PANDA: Expanded Width-Aware Message Passing Beyond Rewiring

0

Sign in to get full access
Overview
- The paper introduces PANDA, a new message passing technique for graph neural networks (GNNs) that aims to address the over-squashing problem.
- Over-squashing is a common issue in GNNs where information from distant nodes gets compressed, leading to degraded performance.
- PANDA expands the message passing width beyond just the direct neighbors, allowing for more effective information propagation.
- The approach is demonstrated to outperform existing GNN methods on a range of benchmark tasks.
Plain English Explanation
PANDA is a new way of doing "message passing" in graph neural networks (GNNs). Message passing is how GNNs share information between the nodes in a graph.
The key issue PANDA aims to solve is "over-squashing." This happens when information from distant nodes in the graph gets compressed or "squished" together, making it hard for the GNN to distinguish between different parts of the graph. Over-squashing can hurt the performance of GNNs on tasks like node classification or link prediction.
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring addresses over-squashing by expanding the message passing "width" - instead of just considering direct neighbors, it looks at nodes that are further away. This allows more information to flow through the network.
The paper shows that PANDA outperforms other GNN message passing methods on various benchmark tasks. By expanding the message passing scope, PANDA is able to better capture the structure and relationships in the graph data.
Technical Explanation
The core innovation in PANDA is a new message passing mechanism that goes beyond just considering a node's direct neighbors. Traditional GNN models like Graph Convolutional Networks (GCNs) only propagate information one hop away, leading to over-squashing.
PANDA extends the message passing "width" by allowing a node to aggregate information from nodes that are multiple hops away. This is achieved through a novel attention mechanism that dynamically computes the relevance of distant nodes during message passing.
The authors demonstrate that this expanded message passing approach, combined with other architectural choices, allows PANDA to better preserve important structural information in the graph. This in turn leads to improved performance on tasks like node classification, link prediction, and graph classification.
PANDA is also compared to recent GNN rewiring methods like Probabilistic Graph Rewiring via Virtual Nodes and Temporal Graph Rewiring with Expander Graphs. The results show that PANDA's expanded message passing outperforms these rewiring techniques, which focus more on modifying the graph structure.
Critical Analysis
The key strength of PANDA is its ability to effectively propagate information across long-range dependencies in the graph, going beyond just direct neighbors. This helps mitigate the over-squashing issue that plagues many GNN models.
However, the increased message passing width also comes with additional computational cost. The authors do not provide a detailed analysis of the time and space complexity of PANDA compared to simpler GNN architectures. This is an important consideration, especially for large-scale graph datasets.
Additionally, the paper does not explore the interpretability of the PANDA model. Understanding which distant nodes contribute most to the message passing process could provide useful insights, but this aspect is not investigated.
Finally, the authors only evaluate PANDA on static graph benchmarks. Extending the approach to handle dynamic, evolving graphs could further demonstrate its versatility and practical applicability.
Conclusion
The PANDA model introduces an effective message passing technique for graph neural networks that goes beyond just considering direct neighbors. By expanding the message passing width, PANDA is able to better preserve structural information in the graph and achieve improved performance on a range of tasks.
While the increased computational cost is a potential drawback, the core ideas behind PANDA represent an important step forward in addressing the over-squashing problem in GNNs. Further research into the interpretability and dynamic graph capabilities of PANDA could unlock additional insights and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring
Jeongwhan Choi, Sumin Park, Hyowon Wi, Sung-Bae Cho, Noseong Park
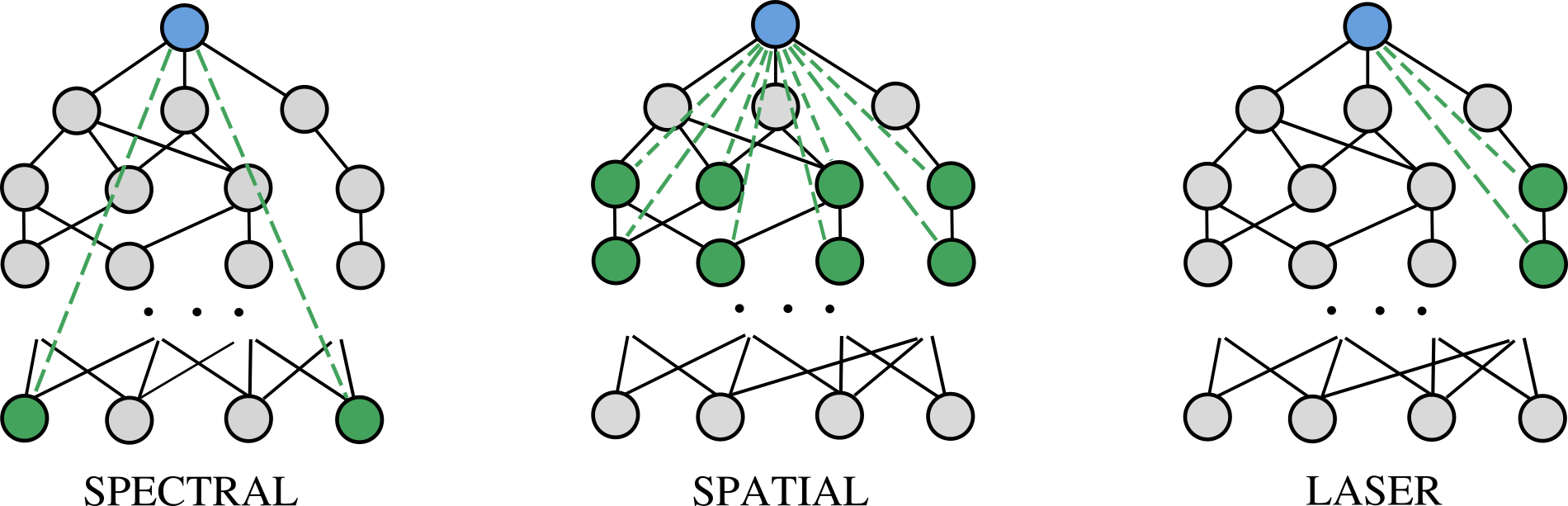
Recent research in the field of graph neural network (GNN) has identified a critical issue known as over-squashing, resulting from the bottleneck phenomenon in graph structures, which impedes the propagation of long-range information. Prior works have proposed a variety of graph rewiring concepts that aim at optimizing the spatial or spectral properties of graphs to promote the signal propagation. However, such approaches inevitably deteriorate the original graph topology, which may lead to a distortion of information flow. To address this, we introduce an expanded width-aware (PANDA) message passing, a new message passing paradigm where nodes with high centrality, a potential source of over-squashing, are selectively expanded in width to encapsulate the growing influx of signals from distant nodes. Experimental results show that our method outperforms existing rewiring methods, suggesting that selectively expanding the hidden state of nodes can be a compelling alternative to graph rewiring for addressing the over-squashing.
Read more7/23/2024
0
Locality-Aware Graph-Rewiring in GNNs
Federico Barbero, Ameya Velingker, Amin Saberi, Michael Bronstein, Francesco Di Giovanni
Graph Neural Networks (GNNs) are popular models for machine learning on graphs that typically follow the message-passing paradigm, whereby the feature of a node is updated recursively upon aggregating information over its neighbors. While exchanging messages over the input graph endows GNNs with a strong inductive bias, it can also make GNNs susceptible to over-squashing, thereby preventing them from capturing long-range interactions in the given graph. To rectify this issue, graph rewiring techniques have been proposed as a means of improving information flow by altering the graph connectivity. In this work, we identify three desiderata for graph-rewiring: (i) reduce over-squashing, (ii) respect the locality of the graph, and (iii) preserve the sparsity of the graph. We highlight fundamental trade-offs that occur between spatial and spectral rewiring techniques; while the former often satisfy (i) and (ii) but not (iii), the latter generally satisfy (i) and (iii) at the expense of (ii). We propose a novel rewiring framework that satisfies all of (i)--(iii) through a locality-aware sequence of rewiring operations. We then discuss a specific instance of such rewiring framework and validate its effectiveness on several real-world benchmarks, showing that it either matches or significantly outperforms existing rewiring approaches.
Read more5/7/2024

