PanoNormal: Monocular Indoor 360{deg} Surface Normal Estimation
2405.18745
0
0
Abstract
The presence of spherical distortion on the Equirectangular image is an acknowledged challenge in dense regression computer vision tasks, such as surface normal estimation. Recent advances in convolutional neural networks (CNNs) strive to mitigate spherical distortion but often fall short in capturing holistic structures effectively, primarily due to their fixed receptive field. On the other hand, vision transformers (ViTs) excel in establishing long-range dependencies through a global self-attention mechanism, yet they encounter limitations in preserving local details. We introduce textit{PanoNormal}, a monocular surface normal estimation architecture designed for 360{deg} images, which combines the strengths of CNNs and ViTs. Specifically, we employ a multi-level global self-attention scheme with the consideration of the spherical feature distribution, enhancing the comprehensive understanding of the scene. Our experimental results demonstrate that our approach achieves state-of-the-art performance across multiple popular 360{deg} monocular datasets. The code and models will be released.
Create account to get full access
Overview
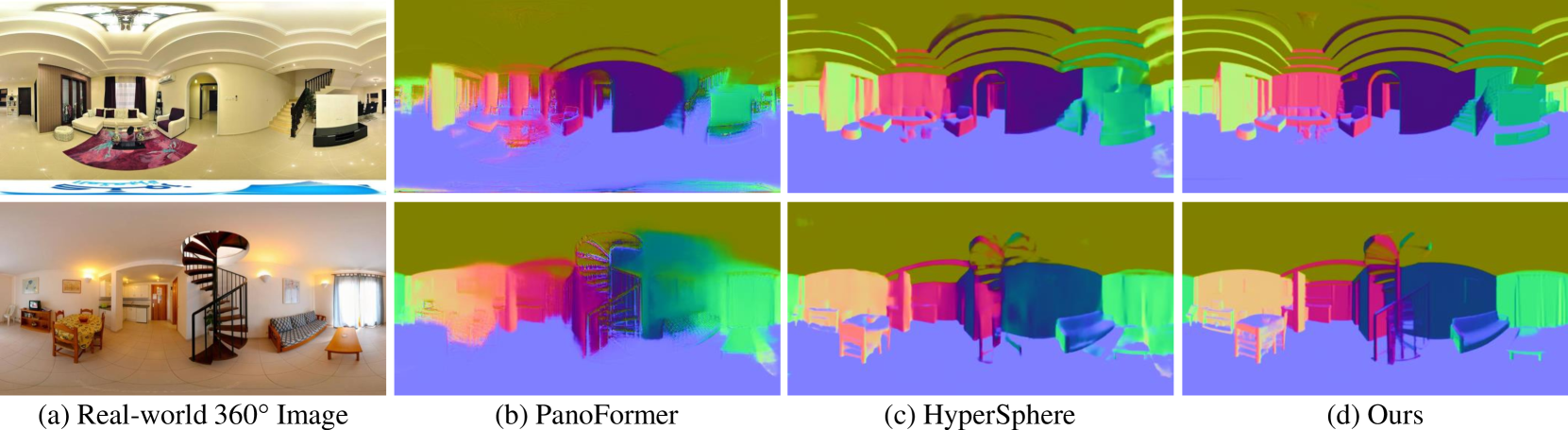
• This paper presents PanoNormal, a method for estimating the surface normals of indoor environments from a single monocular 360° panoramic image.
• The researchers developed a convolutional neural network architecture that can accurately predict the 3D surface normals of a scene from a single panoramic input.
• PanoNormal outperforms previous state-of-the-art methods for monocular 360° surface normal estimation, demonstrating the effectiveness of the proposed approach.
Plain English Explanation
The paper describes a new technique called PanoNormal that can figure out the 3D shape of a room just by looking at a 360-degree panoramic photo. This is useful for applications like virtual reality, robotics, and 3D modeling, where knowing the 3D structure of a space is important.
Previous methods for estimating 3D surface normals (the direction the surface is facing) from a single 2D image have worked reasonably well, but they struggle with panoramic images that capture an entire room or space. PanoNormal uses a clever deep learning architecture to overcome this challenge and accurately predict the 3D surface normals from a single 360-degree panoramic photo.
The key insight is that the network needs to be able to understand the curved, wraparound nature of the panoramic image, rather than just treating it like a regular flat photo. By designing the network in a way that accounts for the panoramic projection, the researchers were able to create a system that outperforms previous approaches on this task.
This advance in 3D understanding from a single image could enable new applications in areas like robotics, virtual reality, and 3D modeling, where having a detailed 3D understanding of a space from just a single panoramic photo could be very useful.
Technical Explanation
The key technical innovation in PanoNormal is the network architecture, which is designed to handle the unique challenges of 360° panoramic images. Typical convolutional neural networks struggle with the distortions and discontinuities introduced by the panoramic projection.
To address this, the PanoNormal network uses a combination of 2D and 3D convolutions, along with a specialized "panoramic attention" module that allows the network to better understand the spatial relationships in the panoramic data. This hybrid 2D-3D architecture outperforms previous methods that relied solely on 2D convolutions.
The network is trained on a large dataset of synthetic panoramic images with ground truth surface normal labels. During training, the network learns to predict a dense per-pixel surface normal map from the input panorama. The researchers also introduce a new loss function that accounts for the spherical nature of the output.
In experiments, PanoNormal demonstrated state-of-the-art performance on several panoramic surface normal estimation benchmarks, significantly outperforming previous monocular 360° methods. This included improved accuracy, robustness to challenges like occlusions, and faster inference times.
Critical Analysis
The paper provides a thorough evaluation of PanoNormal's performance, including comparisons to prior work and an analysis of the network's strengths and weaknesses. However, the authors acknowledge that their method still has some limitations, such as struggling with highly reflective or textureless surfaces.
