Optimal transport for automatic alignment of untargeted metabolomic data

0
📊
Sign in to get full access
Overview
- Untargeted metabolomic profiling using liquid chromatography-mass spectrometry (LC-MS) can measure a wide range of metabolites in biospecimens, but the low throughput of LC-MS makes it challenging to combine and compare multiple datasets for biomarker discovery.
- Current data pooling methods are vulnerable to data variations and hyperparameter dependence, so the authors introduce GromovMatcher, a flexible algorithm that automatically combines LC-MS datasets using optimal transport.
- GromovMatcher delivers superior alignment accuracy and robustness compared to existing approaches, and it can scale to thousands of features with minimal hyperparameter tuning.
Plain English Explanation
Untargeted metabolomic profiling using a technique called liquid chromatography-mass spectrometry (LC-MS) allows researchers to measure a vast number of different molecules, called metabolites, within biological samples. This information can be very useful for developing new drugs, diagnosing diseases, and predicting health risks. However, the LC-MS process is relatively slow, making it difficult to combine and compare data from multiple studies.
Current methods for merging these datasets have practical limitations because they are vulnerable to variations in the data and require a lot of fine-tuning of their parameters. To address this, the researchers developed a new algorithm called GromovMatcher that automatically combines LC-MS datasets using a technique called optimal transport. By focusing on the patterns of metabolite intensities, GromovMatcher can align multiple datasets with high accuracy and consistency, even for very large datasets with thousands of features. This makes it easier for researchers to search for metabolic patterns that may be associated with various diseases or lifestyle factors, such as alcohol consumption, across different patient studies.
Technical Explanation
The authors introduce GromovMatcher, a flexible algorithm that automatically combines LC-MS datasets using optimal transport. GromovMatcher capitalizes on the correlation structures of feature intensities to deliver superior alignment accuracy and robustness compared to existing approaches.
The algorithm works by leveraging optimal transport to find the most efficient way to "move" the metabolite features from one dataset to align with the corresponding features in another dataset. This approach is more resilient to data variations and requires minimal hyperparameter tuning, allowing it to scale to datasets with thousands of features.
To validate the performance of GromovMatcher and other alignment methods, the authors developed a novel dataset splitting procedure. This generates pairs of validation datasets from manually curated metabolomics datasets, which can be used to test the accuracy of the alignments produced by different algorithms.
The authors applied GromovMatcher to experimental patient studies of liver and pancreatic cancer, and were able to discover shared metabolic features related to patient alcohol intake. This demonstrates how GromovMatcher can facilitate the identification of biomarkers associated with lifestyle risk factors linked to multiple cancer types.
Critical Analysis
The authors acknowledge that manually curated datasets for validating metabolomics alignment algorithms are limited in the field of untargeted metabolomics. Their dataset splitting procedure is a valuable contribution to address this limitation, but the resulting validation datasets may still not fully capture the complexities of real-world metabolomics data.
Additionally, while GromovMatcher demonstrates superior performance compared to existing approaches, the authors do not provide a comprehensive analysis of its computational complexity or runtime. As the number of features in metabolomics datasets continues to grow, the scalability of the algorithm may become an important consideration.
Further research could explore the application of GromovMatcher to align multimodal data, as well as the potential integration of generative models or language models to enhance the annotation and interpretation of metabolic features identified through GromovMatcher alignments.
Conclusion
The GromovMatcher algorithm developed by the authors addresses a critical challenge in the field of untargeted metabolomics by providing a flexible and robust method for automatically combining and aligning LC-MS datasets. By leveraging optimal transport and feature intensity correlations, GromovMatcher can scale to large-scale metabolomics studies and facilitate the discovery of biomarkers associated with various diseases and lifestyle factors. This work builds upon advances in audio-text retrieval and generalized Schrödinger bridge matching, demonstrating the potential for cross-pollination of techniques across different domains of machine learning and data science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Optimal transport for automatic alignment of untargeted metabolomic data
Marie Breeur, George Stepaniants, Pekka Keski-Rahkonen, Philippe Rigollet, Vivian Viallon
Untargeted metabolomic profiling through liquid chromatography-mass spectrometry (LC-MS) measures a vast array of metabolites within biospecimens, advancing drug development, disease diagnosis, and risk prediction. However, the low throughput of LC-MS poses a major challenge for biomarker discovery, annotation, and experimental comparison, necessitating the merging of multiple datasets. Current data pooling methods encounter practical limitations due to their vulnerability to data variations and hyperparameter dependence. Here we introduce GromovMatcher, a flexible and user-friendly algorithm that automatically combines LC-MS datasets using optimal transport. By capitalizing on feature intensity correlation structures, GromovMatcher delivers superior alignment accuracy and robustness compared to existing approaches. This algorithm scales to thousands of features requiring minimal hyperparameter tuning. Manually curated datasets for validating alignment algorithms are limited in the field of untargeted metabolomics, and hence we develop a dataset split procedure to generate pairs of validation datasets to test the alignments produced by GromovMatcher and other methods. Applying our method to experimental patient studies of liver and pancreatic cancer, we discover shared metabolic features related to patient alcohol intake, demonstrating how GromovMatcher facilitates the search for biomarkers associated with lifestyle risk factors linked to several cancer types.
