oTTC: Object Time-to-Contact for Motion Estimation in Autonomous Driving
2405.07698
0
0
Abstract
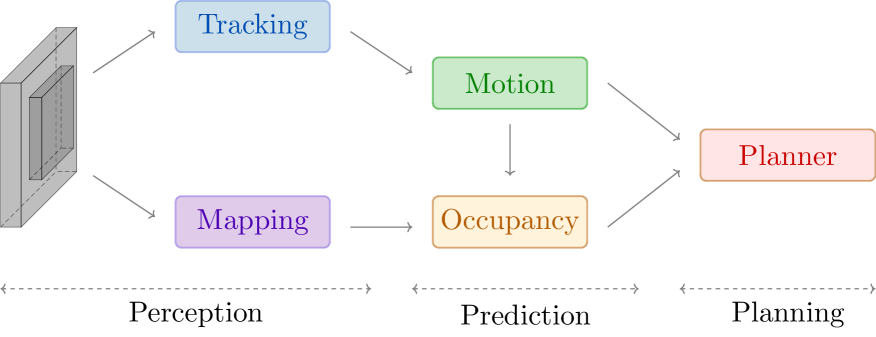
Autonomous driving systems require a quick and robust perception of the nearby environment to carry out their routines effectively. With the aim to avoid collisions and drive safely, autonomous driving systems rely heavily on object detection. However, 2D object detections alone are insufficient; more information, such as relative velocity and distance, is required for safer planning. Monocular 3D object detectors try to solve this problem by directly predicting 3D bounding boxes and object velocities given a camera image. Recent research estimates time-to-contact in a per-pixel manner and suggests that it is more effective measure than velocity and depth combined. However, per-pixel time-to-contact requires object detection to serve its purpose effectively and hence increases overall computational requirements as two different models need to run. To address this issue, we propose per-object time-to-contact estimation by extending object detection models to additionally predict the time-to-contact attribute for each object. We compare our proposed approach with existing time-to-contact methods and provide benchmarking results on well-known datasets. Our proposed approach achieves higher precision compared to prior art while using a single image.
Create account to get full access
Overview
- This paper introduces "oTTC" (Object Time-to-Contact), a novel approach for motion estimation in autonomous driving scenarios.
- oTTC leverages the time-to-contact (TTC) of detected objects to improve the accuracy and robustness of motion estimation.
- The method combines monocular vision and object detection to estimate the TTC and relative motion of surrounding vehicles, pedestrians, and other objects.
Plain English Explanation
The oTTC method is designed to help self-driving cars better understand the movement of objects around them. It uses information from a single camera to estimate how long it will take for detected objects, like other vehicles or pedestrians, to reach the self-driving car. By tracking this "time-to-contact," the system can more accurately determine the relative motion and speed of nearby objects.
This is important for autonomous driving, as it allows the car to better anticipate the movements of its surroundings and plan safer, more efficient navigation. Rather than relying solely on object detection and tracking, oTTC incorporates the time-to-contact metric to gain a more refined understanding of the dynamic environment.
Technical Explanation
The oTTC approach combines monocular vision and object detection to estimate the time-to-contact (TTC) and relative motion of surrounding objects. By analyzing the apparent size changes of detected objects over time, the system can infer their distance and rate of approach.
This builds on earlier work on instantaneous perception of moving objects in 3D and ensuring UAV safety through vision-only real-time motion estimation. The authors leverage these techniques to develop a motion estimation pipeline specifically tailored for autonomous driving scenarios.
The method first detects and tracks objects in the camera feed using a deep learning-based object detector, such as Deep Event-Based Object Detection for Autonomous Driving. It then estimates the time-to-contact for each detected object by analyzing its apparent size changes over time.
This TTC information is combined with the object's position and velocity to derive a more complete understanding of its motion relative to the self-driving car. The authors demonstrate how this can improve the accuracy and robustness of motion estimation, particularly in challenging scenarios like multi-object tracking with camera-LiDAR fusion.
Critical Analysis
The authors acknowledge that the oTTC approach has some limitations. For example, it relies on accurate object detection and tracking, which can be challenging in crowded or occluded environments. Additionally, the TTC estimation may be affected by factors like object shape and orientation, which are not explicitly accounted for in the current implementation.
Further research could explore ways to make the oTTC method more robust to these types of challenges, such as incorporating additional sensor data or advanced deep learning techniques for object detection and tracking. The authors also suggest that the approach could be extended to handle a wider range of object types, beyond just vehicles and pedestrians.
Conclusion
The oTTC method presented in this paper offers a promising approach for improving motion estimation in autonomous driving scenarios. By leveraging the time-to-contact of detected objects, the system can gain a more nuanced understanding of the dynamic environment, which is crucial for safe and efficient navigation. While the current implementation has some limitations, the authors have demonstrated the potential of this technique and outlined avenues for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Instantaneous Perception of Moving Objects in 3D
Di Liu, Bingbing Zhuang, Dimitris N. Metaxas, Manmohan Chandraker
0
0
The perception of 3D motion of surrounding traffic participants is crucial for driving safety. While existing works primarily focus on general large motions, we contend that the instantaneous detection and quantification of subtle motions is equally important as they indicate the nuances in driving behavior that may be safety critical, such as behaviors near a stop sign of parking positions. We delve into this under-explored task, examining its unique challenges and developing our solution, accompanied by a carefully designed benchmark. Specifically, due to the lack of correspondences between consecutive frames of sparse Lidar point clouds, static objects might appear to be moving - the so-called swimming effect. This intertwines with the true object motion, thereby posing ambiguity in accurate estimation, especially for subtle motions. To address this, we propose to leverage local occupancy completion of object point clouds to densify the shape cue, and mitigate the impact of swimming artifacts. The occupancy completion is learned in an end-to-end fashion together with the detection of moving objects and the estimation of their motion, instantaneously as soon as objects start to move. Extensive experiments demonstrate superior performance compared to standard 3D motion estimation approaches, particularly highlighting our method's specialized treatment of subtle motions.
