SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators

0
Sign in to get full access
Overview
- This paper presents SCAR, a scheduling framework for efficiently running multiple AI models on heterogeneous multi-chiplet accelerators.
- SCAR aims to address the challenges of scheduling diverse AI workloads on complex hardware platforms with multiple chiplets and heterogeneous compute resources.
- The key innovations of SCAR include a hardware-aware model placement strategy, an adaptive scheduling algorithm, and a multi-model execution engine.
Plain English Explanation
AI systems are becoming increasingly complex, with the need to run multiple machine learning models simultaneously on specialized hardware. This paper describes SCAR, a scheduling framework that helps efficiently allocate these diverse AI workloads on heterogeneous hardware platforms with multiple chiplets.
Chiplets are smaller, modular chip components that can be combined to create more powerful processors. SCAR is designed to work with these multi-chiplet accelerators, which have different types of compute resources like CPUs, GPUs, and custom AI accelerators. The key innovations in SCAR include:
- A smart model placement strategy that considers the hardware capabilities to determine the best location for each AI model.
- An adaptive scheduling algorithm that can dynamically adjust to changes in the workload and available resources.
- A multi-model execution engine that enables concurrent execution of different AI models on the heterogeneous hardware.
By intelligently scheduling and running multiple AI models on these complex, multi-chiplet hardware platforms, SCAR aims to improve the efficiency and performance of AI systems. This could benefit a wide range of applications, from recommendation systems to increasingly realistic AI models.
Technical Explanation
SCAR is a scheduling framework designed to efficiently allocate diverse AI workloads on heterogeneous multi-chiplet accelerators. The key innovations in SCAR include:
-
Hardware-Aware Model Placement: SCAR uses a model placement strategy that considers the hardware capabilities of the different chiplets, such as their compute power, memory, and specialized accelerators. This allows SCAR to determine the optimal location for each AI model to maximize performance.
-
Adaptive Scheduling Algorithm: SCAR employs a dynamic scheduling algorithm that can adapt to changes in the workload and available resources. This enables SCAR to optimize the offload performance of the AI models and ensure efficient utilization of the hardware.
-
Multi-Model Execution Engine: SCAR's multi-model execution engine allows for the concurrent execution of different AI models on the heterogeneous hardware resources. This helps to maximize the utilization of the available compute resources and improve the overall throughput of the AI system.
The paper presents a detailed evaluation of SCAR using a variety of AI workloads and hardware configurations. The results demonstrate that SCAR can significantly improve the performance and efficiency of running multiple AI models on heterogeneous multi-chiplet accelerators compared to traditional scheduling approaches.
Critical Analysis
The paper provides a comprehensive and technically sound approach to scheduling AI workloads on complex, heterogeneous hardware platforms. The authors have carefully designed SCAR to address the key challenges in this domain, such as model placement, dynamic scheduling, and multi-model execution.
One potential limitation of the research is that it focuses primarily on the scheduling aspect and does not delve deeply into the hardware design or the specific hardware capabilities of the multi-chiplet accelerators. Further research could explore the optimization of the hardware architecture to better support the requirements of diverse AI workloads.
Additionally, the paper does not discuss the implications of SCAR's scheduling decisions on factors like energy efficiency, system reliability, or the potential for hardware resource contention. These aspects could be valuable to consider in future work to provide a more comprehensive understanding of the trade-offs and limitations of the proposed approach.
Conclusion
SCAR is a promising scheduling framework that addresses the challenges of running multiple AI models on heterogeneous multi-chiplet accelerators. By leveraging innovative model placement, adaptive scheduling, and multi-model execution, SCAR can significantly improve the performance and efficiency of AI systems.
