Utilizing Adversarial Examples for Bias Mitigation and Accuracy Enhancement
2404.11819
0
0

Abstract
We propose a novel approach to mitigate biases in computer vision models by utilizing counterfactual generation and fine-tuning. While counterfactuals have been used to analyze and address biases in DNN models, the counterfactuals themselves are often generated from biased generative models, which can introduce additional biases or spurious correlations. To address this issue, we propose using adversarial images, that is images that deceive a deep neural network but not humans, as counterfactuals for fair model training. Our approach leverages a curriculum learning framework combined with a fine-grained adversarial loss to fine-tune the model using adversarial examples. By incorporating adversarial images into the training data, we aim to prevent biases from propagating through the pipeline. We validate our approach through both qualitative and quantitative assessments, demonstrating improved bias mitigation and accuracy compared to existing methods. Qualitatively, our results indicate that post-training, the decisions made by the model are less dependent on the sensitive attribute and our model better disentangles the relationship between sensitive attributes and classification variables.
Create account to get full access
Overview
- This paper explores the use of adversarial examples to mitigate bias and enhance the accuracy of machine learning models.
- The authors propose a novel approach that leverages adversarial examples to identify and remove biases in the model, while also improving its overall performance.
- The research includes experiments on various datasets and model architectures, demonstrating the effectiveness of their proposed method.
Plain English Explanation
Bias is a common issue in machine learning models, where the model may make unfair or inaccurate predictions due to biases in the training data or the model itself. The authors of this paper have found a way to use adversarial examples, which are intentionally designed to confuse or fool the model, to actually help address this problem.
The key idea is that by exposing the model to these adversarial examples during training, the model can learn to become more robust and less biased. The model is essentially "challenged" to make accurate predictions even in the face of these adversarial examples, which forces it to learn more nuanced and unbiased patterns in the data.
In addition to reducing bias, the authors also show that this approach can actually improve the overall accuracy of the model. By training the model to handle these adversarial examples, it becomes better equipped to handle a wider range of input data, leading to better performance on standard test sets.
The authors demonstrate the effectiveness of their approach through experiments on various datasets and model architectures, providing empirical evidence for the benefits of their method. This research could have important implications for building more fair and accurate machine learning systems, which is crucial as these models are increasingly used in high-stakes applications.
Technical Explanation
The paper introduces a novel approach that leverages adversarial examples to mitigate bias and enhance the accuracy of machine learning models. Adversarial examples are carefully crafted inputs that are designed to confuse or "fool" the model, causing it to make incorrect predictions.
The authors propose a training procedure that exposes the model to these adversarial examples during the learning process. By challenging the model to make accurate predictions even in the face of these adversarial perturbations, the model is forced to learn more robust and unbiased representations of the data.
The authors conduct experiments on various datasets and model architectures, including face forgery detection, intersectional social biases, and malware detection. The results demonstrate that their proposed approach is effective in mitigating bias and improving the overall accuracy of the models, outperforming traditional training methods.
Critical Analysis
The paper presents a compelling approach to addressing the important problem of bias in machine learning models. The use of adversarial examples as a mechanism for bias mitigation is a novel and promising idea, and the authors provide strong empirical evidence to support its effectiveness.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the proposed method may not be as effective in scenarios where the biases are deeply ingrained in the data or the model architecture. Additionally, the computational cost of generating and training with adversarial examples may be a practical concern for some applications.
Another potential issue is the generalization of the approach to more diverse and complex datasets and tasks. The experiments in the paper focus on relatively well-studied domains, and it would be valuable to see how the method performs on a broader range of applications, including those with more complex, intersectional biases.
Overall, the research presented in this paper is a significant contribution to the field of responsible AI and bias mitigation. The authors have demonstrated a novel and effective approach that holds promise for improving the fairness and accuracy of machine learning models. Further research and real-world deployment of these techniques will be crucial for making progress in this important area.
Conclusion
This paper presents a novel approach that leverages adversarial examples to mitigate bias and enhance the accuracy of machine learning models. The key insight is that by exposing the model to carefully crafted adversarial inputs during training, the model can learn to make more robust and unbiased predictions.