5/7/2024
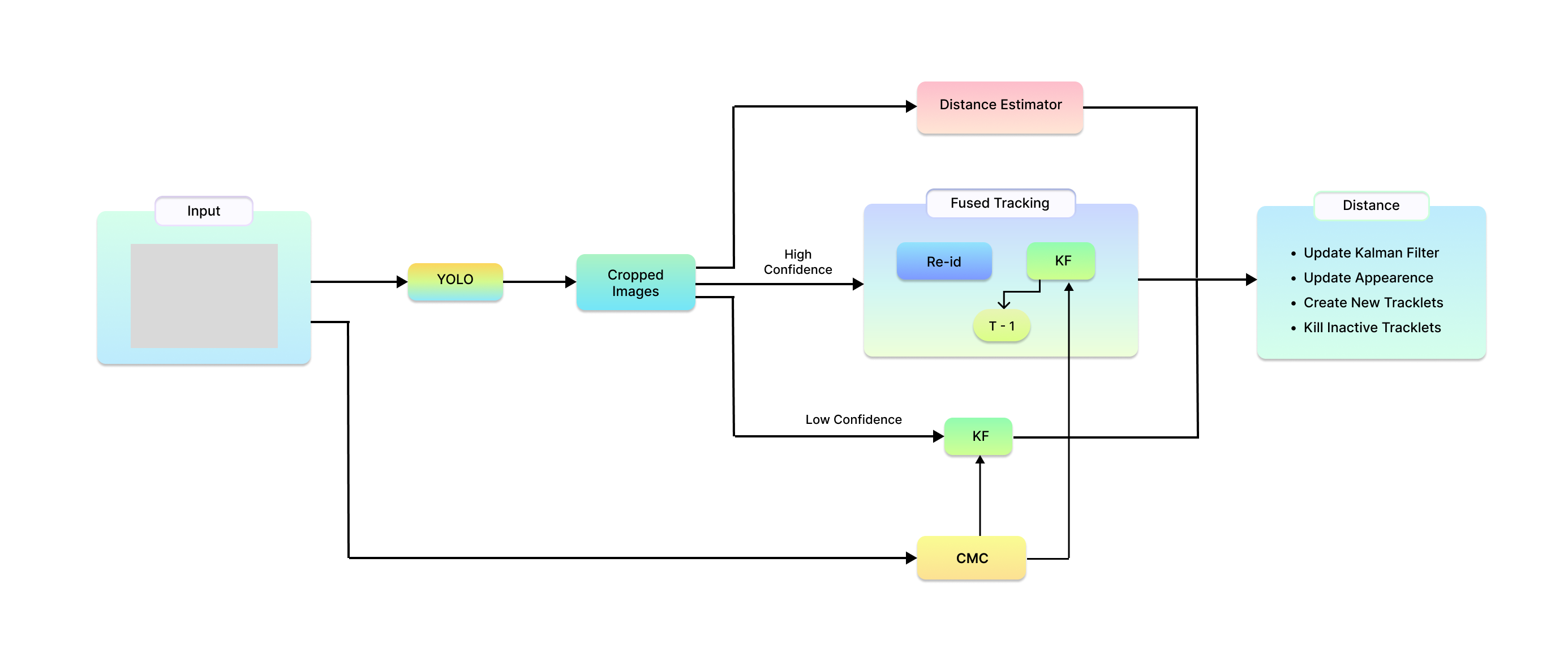
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
0
0
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
5/17/2024

Deep Event-based Object Detection in Autonomous Driving: A Survey
Bingquan Zhou, Jie Jiang
0
0
Object detection plays a critical role in autonomous driving, where accurately and efficiently detecting objects in fast-moving scenes is crucial. Traditional frame-based cameras face challenges in balancing latency and bandwidth, necessitating the need for innovative solutions. Event cameras have emerged as promising sensors for autonomous driving due to their low latency, high dynamic range, and low power consumption. However, effectively utilizing the asynchronous and sparse event data presents challenges, particularly in maintaining low latency and lightweight architectures for object detection. This paper provides an overview of object detection using event data in autonomous driving, showcasing the competitive benefits of event cameras.
5/8/2024
🔎
UncertaintyTrack: Exploiting Detection and Localization Uncertainty in Multi-Object Tracking
Chang Won Lee, Steven L. Waslander
0
0
Multi-object tracking (MOT) methods have seen a significant boost in performance recently, due to strong interest from the research community and steadily improving object detection methods. The majority of tracking methods follow the tracking-by-detection (TBD) paradigm, blindly trust the incoming detections with no sense of their associated localization uncertainty. This lack of uncertainty awareness poses a problem in safety-critical tasks such as autonomous driving where passengers could be put at risk due to erroneous detections that have propagated to downstream tasks, including MOT. While there are existing works in probabilistic object detection that predict the localization uncertainty around the boxes, no work in 2D MOT for autonomous driving has studied whether these estimates are meaningful enough to be leveraged effectively in object tracking. We introduce UncertaintyTrack, a collection of extensions that can be applied to multiple TBD trackers to account for localization uncertainty estimates from probabilistic object detectors. Experiments on the Berkeley Deep Drive MOT dataset show that the combination of our method and informative uncertainty estimates reduces the number of ID switches by around 19% and improves mMOTA by 2-3%. The source code is available at https://github.com/TRAILab/UncertaintyTrack
5/1/2024