Read more5/27/2024
0
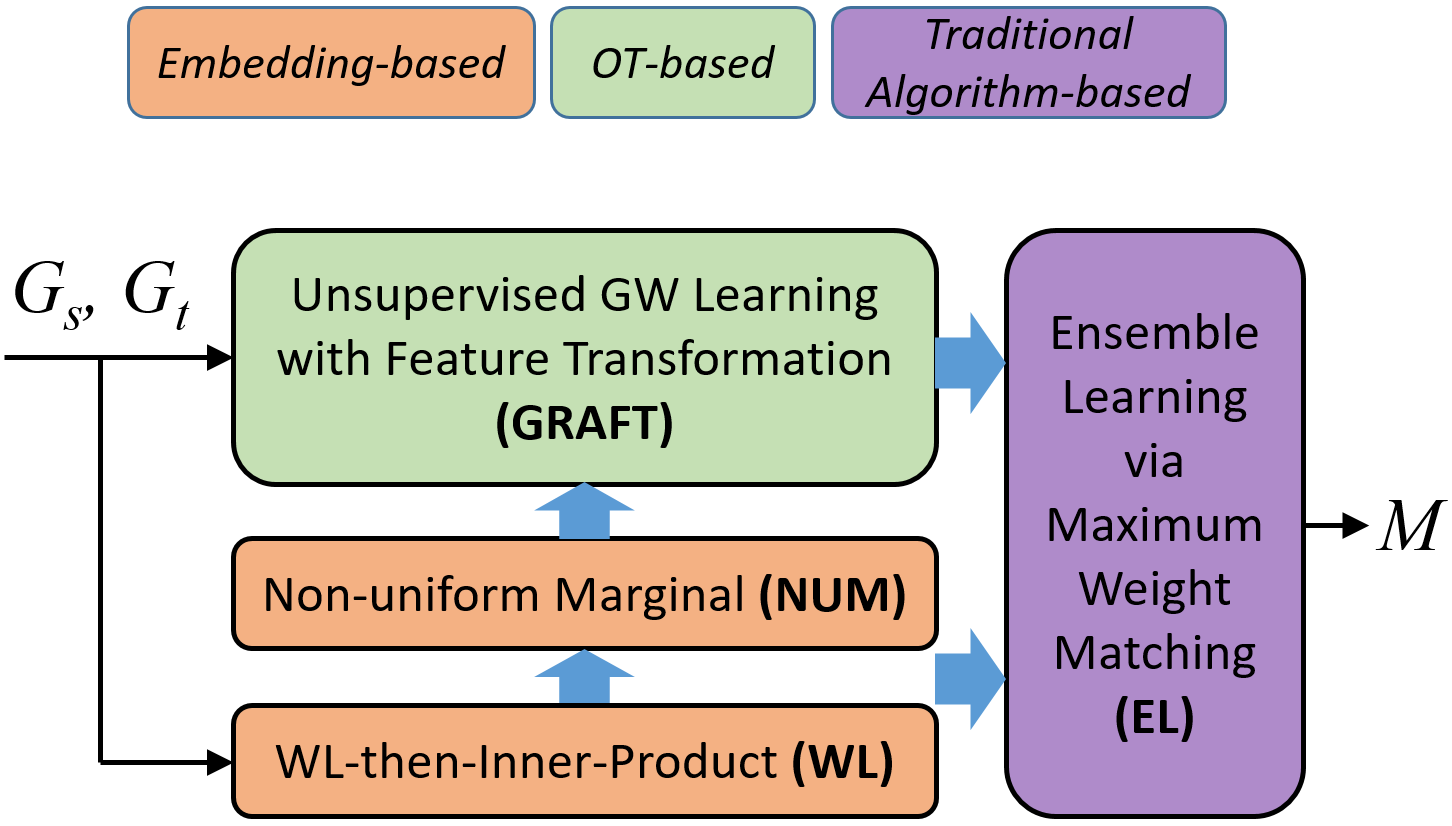
Combining Optimal Transport and Embedding-Based Approaches for More Expressiveness in Unsupervised Graph Alignment
Songyang Chen, Yu Liu, Lei Zou, Zexuan Wang, Youfang Lin, Yuxing Chen, Anqun Pan
Unsupervised graph alignment finds the one-to-one node correspondence between a pair of attributed graphs by only exploiting graph structure and node features. One category of existing works first computes the node representation and then matches nodes with close embeddings, which is intuitive but lacks a clear objective tailored for graph alignment in the unsupervised setting. The other category reduces the problem to optimal transport (OT) via Gromov-Wasserstein (GW) learning with a well-defined objective but leaves a large room for exploring the design of transport cost. We propose a principled approach to combine their advantages motivated by theoretical analysis of model expressiveness. By noticing the limitation of discriminative power in separating matched and unmatched node pairs, we improve the cost design of GW learning with feature transformation, which enables feature interaction across dimensions. Besides, we propose a simple yet effective embedding-based heuristic inspired by the Weisfeiler-Lehman test and add its prior knowledge to OT for more expressiveness when handling non-Euclidean data. Moreover, we are the first to guarantee the one-to-one matching constraint by reducing the problem to maximum weight matching. The algorithm design effectively combines our OT and embedding-based predictions via stacking, an ensemble learning strategy. We propose a model framework named texttt{CombAlign} integrating all the above modules to refine node alignment progressively. Through extensive experiments, we demonstrate significant improvements in alignment accuracy compared to state-of-the-art approaches and validate the effectiveness of the proposed modules.
Read more6/21/2024

0
Optimal Transport for Latent Integration with An Application to Heterogeneous Neuronal Activity Data
Yubai Yuan, Babak Shahbaba, Norbert Fortin, Keiland Cooper, Qing Nie, Annie Qu
Detecting dynamic patterns of task-specific responses shared across heterogeneous datasets is an essential and challenging problem in many scientific applications in medical science and neuroscience. In our motivating example of rodent electrophysiological data, identifying the dynamical patterns in neuronal activity associated with ongoing cognitive demands and behavior is key to uncovering the neural mechanisms of memory. One of the greatest challenges in investigating a