Can Language Models Serve as Text-Based World Simulators?

64
Sign in to get full access
Overview
- This paper explores the potential of large language models (LLMs) to serve as text-based world simulators, capable of generating coherent and detailed textual descriptions of imaginary worlds.
- The researchers investigate the ability of LLMs to create and maintain consistent, multi-faceted simulations that can be interactively explored through text-based interactions.
- The paper builds on recent advancements in human simulacra benchmarking and language model-guided simulation-to-real techniques.
Plain English Explanation
Large language models, which are artificial intelligence systems trained on vast amounts of text data, have demonstrated remarkable abilities in tasks like generating coherent and natural-sounding text. This paper explores whether these models can be used to create and maintain detailed simulations of imaginary worlds that can be explored through text-based interactions.
The researchers are investigating the possibility of using LLMs as "text-based world simulators" - systems that can generate rich and consistent descriptions of fictional worlds, and allow users to interact with and explore these worlds by typing commands and receiving textual responses. This builds on recent work in areas like human simulacra benchmarking, which explores how well LLMs can mimic the personalities and behaviors of real people, and language model-guided simulation-to-real techniques, which use language models to bridge the gap between simulated and real-world environments.
The ultimate goal is to develop LLMs that can create and maintain complex, multi-faceted simulated worlds that users can immerse themselves in through text-based interactions, much like in classic text-based adventure games. This could have applications in areas like entertainment, education, and even psychological research.
Technical Explanation
The paper begins by reviewing the relevant literature on using LLMs for tasks like world model building, character personification, and simulation-to-real bridging. The researchers note that while these techniques have shown promise, there has been limited work on using LLMs to create and maintain coherent, interactive text-based simulations of imaginary worlds.
To address this, the paper outlines a methodology for training LLMs to serve as world simulators. This involves fine-tuning the models on large datasets of text-based adventure games, interactive fiction, and other sources of world-building narratives. The goal is to imbue the models with the necessary knowledge and capabilities to generate consistent, multi-faceted textual descriptions of fictional worlds, and to respond appropriately to user inputs and commands.
The researchers also discuss the use of prompt engineering, world model representations, and other techniques to enhance the models' world-building and interactive capabilities. They propose evaluation frameworks to assess the models' ability to maintain coherence, respond to user inputs, and generally create a sense of immersion and engagement for the user.
Critical Analysis
The paper raises some important caveats and limitations to the proposed approach. For example, the researchers acknowledge that maintaining long-term coherence and consistency in simulated worlds is a significant challenge, and that current LLMs may struggle with tasks like logical reasoning, causal understanding, and long-term memory.
Additionally, the paper notes that the quality and richness of the text-based simulations will be heavily dependent on the quality and breadth of the training data used to fine-tune the LLMs. Ensuring sufficient coverage of diverse world-building narratives and interactive fiction may be a significant hurdle.
The researchers also highlight the potential for biases, inconsistencies, and other undesirable behaviors to emerge in the simulated worlds, and the need for robust safety and control mechanisms to mitigate these risks.
Overall, the paper provides a compelling vision for the use of LLMs as text-based world simulators, but also acknowledges the substantial technical challenges that must be overcome to realize this vision. Continued research and innovation in areas like linguistic intentionality, world modeling, and interactive narrative generation will be crucial.
Conclusion
This paper explores the potential of large language models to serve as text-based world simulators, capable of generating coherent and detailed descriptions of imaginary worlds that can be interactively explored through text-based interactions. The researchers outline a methodology for training LLMs to create and maintain these simulated worlds, building on recent advancements in related areas.
While the proposed approach holds significant promise, the paper also highlights the substantial technical challenges that must be addressed, such as maintaining long-term coherence, addressing safety and bias concerns, and ensuring the richness and immersiveness of the simulated experiences. Continued research and innovation will be essential to realizing the full potential of LLMs as text-based world simulators.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
64
Can Language Models Serve as Text-Based World Simulators?
Ruoyao Wang, Graham Todd, Ziang Xiao, Xingdi Yuan, Marc-Alexandre C^ot'e, Peter Clark, Peter Jansen
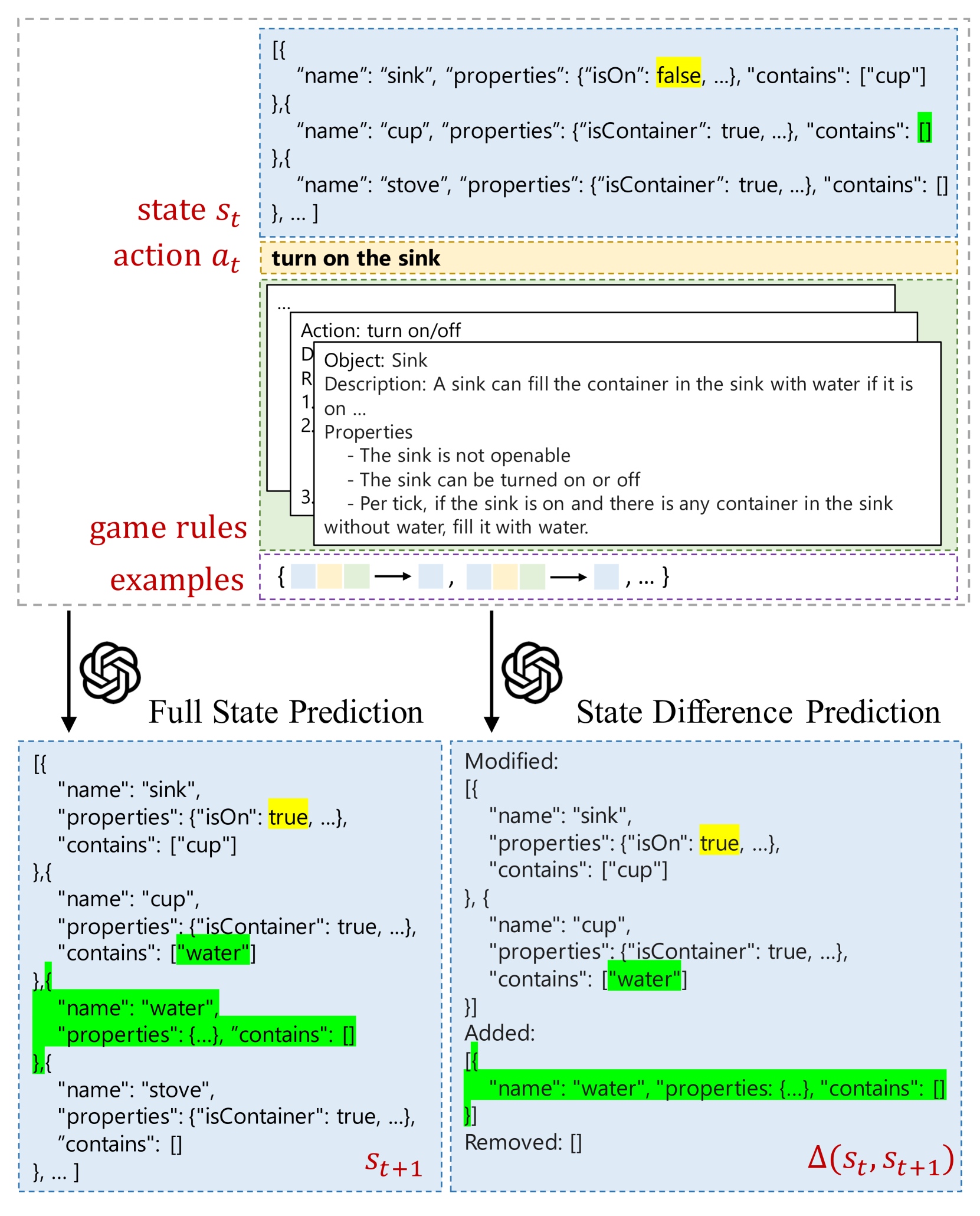
Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
Read more6/11/2024