This research has the potential to contribute to the development of more powerful and versatile AI hardware platforms, enabling the deployment of complex, multi-model AI applications in a wide range of domains, from recommendation systems to increasingly realistic AI models. As the demand for efficient AI computing continues to grow, frameworks like SCAR will play a crucial role in optimizing the utilization of these specialized hardware resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
Mohanad Odema, Luke Chen, Hyoukjun Kwon, Mohammad Abdullah Al Faruque
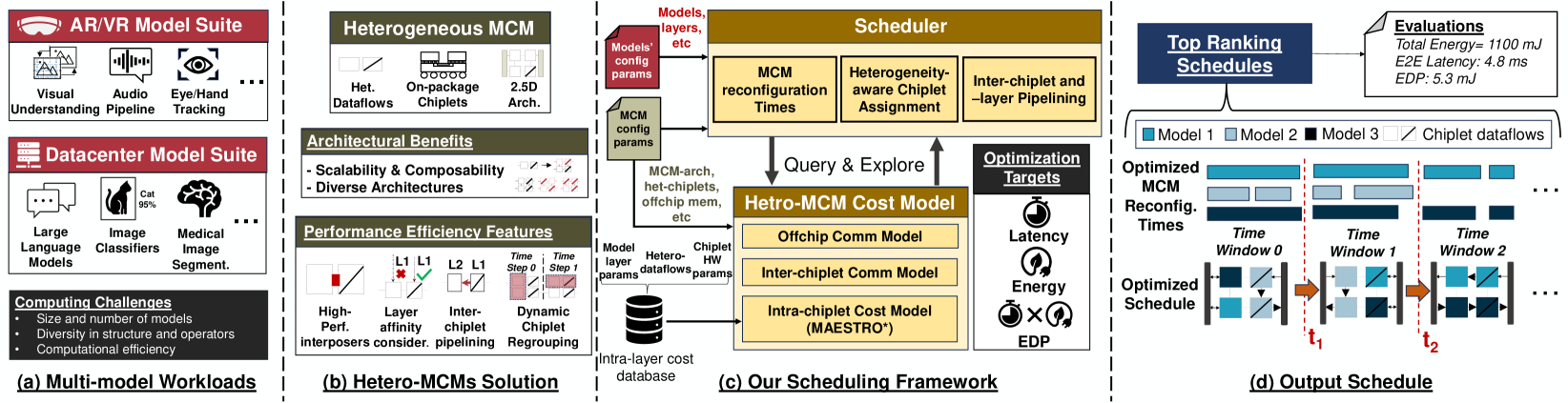
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^56) even for a two-model workload on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler, SCAR, with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 27.6% and 29.6% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
Read more9/17/2024
📈
0
Efficient Multi-Task Large Model Training via Data Heterogeneity-aware Model Management
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
Recent foundation models are capable of handling multiple machine learning (ML) tasks and multiple data modalities with the unified base model structure and several specialized model components. However, the development of such multi-task (MT) multi-modal (MM) models poses significant model management challenges to existing training systems. Due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities, training these models usually requires massive GPU resources and suffers from sub-optimal system efficiency. In this paper, we investigate how to achieve high-performance training of large-scale MT MM models through data heterogeneity-aware model management optimization. The key idea is to decompose the model execution into stages and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling. Based on this, we build a prototype system and evaluate it on various large MT MM models. Experiments demonstrate the superior performance and efficiency of our system, with speedup ratio up to 71% compared to state-of-the-art training systems.
Read more9/6/2024

0
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
Si Xu, Zixiao Huang, Yan Zeng, Shengen Yan, Xuefei Ning, Quanlu Zhang, Haolin Ye, Sipei Gu, Chunsheng Shui, Zhezheng Lin, Hao Zhang, Sheng Wang, Guohao Dai, Yu Wang
Training large-scale models relies on a vast number of computing resources. For example, training the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs . It is a challenge to build a large-scale cluster with one type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a large-scale cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not support heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism, HETHUB, for large-scale models, which supports heterogeneous cluster, including AMD, Nvidia GPU and other types of GPU-accelerators . It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic parallel planner to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six combinations of heterogeneous GPU-accelerators. We train the Llama-140B model on a heterogeneous cluster with 768 GPU-accelerators(128 AMD and 640 GPU-accelerator A). The experiment results show that the optimal performance of our system in the heterogeneous cluster has achieved up to 97.49% of the theoretical upper bound performance.
Read more8/12/2024
🤿
0
Workload-Aware Hardware Accelerator Mining for Distributed Deep Learning Training
Muhammad Adnan, Amar Phanishayee, Janardhan Kulkarni, Prashant J. Nair, Divya Mahajan
In this paper, we present a novel technique to search for hardware architectures of accelerators optimized for end-to-end training of deep neural networks (DNNs). Our approach addresses both single-device and distributed pipeline and tensor model parallel scenarios, latter being addressed for the first time. The search optimized accelerators for training relevant metrics such as throughput/TDP under a fixed area and power constraints. However, with the proliferation of specialized architectures and complex distributed training mechanisms, the design space exploration of hardware accelerators is very large. Prior work in this space has tried to tackle this by reducing the search space to either a single accelerator execution that too only for inference, or tuning the architecture for specific layers (e.g., convolution). Instead, we take a unique heuristic-based critical path-based approach to determine the best use of available resources (power and area) either for a set of DNN workloads or each workload individually. First, we perform local search to determine the architecture for each pipeline and tensor model stage. Specifically, the system iteratively generates architectural configurations and tunes the design using a novel heuristic-based approach that prioritizes accelerator resources and scheduling to critical operators in a machine learning workload. Second, to address the complexities of distributed training, the local search selects multiple (k) designs per stage. A global search then identifies an accelerator from the top-k sets to optimize training throughput across the stages. We evaluate this work on 11 different DNN models. Compared to a recent inference-only work Spotlight, our method converges to a design in, on average, 31x less time and offers 12x higher throughput. Moreover, designs generated using our method achieve 12% throughput improvement over TPU architecture.
Read more4/24/2024