OutlierTune: Efficient Channel-Wise Quantization for Large Language Models

0

Sign in to get full access
Overview
- This paper proposes a novel quantization technique called OutlierTune that efficiently compresses large language models (LLMs) by leveraging channel-wise quantization.
- The method focuses on mitigating the impact of outlier channels, which can degrade the performance of traditional quantization approaches.
- The authors demonstrate the effectiveness of OutlierTune on several benchmark LLMs, showing significant compression with minimal accuracy loss.
Plain English Explanation
OutlierTune: Efficient Channel-Wise Quantization for Large Language Models is a research paper that presents a new way to compress large language models (LLMs) while preserving their performance. LLMs are powerful AI systems that can understand and generate human-like text, but they are also very large and resource-intensive, making them challenging to deploy on smaller devices or in low-power settings.
The key idea behind OutlierTune is to focus on the "outlier channels" in the LLM. These are the parts of the model that behave differently from the majority and can cause problems when trying to compress the model. The researchers developed a technique that can identify and handle these outlier channels more effectively, allowing for greater compression without significant loss of accuracy.
The paper demonstrates the effectiveness of OutlierTune on several popular LLMs, such as GPT-3 and BERT. They show that their method can achieve significant compression (up to 8x) while maintaining the model's performance on various tasks, such as text generation and question answering.
This research is important because it could enable the deployment of powerful LLMs on a wider range of devices, from smartphones to edge devices, by reducing their memory and computational requirements. This could have a significant impact on applications like personalized assistants, language translation, and [content generation**, making these technologies more accessible and widely available.
Technical Explanation
OutlierTune: Efficient Channel-Wise Quantization for Large Language Models introduces a novel quantization technique that leverages channel-wise statistics to mitigate the impact of outlier channels in large language models (LLMs).
The authors first observe that traditional quantization approaches, which apply uniform scaling and quantization across all channels, can be suboptimal due to the presence of outlier channels. These outlier channels exhibit significantly different value distributions compared to the majority of channels, and they can degrade the overall quantization performance when not handled appropriately.
To address this issue, OutlierTune employs a channel-wise quantization strategy that adaptively scales and quantizes each channel based on its own statistical properties. This allows the method to better capture the unique characteristics of each channel, reducing the impact of outlier channels on the overall model performance.
The authors evaluate OutlierTune on several benchmark LLMs, including GPT-3, BERT, and RoBERTa, across various tasks such as text generation, question answering, and natural language inference. The results show that OutlierTune can achieve significant compression (up to 8x) with minimal accuracy degradation compared to the original full-precision models.
Additionally, the authors provide a comprehensive analysis of the impact of outlier channels on quantization performance and demonstrate the effectiveness of their channel-wise approach in mitigating this issue. They also investigate the relationship between model size, outlier channel prevalence, and quantization performance, offering valuable insights for the design and optimization of efficient quantized LLMs.
Critical Analysis
The OutlierTune paper presents a well-designed and thorough investigation of the impact of outlier channels on the quantization of large language models. The authors' channel-wise quantization approach is a thoughtful and effective solution to a practical challenge in model compression.
One potential limitation of the study is that it focuses primarily on evaluating OutlierTune on a limited set of benchmark LLMs and tasks. While the results are promising, it would be valuable to explore the method's performance on a wider range of LLMs and application domains to fully assess its generalizability.
Additionally, the paper does not address the computational overhead or inference latency introduced by the channel-wise quantization process. In some real-world deployment scenarios, these factors may be equally important as the achieved compression ratio and accuracy.
Further research could also explore the interaction between OutlierTune and other model compression techniques, such as weight pruning or knowledge distillation, to unlock even greater efficiency gains while maintaining model performance.
Overall, the OutlierTune paper represents an important contribution to the field of efficient large language model deployment, and the authors' channel-wise quantization approach offers a promising direction for further exploration and refinement.
Conclusion
The OutlierTune paper introduces a novel quantization technique that addresses the challenge of outlier channels in large language models. By employing a channel-wise quantization strategy, the method can achieve significant compression while maintaining the models' performance on various tasks.
This research is significant because it could enable the wider deployment of powerful language models on a range of devices, from smartphones to edge devices, by reducing their memory and computational requirements. This could have far-reaching implications for applications such as personalized assistants, language translation, and content generation, making these technologies more accessible and widely available.
The authors' comprehensive analysis and the promising results presented in this paper highlight the importance of addressing the challenges of model compression and the need for continued research in this area. As the field of large language models continues to evolve, techniques like OutlierTune will play a crucial role in ensuring the efficient and widespread adoption of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OutlierTune: Efficient Channel-Wise Quantization for Large Language Models
Jinguang Wang, Yuexi Yin, Haifeng Sun, Qi Qi, Jingyu Wang, Zirui Zhuang, Tingting Yang, Jianxin Liao
Quantizing the activations of large language models (LLMs) has been a significant challenge due to the presence of structured outliers. Most existing methods focus on the per-token or per-tensor quantization of activations, making it difficult to achieve both accuracy and hardware efficiency. To address this problem, we propose OutlierTune, an efficient per-channel post-training quantization (PTQ) method for the activations of LLMs. OutlierTune consists of two components: pre-execution of dequantization and symmetrization. The pre-execution of dequantization updates the model weights by the activation scaling factors, avoiding the internal scaling and costly additional computational overheads brought by the per-channel activation quantization. The symmetrization further reduces the quantization differences arising from the weight updates by ensuring the balanced numerical ranges across different activation channels. OutlierTune is easy to implement and hardware-efficient, introducing almost no additional computational overheads during the inference. Extensive experiments show that the proposed framework outperforms existing methods across multiple different tasks. Demonstrating better generalization, this framework improves the Int6 quantization of the instruction-tuning LLMs, such as OPT-IML, to the same level as half-precision (FP16). Moreover, we have shown that the proposed framework is 1.48x faster than the FP16 implementation while reducing approximately 2x memory usage.
