PairCFR: Enhancing Model Training on Paired Counterfactually Augmented Data through Contrastive Learning
2406.06633
0
0

Abstract
Counterfactually Augmented Data (CAD) involves creating new data samples by applying minimal yet sufficient modifications to flip the label of existing data samples to other classes. Training with CAD enhances model robustness against spurious features that happen to correlate with labels by spreading the casual relationships across different classes. Yet, recent research reveals that training with CAD may lead models to overly focus on modified features while ignoring other important contextual information, inadvertently introducing biases that may impair performance on out-ofdistribution (OOD) datasets. To mitigate this issue, we employ contrastive learning to promote global feature alignment in addition to learning counterfactual clues. We theoretically prove that contrastive loss can encourage models to leverage a broader range of features beyond those modified ones. Comprehensive experiments on two human-edited CAD datasets demonstrate that our proposed method outperforms the state-of-the-art on OOD datasets.
Create account to get full access
Overview
- This paper introduces a new approach called "PairCFR" that uses contrastive learning to enhance model training on paired counterfactually augmented data.
- Counterfactual examples are data points that are similar to the original data but with a different outcome or label.
- PairCFR aims to improve model performance by leveraging the information in paired counterfactual examples through contrastive learning.
Plain English Explanation
Imagine you're training an AI model to predict whether a person will buy a product or not. Normally, you'd use real customer data to train the model. But what if you could also use "what-if" scenarios - data that shows what would happen if certain factors were different?
For example, the model might learn that customers are more likely to buy if they have a higher income. With counterfactual data, you could show the model examples of customers who are similar but have a lower income, and see how that changes the predicted outcome.
The paper on utilizing adversarial examples for bias mitigation and accuracy enhancement explores a similar idea, but with adversarial examples instead of counterfactual ones.
The researchers behind this paper, PairCFR, found that by using a special kind of machine learning called "contrastive learning" to compare the original data and the counterfactual data, they could help the model learn more effectively. This allows the model to better understand the nuances that lead to different outcomes, which can improve its overall performance.
Technical Explanation
The key idea behind PairCFR is to leverage the information contained in paired counterfactual examples through contrastive learning. Contrastive learning is a machine learning technique that trains models to distinguish between related but different data points, rather than just classifying them.
In the context of this paper, the researchers use contrastive learning to train the model to differentiate between the original data points and their counterfactual counterparts. This helps the model learn more robust and generalizable representations, as it needs to understand the subtle differences that lead to different outcomes.
The PairCFR framework consists of three main components:
-
Counterfactual Data Generation: The researchers use a pre-trained model to generate counterfactual examples for each data point in the training set. These counterfactuals are designed to be similar to the original data but with a different outcome.
-
Contrastive Learning: The model is trained using a contrastive loss function that encourages it to learn representations that can distinguish between the original data and the counterfactual data. This helps the model better understand the nuances that lead to different outcomes.
-
Fine-tuning: After the contrastive learning stage, the model is fine-tuned on the original task (e.g., product purchase prediction) using the paired counterfactual data.
The researchers evaluate PairCFR on several benchmark datasets and show that it consistently outperforms both the baseline model trained on the original data and models that use traditional data augmentation techniques.
Critical Analysis
One potential limitation of the PairCFR approach is its reliance on the quality of the counterfactual examples generated by the pre-trained model. If the counterfactuals are not sufficiently similar to the original data or do not capture the relevant nuances, the contrastive learning process may not be as effective.
Additionally, the paper does not address the computational cost of generating and training on the paired counterfactual data. This could be a concern, especially for large-scale datasets or real-time applications.
Further research could explore ways to make the counterfactual generation process more efficient or to integrate the contrastive learning directly into the main model training procedure, rather than as a separate pre-training step.
Despite these potential limitations, the PairCFR approach represents an interesting and promising direction for leveraging counterfactual information to improve model performance, especially in domains where understanding the nuances of how different factors influence outcomes is crucial.
Conclusion
The PairCFR paper introduces a novel approach that uses contrastive learning to enhance model training on paired counterfactually augmented data. By explicitly comparing the original data and the counterfactual data, the model can learn more robust and generalizable representations, leading to improved performance on the target task.
This research builds upon previous work on using counterfactual and adversarial examples to improve model training, and represents an exciting step forward in the field of machine learning. As AI models become more widely deployed in high-stakes domains, techniques like PairCFR that can help models better understand the nuances of their decision-making could become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Do Counterfactual Examples Complicate Adversarial Training?
