Pandora: Towards General World Model with Natural Language Actions and Video States
2406.09455
0
0

Abstract
World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
Create account to get full access
Overview
• This paper proposes a new system called "\scalerel*X" that aims to create a general world model capable of understanding and interacting with the physical world through natural language actions and video states.
• The key innovation is the use of a language model to control a virtual environment and generate video outputs, allowing for complex interactions and task-solving in a simulated world.
• The system is designed to serve as a stepping stone towards more advanced AI systems that can reason about the world and plan actions based on language and visual inputs.
Plain English Explanation
The researchers have developed a system called "\scalerel*X" that tries to create a comprehensive model of the world. This model can understand and interact with the physical world using natural language (words and sentences) and video inputs.
The core idea is to use a powerful language model - a type of AI system trained on a huge amount of text data - to control a virtual environment and generate video outputs. This allows the system to simulate complex real-world scenarios and tasks, and try to solve them by reasoning about the situation based on the language and visual information.
For example, the system could be given a natural language instruction like "Pick up the red ball and place it on the table." It would then use its understanding of language to figure out the steps needed to complete this task, control a virtual environment to carry out those steps, and generate video outputs showing the process.
The researchers see this as an important step towards building more advanced AI systems that can truly understand the world around them, plan actions, and solve problems, all while communicating using normal human language. By grounding language in a simulated physical environment, the system can develop a deeper, more practical understanding of the world.
Technical Explanation
The \scalerel*X system consists of several key components:
-
Language Model: The core of the system is a large language model, trained on a vast amount of text data, that can understand and generate human-like language. This allows the system to interpret natural language instructions and queries.
-
Virtual Environment: \scalerel*X also includes a simulated 3D environment that can be controlled and updated based on the language model's outputs. This virtual world allows the system to plan and execute actions in response to language inputs.
-
Video Generation: Crucially, the system can also generate video outputs that depict the state of the virtual environment and the actions being taken. This allows the language model to have a visual understanding of the world that it can reason about.
The researchers train the entire \scalerel*X system end-to-end, allowing the language model, virtual environment, and video generation to all learn to work together seamlessly. This enables the system to understand natural language, plan and execute actions in the virtual world, and generate corresponding video outputs - all as a unified, intelligent agent.
Critical Analysis
The \scalerel*X system represents an ambitious step towards building more general and capable AI models that can interact with the world through language and vision. By grounding language understanding in a simulated physical environment, the researchers are trying to push the boundaries of what language models are capable of.
However, the paper acknowledges several important limitations and areas for future work. For example, the current virtual environment is still relatively simple and does not capture the full complexity of the real world. Scaling up to more realistic and open-ended environments will be a significant challenge.
Additionally, the system's language understanding and reasoning capabilities, while impressive, are still far from human-level. Bridging that gap and developing more flexible, robust, and common-sense reasoning abilities will require further breakthroughs in language model architectures and training techniques.
The researchers also note that evaluating the true "world model" capabilities of the system is difficult, as there is no clear benchmark or standard for measuring such a broad and ambitious goal. Developing appropriate evaluation frameworks will be crucial for tracking progress in this area.
Overall, the \scalerel*X system represents an important step forward, but there is still a long way to go before we can build AI agents that can truly understand and interact with the world in the way humans do. Continued research and innovation in this direction will be essential for advancing the field of artificial intelligence.
Conclusion
The \scalerel*X system proposed in this paper is an ambitious attempt to create a general world model that can understand and interact with the physical world using natural language and video inputs. By combining a powerful language model with a simulated virtual environment and video generation capabilities, the researchers are working towards AI systems that can reason about the world in a more grounded and practical way.
While the current system has significant limitations, this research represents an important step forward in the quest to build AI agents that can truly comprehend and engage with the complexities of the real world. As language models and other AI technologies continue to advance, the ideas and approaches explored in this paper may pave the way for even more capable and versatile AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
WorldGPT: Empowering LLM as Multimodal World Model
Zhiqi Ge, Hongzhe Huang, Mingze Zhou, Juncheng Li, Guoming Wang, Siliang Tang, Yueting Zhuang
0
0
World models are progressively being employed across diverse fields, extending from basic environment simulation to complex scenario construction. However, existing models are mainly trained on domain-specific states and actions, and confined to single-modality state representations. In this paper, We introduce WorldGPT, a generalist world model built upon Multimodal Large Language Model (MLLM). WorldGPT acquires an understanding of world dynamics through analyzing millions of videos across various domains. To further enhance WorldGPT's capability in specialized scenarios and long-term tasks, we have integrated it with a novel cognitive architecture that combines memory offloading, knowledge retrieval, and context reflection. As for evaluation, we build WorldNet, a multimodal state transition prediction benchmark encompassing varied real-life scenarios. Conducting evaluations on WorldNet directly demonstrates WorldGPT's capability to accurately model state transition patterns, affirming its effectiveness in understanding and predicting the dynamics of complex scenarios. We further explore WorldGPT's emerging potential in serving as a world simulator, helping multimodal agents generalize to unfamiliar domains through efficiently synthesising multimodal instruction instances which are proved to be as reliable as authentic data for fine-tuning purposes. The project is available on url{https://github.com/DCDmllm/WorldGPT}.
