PAAM: A Framework for Coordinated and Priority-Driven Accelerator Management in ROS 2
2404.06452
0
0
Abstract
This paper proposes a Priority-driven Accelerator Access Management (PAAM) framework for multi-process robotic applications built on top of the Robot Operating System (ROS) 2 middleware platform. The framework addresses the issue of predictable execution of time- and safety-critical callback chains that require hardware accelerators such as GPUs and TPUs. PAAM provides a standalone ROS executor that acts as an accelerator resource server, arbitrating accelerator access requests from all other callbacks at the application layer. This approach enables coordinated and priority-driven accelerator access management in multi-process robotic systems. The framework design is directly applicable to all types of accelerators and enables granular control over how specific chains access accelerators, making it possible to achieve predictable real-time support for accelerators used by safety-critical callback chains without making changes to underlying accelerator device drivers. The paper shows that PAAM also offers a theoretical analysis that can upper bound the worst-case response time of safety-critical callback chains that necessitate accelerator access. This paper also demonstrates that complex robotic systems with extensive accelerator usage that are integrated with PAAM may achieve up to a 91% reduction in end-to-end response time of their critical callback chains.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a framework called PAAM (Priority-Driven Accelerator Management) for coordinating and managing the use of hardware accelerators in Robot Operating System 2 (ROS 2) applications.
- The framework aims to enable efficient and priority-based utilization of accelerators, such as GPUs and FPGAs, to improve the performance of ROS 2 systems.
- PAAM provides mechanisms for task prioritization, resource allocation, and load balancing to ensure that high-priority tasks can access accelerators when needed.
Plain English Explanation
In modern robotic systems, many computationally intensive tasks, such as computer vision, object recognition, and motion planning, can be accelerated by using specialized hardware like GPUs or FPGAs. The PAAM framework aims to make it easier for robotic systems built on the ROS 2 platform to take advantage of these hardware accelerators.
The key idea behind PAAM is to provide a way to prioritize the use of accelerators, so that the most important tasks can get access to them first. This is important because in a complex robotic system, there may be many different tasks competing for the limited accelerator resources. By using PAAM, system designers can ensure that high-priority tasks, such as those related to safety or mission-critical functions, are given preference when it comes to using the available accelerators.
PAAM achieves this prioritization through a few mechanisms. First, it allows tasks to be assigned different levels of priority, so that the system knows which ones are the most important. Second, it manages the allocation of accelerator resources, making sure that high-priority tasks can access the resources they need. And third, it tries to balance the load across the available accelerators, ensuring that no single accelerator becomes a bottleneck.
Overall, the PAAM framework provides a way to optimize the performance of ROS 2 systems by coordinating the use of hardware accelerators in a way that aligns with the priorities and requirements of the overall system.
Technical Explanation
The PAAM framework is designed to be integrated into the ROS 2 ecosystem, allowing ROS 2 applications to leverage hardware accelerators more effectively. It consists of several key components:
-
Task Prioritization: PAAM allows ROS 2 tasks to be assigned different priority levels, which are used to determine the order in which they can access accelerator resources.
-
Resource Allocation: PAAM manages the allocation of accelerator resources, such as GPUs and FPGAs, to ensure that high-priority tasks can access the resources they need.
-
Load Balancing: PAAM attempts to balance the load across the available accelerators, preventing any single accelerator from becoming a bottleneck.
-
Monitoring and Adaptation: PAAM continuously monitors the usage of accelerators and adapts the resource allocation and load balancing as needed to maintain optimal performance.
The framework is implemented as a set of ROS 2 nodes and services that interact with the ROS 2 application and the underlying accelerator hardware. It leverages the ROS 2 lifecycle management and ROS 2 quality of service features to ensure reliable and predictable behavior.
The authors evaluate the PAAM framework through both simulation and real-world experiments, demonstrating its ability to improve the performance of ROS 2 applications by efficiently coordinating the use of hardware accelerators.