Eric Yeats, Cameron Darwin, Eduardo Ortega, Frank Liu, Hai Li
0
0
We leverage diffusion models to study the robustness-performance tradeoff of robust classifiers. Our approach introduces a simple, pretrained diffusion method to generate low-norm counterfactual examples (CEs): semantically altered data which results in different true class membership. We report that the confidence and accuracy of robust models on their clean training data are associated with the proximity of the data to their CEs. Moreover, robust models perform very poorly when evaluated on the CEs directly, as they become increasingly invariant to the low-norm, semantic changes brought by CEs. The results indicate a significant overlap between non-robust and semantic features, countering the common assumption that non-robust features are not interpretable.
4/17/2024
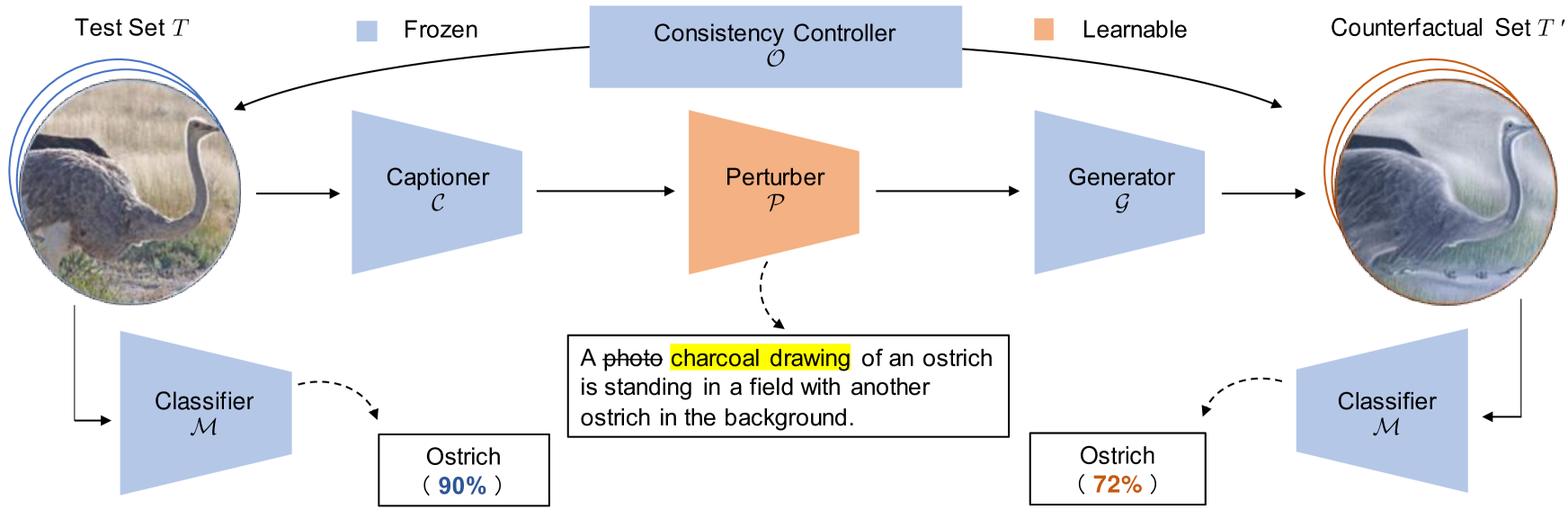
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
0
0
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
6/21/2024
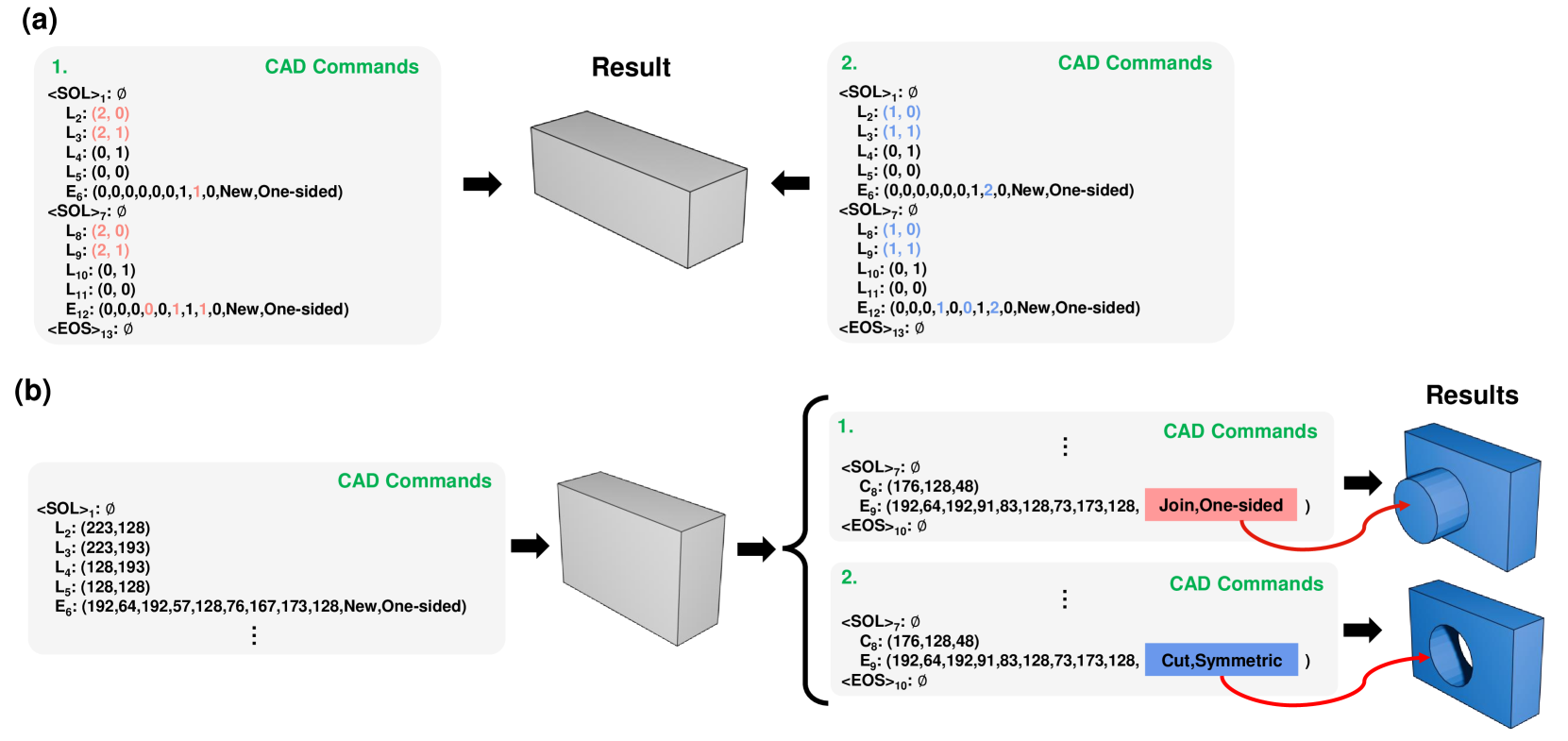
ContrastCAD: Contrastive Learning-based Representation Learning for Computer-Aided Design Models
Minseop Jung, Minseong Kim, Jibum Kim
0
0
The success of Transformer-based models has encouraged many researchers to learn CAD models using sequence-based approaches. However, learning CAD models is still a challenge, because they can be represented as complex shapes with long construction sequences. Furthermore, the same CAD model can be expressed using different CAD construction sequences. We propose a novel contrastive learning-based approach, named ContrastCAD, that effectively captures semantic information within the construction sequences of the CAD model. ContrastCAD generates augmented views using dropout techniques without altering the shape of the CAD model. We also propose a new CAD data augmentation method, called a Random Replace and Extrude (RRE) method, to enhance the learning