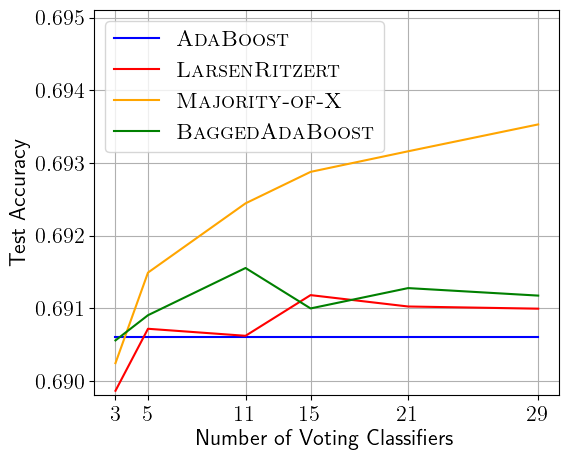
Boosting is an extremely successful idea, allowing one to combine multiple low accuracy classifiers into a much more accurate voting classifier. In this work, we present a new and surprisingly simple Boosting algorithm that obtains a provably optimal sample complexity. Sample optimal Boosting algorithms have only recently been developed, and our new algorithm has the fastest runtime among all such algorithms and is the simplest to describe: Partition your training data into 5 disjoint pieces of equal size, run AdaBoost on each, and combine the resulting classifiers via a majority vote. In addition to this theoretical contribution, we also perform the first empirical comparison of the proposed sample optimal Boosting algorithms. Our pilot empirical study suggests that our new algorithm might outperform previous algorithms on large data sets.
Read more9/2/2024
📈
0
Efficient Parallelization Layouts for Large-Scale Distributed Model Training
Johannes Hagemann, Samuel Weinbach, Konstantin Dobler, Maximilian Schall, Gerard de Melo
Efficiently training large language models requires parallelizing across hundreds of hardware accelerators and invoking various compute and memory optimizations. When combined, many of these strategies have complex interactions regarding the final training efficiency. Prior work tackling this problem did not have access to the latest set of optimizations, such as FlashAttention or sequence parallelism. In this work, we conduct a comprehensive ablation study of possible training configurations for large language models. We distill this large study into several key recommendations for the most efficient training. For instance, we find that using a micro-batch size of 1 usually enables the most efficient training layouts. Larger micro-batch sizes necessitate activation checkpointing or higher degrees of model parallelism and also lead to larger pipeline bubbles. Our most efficient configurations enable us to achieve state-of-the-art training efficiency results over a range of model sizes, most notably a Model FLOPs utilization of 70.5% when training a Llama 13B model.
Read more9/25/2024
🎲
0
The Sample Complexity of Smooth Boosting and the Tightness of the Hardcore Theorem
Guy Blanc, Alexandre Hayderi, Caleb Koch, Li-Yang Tan
Smooth boosters generate distributions that do not place too much weight on any given example. Originally introduced for their noise-tolerant properties, such boosters have also found applications in differential privacy, reproducibility, and quantum learning theory. We study and settle the sample complexity of smooth boosting: we exhibit a class that can be weak learned to $gamma$-advantage over smooth distributions with $m$ samples, for which strong learning over the uniform distribution requires $tilde{Omega}(1/gamma^2)cdot m$ samples. This matches the overhead of existing smooth boosters and provides the first separation from the setting of distribution-independent boosting, for which the corresponding overhead is $O(1/gamma)$. Our work also sheds new light on Impagliazzo's hardcore theorem from complexity theory, all known proofs of which can be cast in the framework of smooth boosting. For a function $f$ that is mildly hard against size-$s$ circuits, the hardcore theorem provides a set of inputs on which $f$ is extremely hard against size-$s'$ circuits. A downside of this important result is the loss in circuit size, i.e. that $s' ll s$. Answering a question of Trevisan, we show that this size loss is necessary and in fact, the parameters achieved by known proofs are the best possible.
Read more9/19/2024