Read more6/28/2024
💬
0
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
Read more4/9/2024
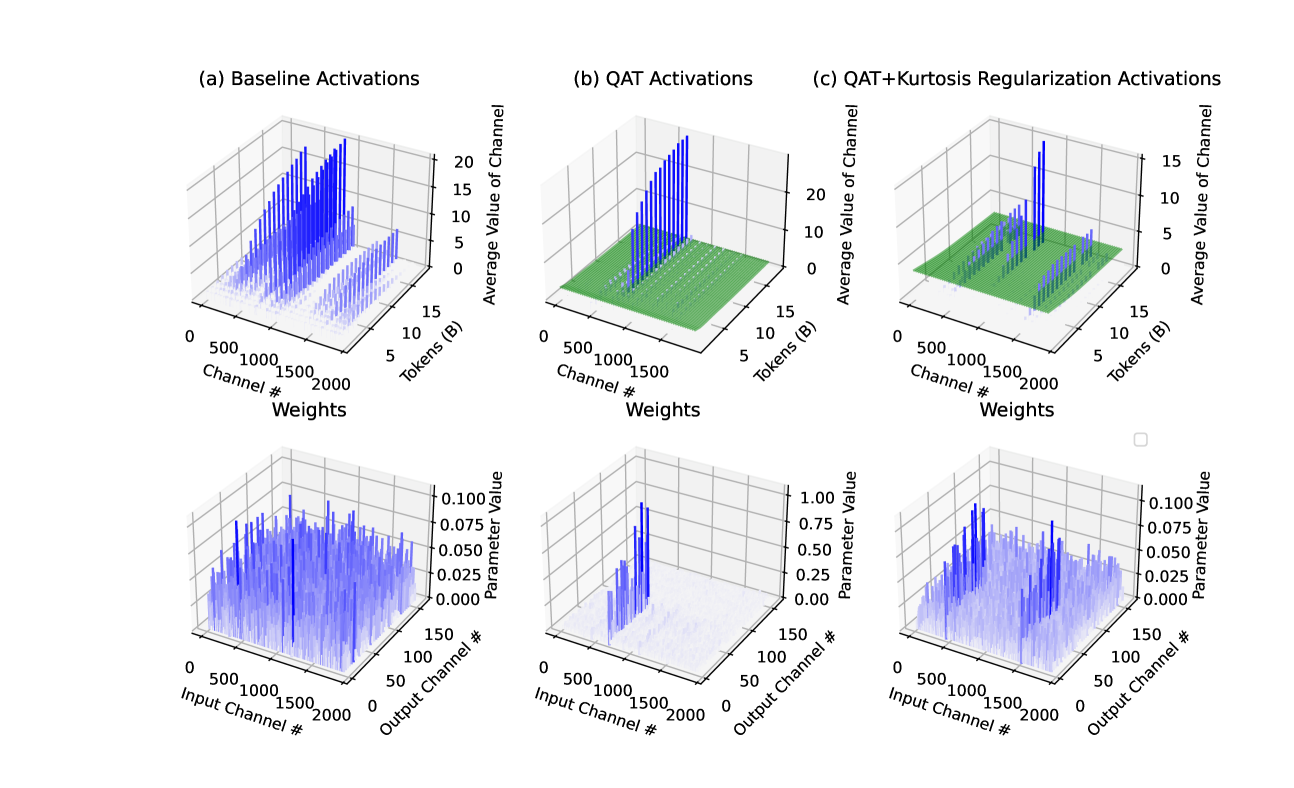
0
Mitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization
Aniruddha Nrusimha, Mayank Mishra, Naigang Wang, Dan Alistarh, Rameswar Panda, Yoon Kim
We consider the problem of accurate quantization for language models, where both the weights and activations are uniformly quantized to 4 bits per parameter, the lowest bitwidth format natively supported by GPU hardware. In this context, the key challenge is activation quantization: it is known that language models contain outlier channels whose values on average are orders of magnitude higher than than other channels, which prevents accurate low-bitwidth quantization with known techniques. We systematically study this phenomena and find that these outlier channels emerge early in training, and that they occur more frequently in layers with residual streams. We then propose a simple strategy which regularizes a layer's inputs via quantization-aware training (QAT) and its outputs via activation kurtosis regularization. We show that regularizing both the inputs and outputs is crucial for preventing a model's migrating the difficulty in input quantization to the weights, which makes post-training quantization (PTQ) of weights more difficult. When combined with weight PTQ, we show that our approach can obtain a W4A4 model that performs competitively to the standard-precision W16A16 baseline.
Read more8/28/2024
💬
1
Evaluating Quantized Large Language Models
Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions. The code can be found in https://github.com/thu-nics/qllm-eval.
Read more6/7/2024