4/30/2024
🤷
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
0
0
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
5/7/2024
📈
Agent Planning with World Knowledge Model
Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
0
0
Recent endeavors towards directly using large language models (LLMs) as agent models to execute interactive planning tasks have shown commendable results. Despite their achievements, however, they still struggle with brainless trial-and-error in global planning and generating hallucinatory actions in local planning due to their poor understanding of the ''real'' physical world. Imitating humans' mental world knowledge model which provides global prior knowledge before the task and maintains local dynamic knowledge during the task, in this paper, we introduce parametric World Knowledge Model (WKM) to facilitate agent planning. Concretely, we steer the agent model to self-synthesize knowledge from both expert and sampled trajectories. Then we develop WKM, providing prior task knowledge to guide the global planning and dynamic state knowledge to assist the local planning. Experimental results on three complex real-world simulated datasets with three state-of-the-art open-source LLMs, Mistral-7B, Gemma-7B, and Llama-3-8B, demonstrate that our method can achieve superior performance compared to various strong baselines. Besides, we analyze to illustrate that our WKM can effectively alleviate the blind trial-and-error and hallucinatory action issues, providing strong support for the agent's understanding of the world. Other interesting findings include: 1) our instance-level task knowledge can generalize better to unseen tasks, 2) weak WKM can guide strong agent model planning, and 3) unified WKM training has promising potential for further development. Code will be available at https://github.com/zjunlp/WKM.
5/24/2024
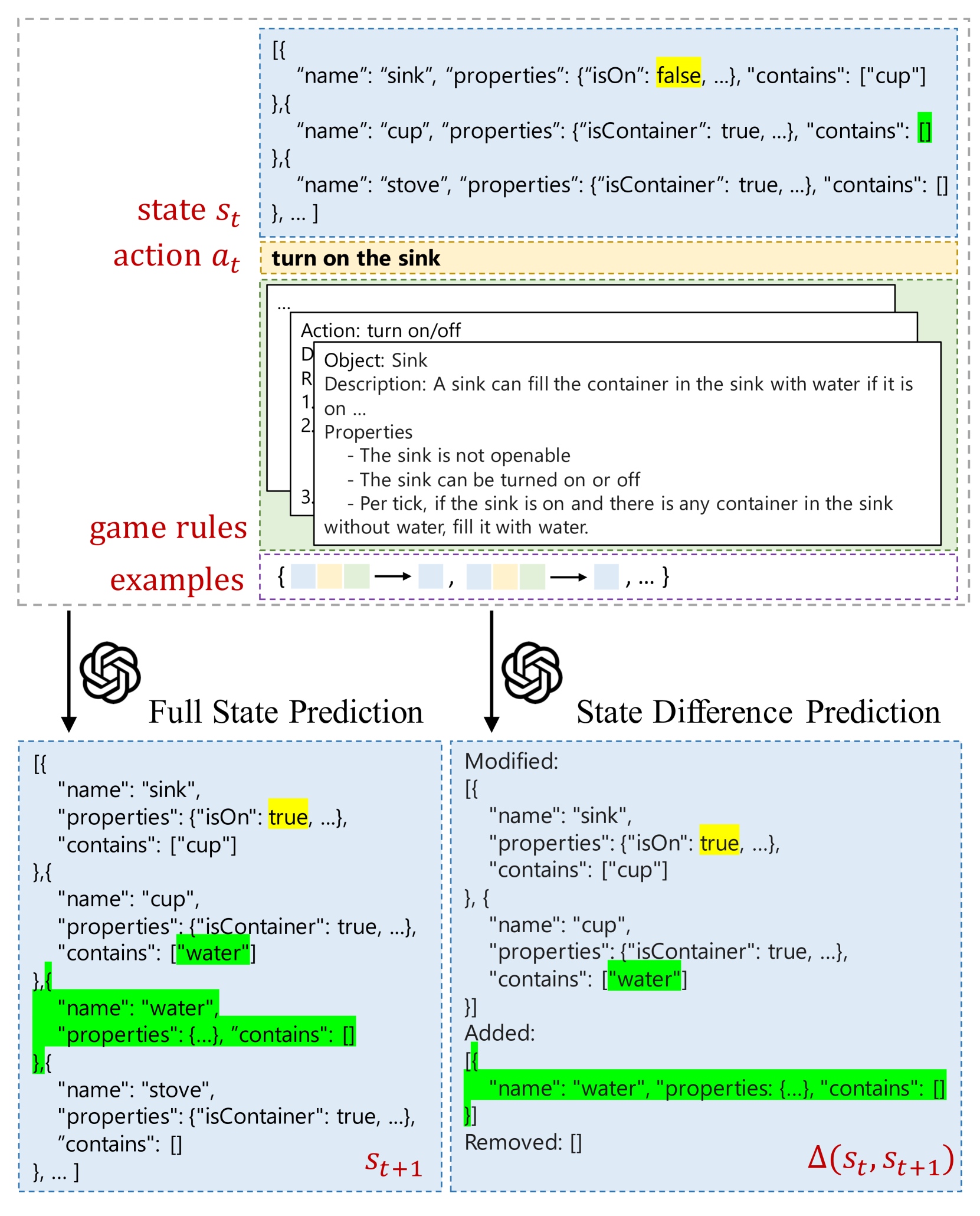
Can Language Models Serve as Text-Based World Simulators?
Ruoyao Wang, Graham Todd, Ziang Xiao, Xingdi Yuan, Marc-Alexandre C^ot'e, Peter Clark, Peter Jansen
0
0
Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
6/11/2024