The authors provide empirical evidence of the effectiveness of their method through experiments on various datasets and model architectures, demonstrating improvements in both bias mitigation and overall model performance. This research has important implications for the development of more fair and accurate machine learning systems, which are crucial as these models are increasingly deployed in high-stakes applications.
While the paper acknowledges some limitations and areas for further research, the proposed approach represents a significant contribution to the field of responsible AI. As machine learning continues to shape critical decisions and policies, techniques like this will be essential for ensuring that these systems are equitable, reliable, and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
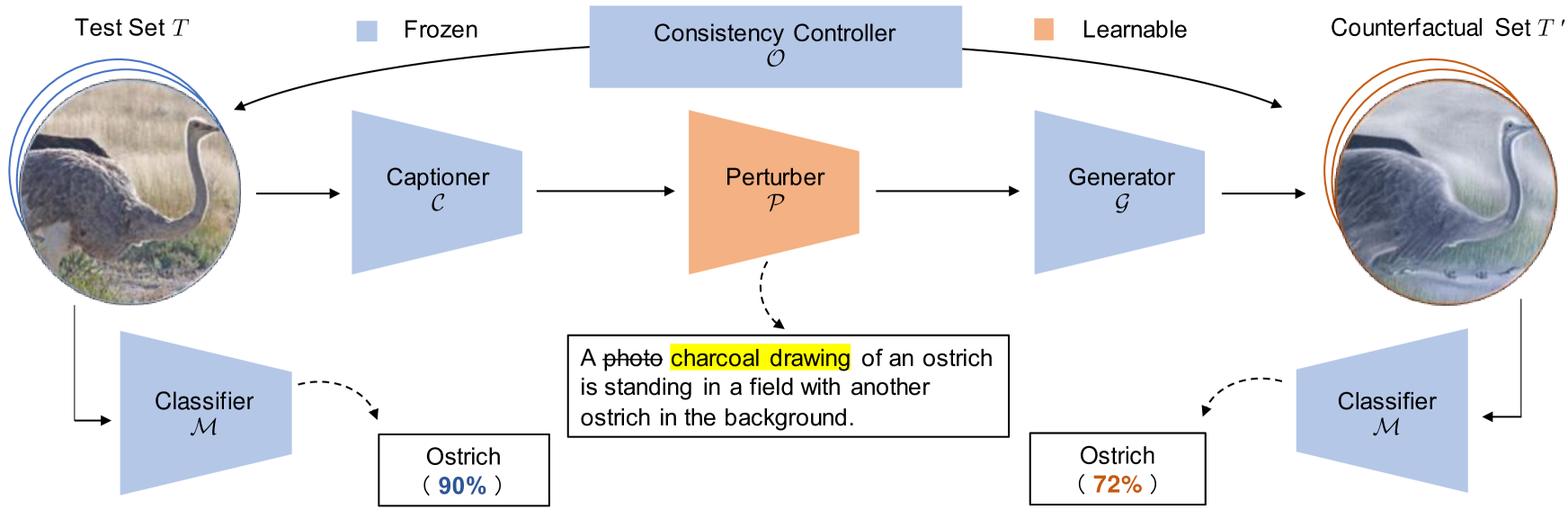
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
0
0
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
6/21/2024

Do Counterfactual Examples Complicate Adversarial Training?
Eric Yeats, Cameron Darwin, Eduardo Ortega, Frank Liu, Hai Li
0
0
We leverage diffusion models to study the robustness-performance tradeoff of robust classifiers. Our approach introduces a simple, pretrained diffusion method to generate low-norm counterfactual examples (CEs): semantically altered data which results in different true class membership. We report that the confidence and accuracy of robust models on their clean training data are associated with the proximity of the data to their CEs. Moreover, robust models perform very poorly when evaluated on the CEs directly, as they become increasingly invariant to the low-norm, semantic changes brought by CEs. The results indicate a significant overlap between non-robust and semantic features, countering the common assumption that non-robust features are not interpretable.
4/17/2024

Boosting Model Resilience via Implicit Adversarial Data Augmentation
Xiaoling Zhou, Wei Ye, Zhemg Lee, Rui Xie, Shikun Zhang
0
0
Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.