0
Probabilistic Graph Rewiring via Virtual Nodes
Chendi Qian, Andrei Manolache, Christopher Morris, Mathias Niepert
Message-passing graph neural networks (MPNNs) have emerged as a powerful paradigm for graph-based machine learning. Despite their effectiveness, MPNNs face challenges such as under-reaching and over-squashing, where limited receptive fields and structural bottlenecks hinder information flow in the graph. While graph transformers hold promise in addressing these issues, their scalability is limited due to quadratic complexity regarding the number of nodes, rendering them impractical for larger graphs. Here, we propose implicitly rewired message-passing neural networks (IPR-MPNNs), a novel approach that integrates implicit probabilistic graph rewiring into MPNNs. By introducing a small number of virtual nodes, i.e., adding additional nodes to a given graph and connecting them to existing nodes, in a differentiable, end-to-end manner, IPR-MPNNs enable long-distance message propagation, circumventing quadratic complexity. Theoretically, we demonstrate that IPR-MPNNs surpass the expressiveness of traditional MPNNs. Empirically, we validate our approach by showcasing its ability to mitigate under-reaching and over-squashing effects, achieving state-of-the-art performance across multiple graph datasets. Notably, IPR-MPNNs outperform graph transformers while maintaining significantly faster computational efficiency.
Read more6/10/2024

0
The Effectiveness of Curvature-Based Rewiring and the Role of Hyperparameters in GNNs Revisited
Floriano Tori, Vincent Holst, Vincent Ginis
Message passing is the dominant paradigm in Graph Neural Networks (GNNs). The efficiency of message passing, however, can be limited by the topology of the graph. This happens when information is lost during propagation due to being oversquashed when travelling through bottlenecks. To remedy this, recent efforts have focused on graph rewiring techniques, which disconnect the input graph originating from the data and the computational graph, on which message passing is performed. A prominent approach for this is to use discrete graph curvature measures, of which several variants have been proposed, to identify and rewire around bottlenecks, facilitating information propagation. While oversquashing has been demonstrated in synthetic datasets, in this work we reevaluate the performance gains that curvature-based rewiring brings to real-world datasets. We show that in these datasets, edges selected during the rewiring process are not in line with theoretical criteria identifying bottlenecks. This implies they do not necessarily oversquash information during message passing. Subsequently, we demonstrate that SOTA accuracies on these datasets are outliers originating from sweeps of hyperparameters -- both the ones for training and dedicated ones related to the rewiring algorithm -- instead of consistent performance gains. In conclusion, our analysis nuances the effectiveness of curvature-based rewiring in real-world datasets and brings a new perspective on the methods to evaluate GNN accuracy improvements.
Read more7/15/2024