performance of the model when training an imbalanced training CAD dataset. Experimental results show that the proposed RRE augmentation method significantly enhances the learning performance of Transformer-based autoencoders, even for complex CAD models having very long construction sequences. The proposed ContrastCAD model is shown to be robust to permutation changes of construction sequences and performs better representation learning by generating representation spaces where similar CAD models are more closely clustered. Our codes are available at https://github.com/cm8908/ContrastCAD.
4/3/2024

Utilizing Adversarial Examples for Bias Mitigation and Accuracy Enhancement
Pushkar Shukla, Dhruv Srikanth, Lee Cohen, Matthew Turk
0
0
We propose a novel approach to mitigate biases in computer vision models by utilizing counterfactual generation and fine-tuning. While counterfactuals have been used to analyze and address biases in DNN models, the counterfactuals themselves are often generated from biased generative models, which can introduce additional biases or spurious correlations. To address this issue, we propose using adversarial images, that is images that deceive a deep neural network but not humans, as counterfactuals for fair model training. Our approach leverages a curriculum learning framework combined with a fine-grained adversarial loss to fine-tune the model using adversarial examples. By incorporating adversarial images into the training data, we aim to prevent biases from propagating through the pipeline. We validate our approach through both qualitative and quantitative assessments, demonstrating improved bias mitigation and accuracy compared to existing methods. Qualitatively, our results indicate that post-training, the decisions made by the model are less dependent on the sensitive attribute and our model better disentangles the relationship between sensitive attributes and classification variables.
4/19/2024