Critical Analysis
The PAAM framework addresses an important challenge in modern robotic systems, which is the need to effectively utilize hardware accelerators to improve the performance of computationally intensive tasks. The authors have presented a well-designed and comprehensive solution that integrates seamlessly with the ROS 2 ecosystem.
One potential limitation of the PAAM framework is that it assumes the availability of sufficient accelerator resources to meet the demands of the ROS 2 application. In real-world scenarios, there may be cases where the number of available accelerators is limited, and PAAM would need to make difficult trade-offs in resource allocation. The authors do not explore this scenario in depth, and it would be valuable to see how PAAM would handle such resource-constrained situations.
Additionally, the PAAM framework currently focuses on managing the use of accelerators, but it does not address the broader question of how to optimize the placement and distribution of accelerators within a robotic system. This could be an interesting area for future research, where PAAM could be extended to incorporate strategies for optimizing the physical layout and configuration of accelerator resources.
Overall, the PAAM framework represents a significant contribution to the field of robotics, as it provides a practical and effective solution for leveraging hardware accelerators in ROS 2 applications. The authors have demonstrated the framework's capabilities through rigorous evaluation, and the framework's integration with the ROS 2 ecosystem makes it a valuable tool for the robotics community.
Conclusion
The PAAM framework presented in this paper addresses an important challenge in modern robotic systems: the need to efficiently utilize hardware accelerators, such as GPUs and FPGAs, to improve the performance of computationally intensive tasks. By providing mechanisms for task prioritization, resource allocation, and load balancing, PAAM enables ROS 2 applications to take full advantage of available accelerator resources and ensure that high-priority tasks can access the resources they need.
The authors have demonstrated the effectiveness of the PAAM framework through extensive evaluation, both in simulation and in real-world experiments. While the framework has some potential limitations, such as its assumption of sufficient accelerator resources, it represents a significant contribution to the field of robotics and is a valuable tool for ROS 2 system designers.
As robotic systems continue to grow in complexity and the demand for computational power increases, frameworks like PAAM will become increasingly important for optimizing the performance and reliability of these systems. The insights and techniques presented in this paper can inform future research and development in the area of hardware acceleration and resource management for robotic applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Frontier Management for Collaborative Active SLAM
Muhammad Farhan Ahmed, Matteo Maragliano, Vincent FremontCarmine, Tommaso Recchiuto, Antonio Sgorbissa
0
0
In autonomous robotics, a critical challenge lies in developing robust solutions for Active Collaborative SLAM, wherein multiple robots collaboratively explore and map an unknown environment while intelligently coordinating their movements and sensor data acquisitions. In this article, we present an efficient centralized frontier sharing approach that maximizes exploration by taking into account information gain in the merged map, distance, and reward computation among frontier candidates and encourages the spread of agents into the environment. Eventually, our method efficiently spreads the robots for maximum exploration while keeping SLAM uncertainty low. Additionally, we also present two coordination approaches, synchronous and asynchronous to prioritize robot goal assignments by the central server. The proposed method is implemented in ROS and evaluated through simulation and experiments on publicly available datasets and similar methods, rendering promising results.
5/16/2024
Delay-Aware Multi-Agent Reinforcement Learning for Cooperative Adaptive Cruise Control with Model-based Stability Enhancement
Jiaqi Liu, Ziran Wang, Peng Hang, Jian Sun
0
0
Cooperative Adaptive Cruise Control (CACC) represents a quintessential control strategy for orchestrating vehicular platoon movement within Connected and Automated Vehicle (CAV) systems, significantly enhancing traffic efficiency and reducing energy consumption. In recent years, the data-driven methods, such as reinforcement learning (RL), have been employed to address this task due to their significant advantages in terms of efficiency and flexibility. However, the delay issue, which often arises in real-world CACC systems, is rarely taken into account by current RL-based approaches. To tackle this problem, we propose a Delay-Aware Multi-Agent Reinforcement Learning (DAMARL) framework aimed at achieving safe and stable control for CACC. We model the entire decision-making process using a Multi-Agent Delay-Aware Markov Decision Process (MADA-MDP) and develop a centralized training with decentralized execution (CTDE) MARL framework for distributed control of CACC platoons. An attention mechanism-integrated policy network is introduced to enhance the performance of CAV communication and decision-making. Additionally, a velocity optimization model-based action filter is incorporated to further ensure the stability of the platoon. Experimental results across various delay conditions and platoon sizes demonstrate that our approach consistently outperforms baseline methods in terms of platoon safety, stability and overall performance.