cross-subject biological process is that the systematic heterogeneity across individuals could significantly undermine the power of existing machine learning methods to identify the underlying biological dynamics. In addition, many technically challenging neurobiological experiments are conducted on only a handful of subjects where rich longitudinal data are available for each subject. The low sample sizes of such experiments could further reduce the power to detect common dynamic patterns among subjects. In this paper, we propose a novel heterogeneous data integration framework based on optimal transport to extract shared patterns in complex biological processes. The key advantages of the proposed method are that it can increase discriminating power in identifying common patterns by reducing heterogeneity unrelated to the signal by aligning the extracted latent spatiotemporal information across subjects. Our approach is effective even with a small number of subjects, and does not require auxiliary matching information for the alignment. In particular, our method can align longitudinal data across heterogeneous subjects in a common latent space to capture the dynamics of shared patterns while utilizing temporal dependency within subjects.
Read more7/2/2024

0
Propensity Score Alignment of Unpaired Multimodal Data
Johnny Xi, Jason Hartford
Multimodal representation learning techniques typically rely on paired samples to learn common representations, but paired samples are challenging to collect in fields such as biology where measurement devices often destroy the samples. This paper presents an approach to address the challenge of aligning unpaired samples across disparate modalities in multimodal representation learning. We draw an analogy between potential outcomes in causal inference and potential views in multimodal observations, which allows us to use Rubin's framework to estimate a common space in which to match samples. Our approach assumes we collect samples that are experimentally perturbed by treatments, and uses this to estimate a propensity score from each modality, which encapsulates all shared information between a latent state and treatment and can be used to define a distance between samples. We experiment with two alignment techniques that leverage this distance -- shared nearest neighbours (SNN) and optimal transport (OT) matching -- and find that OT matching results in significant improvements over state-of-the-art alignment approaches in both a synthetic multi-modal setting and in real-world data from NeurIPS Multimodal Single-Cell Integration Challenge.
Read more4/3/2024