6/4/2024
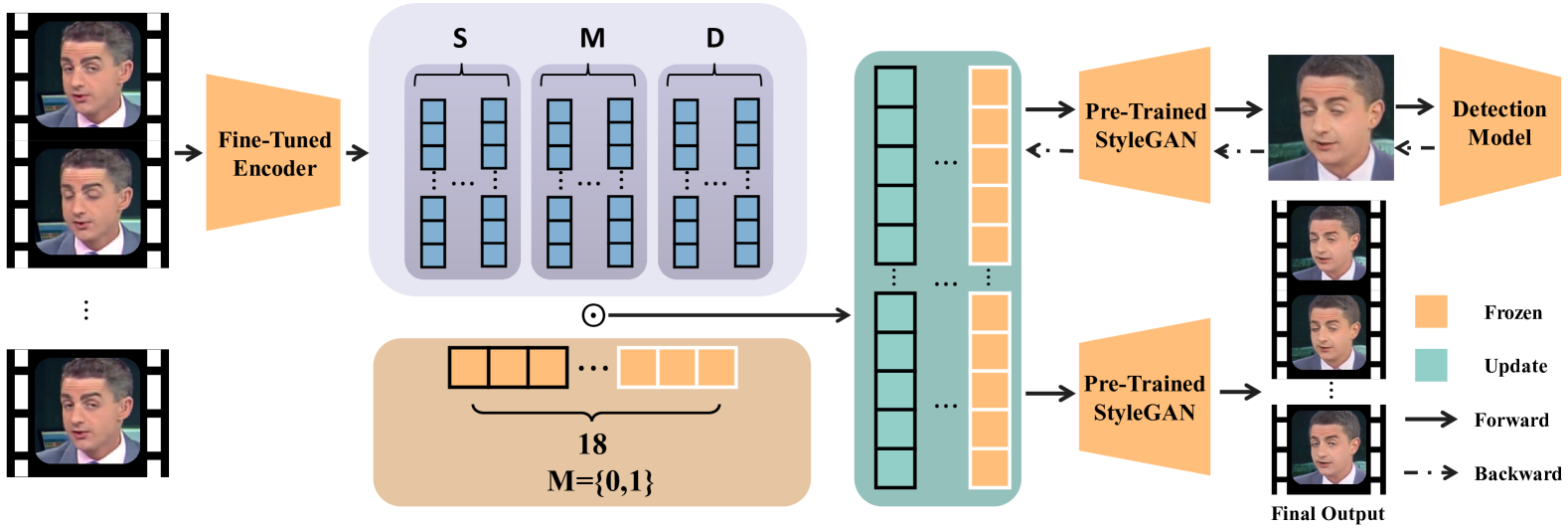
Counterfactual Explanations for Face Forgery Detection via Adversarial Removal of Artifacts
Yang Li, Songlin Yang, Wei Wang, Ziwen He, Bo Peng, Jing Dong
0
0
Highly realistic AI generated face forgeries known as deepfakes have raised serious social concerns. Although DNN-based face forgery detection models have achieved good performance, they are vulnerable to latest generative methods that have less forgery traces and adversarial attacks. This limitation of generalization and robustness hinders the credibility of detection results and requires more explanations. In this work, we provide counterfactual explanations for face forgery detection from an artifact removal perspective. Specifically, we first invert the forgery images into the StyleGAN latent space, and then adversarially optimize their latent representations with the discrimination supervision from the target detection model. We verify the effectiveness of the proposed explanations from two aspects: (1) Counterfactual Trace Visualization: the enhanced forgery images are useful to reveal artifacts by visually contrasting the original images and two different visualization methods; (2) Transferable Adversarial Attacks: the adversarial forgery images generated by attacking the detection model are able to mislead other detection models, implying the removed artifacts are general. Extensive experiments demonstrate that our method achieves over 90% attack success rate and superior attack transferability. Compared with naive adversarial noise methods, our method adopts both generative and discriminative model priors, and optimize the latent representations in a synthesis-by-analysis way, which forces the search of counterfactual explanations on the natural face manifold. Thus, more general counterfactual traces can be found and better adversarial attack transferability can be achieved.
4/15/2024