5/14/2024
🎲
Towards a Safe Real-Time Motion Planning Framework for Autonomous Driving Systems: An MPPI Approach
Mehdi Testouri, Gamal Elghazaly, Raphael Frank
0
0
Planning safe trajectories in Autonomous Driving Systems (ADS) is a complex problem to solve in real-time. The main challenge to solve this problem arises from the various conditions and constraints imposed by road geometry, semantics and traffic rules, as well as the presence of dynamic agents. Recently, Model Predictive Path Integral (MPPI) has shown to be an effective framework for optimal motion planning and control in robot navigation in unstructured and highly uncertain environments. In this paper, we formulate the motion planning problem in ADS as a nonlinear stochastic dynamic optimization problem that can be solved using an MPPI strategy. The main technical contribution of this work is a method to handle obstacles within the MPPI formulation safely. In this method, obstacles are approximated by circles that can be easily integrated into the MPPI cost formulation while considering safety margins. The proposed MPPI framework has been efficiently implemented in our autonomous vehicle and experimentally validated using three different primitive scenarios. Experimental results show that generated trajectories are safe, feasible and perfectly achieve the planning objective. The video results as well as the open-source implementation are available at: https://gitlab.uni.lu/360lab-public/mppi
5/7/2024
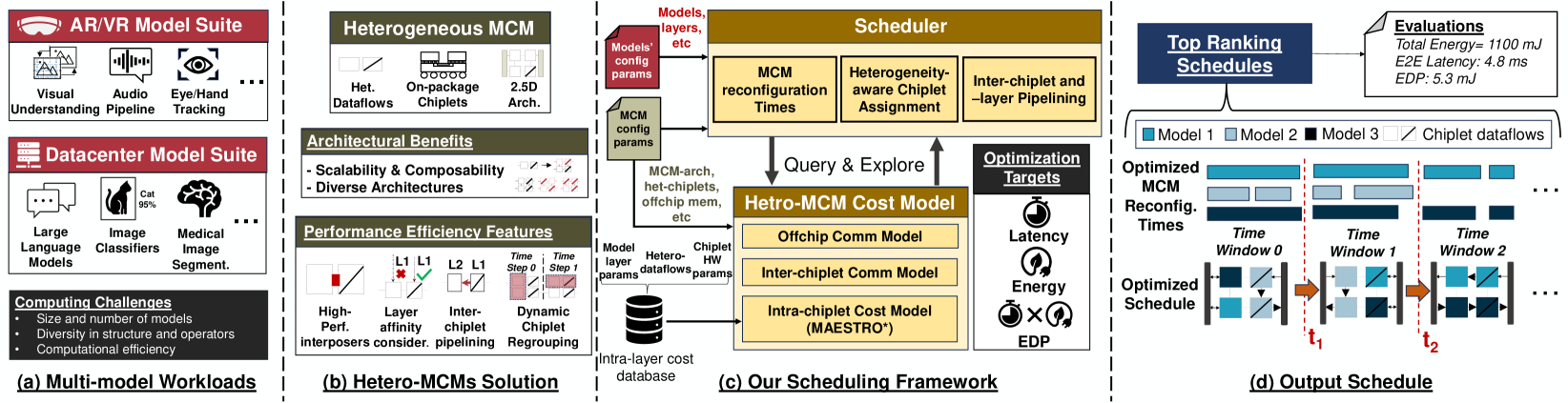
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
Mohanad Odema, Luke Chen, Hyoukjun Kwon, Mohammad Abdullah Al Faruque
0
0
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^18) scale even for a single model case on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 35.3% and 31.4% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
5/3/2024