Additionally, the dataset used for training and evaluation is primarily synthetic, which raises questions about how well the model would generalize to real-world panoramic images. Further testing on diverse real-world datasets would help validate the approach.
It would also be interesting to see how PanoNormal's performance compares to methods that leverage additional sensor modalities, such as depth cameras or inertial measurement units, which could provide complementary information to improve 3D understanding.
Overall, the PanoNormal technique represents an impressive advance in monocular 360° surface normal estimation, with the potential to enable new applications in areas like robotics, virtual reality, and 3D reconstruction. However, as with any research, there is room for continued refinement and exploration of its capabilities and limitations.
Conclusion
The PanoNormal paper presents a novel deep learning-based approach for estimating the 3D surface normals of indoor environments from a single 360° panoramic image. By developing a specialized network architecture that can effectively handle the unique characteristics of panoramic data, the researchers were able to significantly outperform previous state-of-the-art methods on this task.
This advance in 3D understanding from a single panoramic image could have far-reaching implications, enabling new applications in fields like robotics, virtual reality, and 3D modeling. As the technology continues to evolve, we can expect to see even more innovative uses of this type of 3D scene understanding in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Surface Normal Reconstruction Using Polarization-Unet
F. S. Mortazavi, S. Dajkhosh, M. Saadatseresht
0
0
Today, three-dimensional reconstruction of objects has many applications in various fields, and therefore, choosing a suitable method for high resolution three-dimensional reconstruction is an important issue and displaying high-level details in three-dimensional models is a serious challenge in this field. Until now, active methods have been used for high-resolution three-dimensional reconstruction. But the problem of active three-dimensional reconstruction methods is that they require a light source close to the object. Shape from polarization (SfP) is one of the best solutions for high-resolution three-dimensional reconstruction of objects, which is a passive method and does not have the drawbacks of active methods. The changes in polarization of the reflected light from an object can be analyzed by using a polarization camera or locating polarizing filter in front of the digital camera and rotating the filter. Using this information, the surface normal can be reconstructed with high accuracy, which will lead to local reconstruction of the surface details. In this paper, an end-to-end deep learning approach has been presented to produce the surface normal of objects. In this method a benchmark dataset has been used to train the neural network and evaluate the results. The results have been evaluated quantitatively and qualitatively by other methods and under different lighting conditions. The MAE value (Mean-Angular-Error) has been used for results evaluation. The evaluations showed that the proposed method could accurately reconstruct the surface normal of objects with the lowest MAE value which is equal to 18.06 degree on the whole dataset, in comparison to previous physics-based methods which are between 41.44 and 49.03 degree.
6/24/2024
Upright adjustment with graph convolutional networks
Raehyuk Jung, Sungmin Cho, Junseok Kwon
0
0
We present a novel method for the upright adjustment of 360 images. Our network consists of two modules, which are a convolutional neural network (CNN) and a graph convolutional network (GCN). The input 360 images is processed with the CNN for visual feature extraction, and the extracted feature map is converted into a graph that finds a spherical representation of the input. We also introduce a novel loss function to address the issue of discrete probability distributions defined on the surface of a sphere. Experimental results demonstrate that our method outperforms fully connected based methods.
6/4/2024

Estimating Depth of Monocular Panoramic Image with Teacher-Student Model Fusing Equirectangular and Spherical Representations
Jingguo Liu, Yijun Xu, Shigang Li, Jianfeng Li
0
0
Disconnectivity and distortion are the two problems which must be coped with when processing 360 degrees equirectangular images. In this paper, we propose a method of estimating the depth of monocular panoramic image with a teacher-student model fusing equirectangular and spherical representations. In contrast with the existing methods fusing an equirectangular representation with a cube map representation or tangent representation, a spherical representation is a better choice because a sampling on a sphere is more uniform and can also cope with distortion more effectively. In this processing, a novel spherical convolution kernel computing with sampling points on a sphere is developed to extract features from the spherical representation, and then, a Segmentation Feature Fusion(SFF) methodology is utilized to combine the features with ones extracted from the equirectangular representation. In contrast with the existing methods using a teacher-student model to obtain a lighter model of depth estimation, we use a teacher-student model to learn the latent features of depth images. This results in a trained model which estimates the depth map of an equirectangular image using not only the feature maps extracted from an input equirectangular image but also the distilled knowledge learnt from the ground truth of depth map of a training set. In experiments, the proposed method is tested on several well-known 360 monocular depth estimation benchmark datasets, and outperforms the existing methods for the most evaluation indexes.
5/28/2024
🤷
SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
Junsong Zhang, Zisong Chen, Chunyu Lin, Lang Nie, Zhijie Shen, Junda Huang, Yao Zhao
0
0
Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles. Existing methods either adopt a bi-projection fusion strategy to remove distortions or model long-range dependencies to capture global structures, which can result in either unclear structure or insufficient local perception. In this paper, we propose a spherical geometry transformer, named SGFormer, to address the above issues, with an innovative step to integrate spherical geometric priors into vision transformers. To this end, we retarget the transformer decoder to a spherical prior decoder (termed SPDecoder), which endeavors to uphold the integrity of spherical structures during decoding. Concretely, we leverage bipolar re-projection, circular rotation, and curve local embedding to preserve the spherical characteristics of equidistortion, continuity, and surface distance, respectively. Furthermore, we present a query-based global conditional position embedding to compensate for spatial structure at varying resolutions. It not only boosts the global perception of spatial position but also sharpens the depth structure across different patches. Finally, we conduct extensive experiments on popular benchmarks, demonstrating our superiority over state-of-the-art solutions.
4/24/2024