0
Language-Guided World Models: A Model-Based Approach to AI Control
Alex Zhang, Khanh Nguyen, Jens Tuyls, Albert Lin, Karthik Narasimhan
This paper introduces the concept of Language-Guided World Models (LWMs) -- probabilistic models that can simulate environments by reading texts. Agents equipped with these models provide humans with more extensive and efficient control, allowing them to simultaneously alter agent behaviors in multiple tasks via natural verbal communication. In this work, we take initial steps in developing robust LWMs that can generalize to compositionally novel language descriptions. We design a challenging world modeling benchmark based on the game of MESSENGER (Hanjie et al., 2021), featuring evaluation settings that require varying degrees of compositional generalization. Our experiments reveal the lack of generalizability of the state-of-the-art Transformer model, as it offers marginal improvements in simulation quality over a no-text baseline. We devise a more robust model by fusing the Transformer with the EMMA attention mechanism (Hanjie et al., 2021). Our model substantially outperforms the Transformer and approaches the performance of a model with an oracle semantic parsing and grounding capability. To demonstrate the practicality of this model in improving AI safety and transparency, we simulate a scenario in which the model enables an agent to present plans to a human before execution, and to revise plans based on their language feedback.
Read more9/6/2024

0
SimulBench: Evaluating Language Models with Creative Simulation Tasks
Qi Jia, Xiang Yue, Tianyu Zheng, Jie Huang, Bill Yuchen Lin
We introduce SimulBench, a benchmark designed to evaluate large language models (LLMs) across a diverse collection of creative simulation scenarios, such as acting as a Linux terminal or playing text games with users. While these simulation tasks serve as effective measures of an LLM's general intelligence, they are seldom incorporated into existing benchmarks. A major challenge is to develop an evaluation framework for testing different LLMs fairly while preserving the multi-round interactive nature of simulation tasks between users and AI. To tackle this issue, we suggest using a fixed LLM as a user agent to engage with an LLM to collect dialogues first under different tasks. Then, challenging dialogue scripts are extracted for evaluating different target LLMs. To facilitate automatic assessment on DataName{}, GPT-4 is employed as the evaluator, tasked with reviewing the quality of the final response generated by the target LLMs given multi-turn dialogue scripts. Our comprehensive experiments indicate that these simulation tasks continue to pose a significant challenge with their unique natures and show the gap between proprietary models and the most advanced open LLMs. For example, GPT-4-turbo outperforms LLaMA-3-70b-Chat on 18.55% more cases.
Read more9/14/2024

0
CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
Read more6/21/2024