SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
2404.14979
0
0
🤷
Abstract
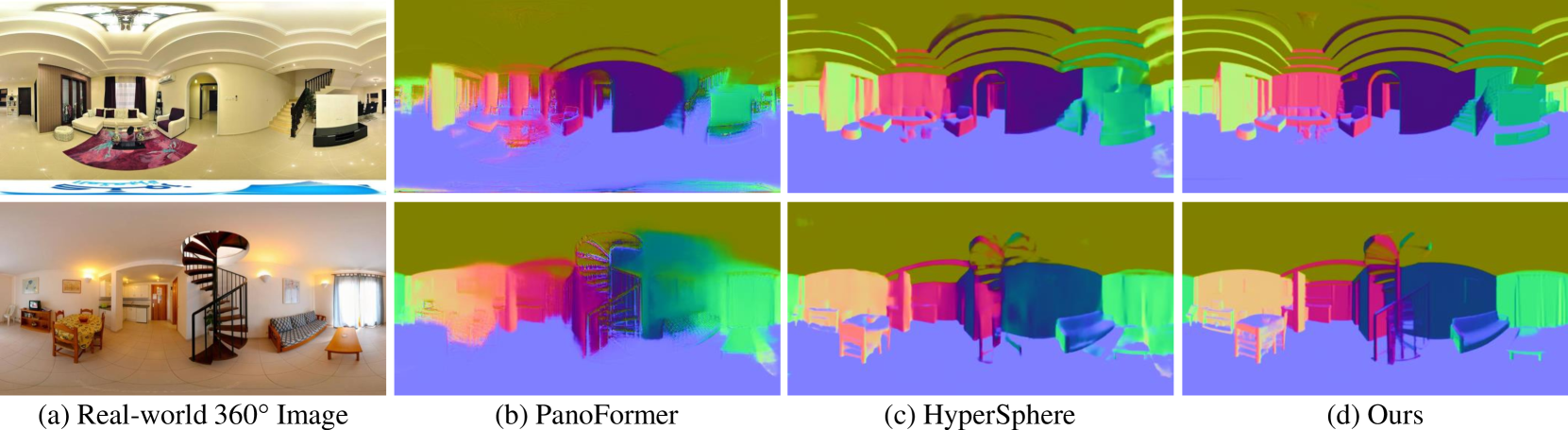
Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles. Existing methods either adopt a bi-projection fusion strategy to remove distortions or model long-range dependencies to capture global structures, which can result in either unclear structure or insufficient local perception. In this paper, we propose a spherical geometry transformer, named SGFormer, to address the above issues, with an innovative step to integrate spherical geometric priors into vision transformers. To this end, we retarget the transformer decoder to a spherical prior decoder (termed SPDecoder), which endeavors to uphold the integrity of spherical structures during decoding. Concretely, we leverage bipolar re-projection, circular rotation, and curve local embedding to preserve the spherical characteristics of equidistortion, continuity, and surface distance, respectively. Furthermore, we present a query-based global conditional position embedding to compensate for spatial structure at varying resolutions. It not only boosts the global perception of spatial position but also sharpens the depth structure across different patches. Finally, we conduct extensive experiments on popular benchmarks, demonstrating our superiority over state-of-the-art solutions.
Create account to get full access
Overview
- Panoramic distortion is a significant challenge in 360-degree depth estimation, particularly at the north and south poles.
- Existing methods either remove distortions through bi-projection fusion or model long-range dependencies to capture global structures, but these approaches can result in unclear structure or insufficient local perception.
- The authors propose a spherical geometry transformer, named SGFormer, to address these issues by integrating spherical geometric priors into vision transformers.
Plain English Explanation
Depth estimation is the process of determining the distance of objects in an image or video from the camera. This is important for applications like virtual reality and 3D object pose estimation.
When working with 360-degree panoramic images, the distortion at the top and bottom of the image (the "poles") can make depth estimation particularly challenging. Existing methods try to address this in different ways:
-
Bi-projection fusion: They convert the 360-degree image into two separate projections, which helps remove the distortion. However, this can result in a loss of clarity in the overall structure of the scene.
-
Modeling long-range dependencies: These methods try to capture the global structure of the scene, which can help with depth estimation. But this approach may not be as effective at capturing the local details that are important for accurate depth perception.
The researchers in this paper propose a new approach called the Spherical Geometry Transformer (SGFormer) that aims to address these issues. They integrate "spherical geometric priors" into a vision transformer model, which helps preserve the integrity of the spherical structure during the depth estimation process.
Technical Explanation
The key innovation in the SGFormer is the Spherical Prior Decoder (SPDecoder), which is designed to uphold the integrity of the spherical structure during the decoding process. Specifically, the SPDecoder leverages three techniques to preserve the spherical characteristics:
- Bipolar re-projection: This helps maintain the equidistortion property of the spherical surface.
- Circular rotation: This preserves the continuity of the spherical structure.
- Curve local embedding: This captures the surface distance relationships on the sphere.
Additionally, the researchers present a query-based global conditional position embedding that compensates for the spatial structure at varying resolutions. This not only boosts the global perception of spatial position but also sharpens the depth structure across different patches of the image.
The authors conduct extensive experiments on popular benchmarks and demonstrate the superiority of their SGFormer approach over state-of-the-art solutions for 360-degree depth estimation.
Critical Analysis
The paper presents a well-designed and technically sound solution to the challenge of panoramic distortion in 360-degree depth estimation. The integration of spherical geometric priors into the vision transformer architecture is a novel and promising approach.
However, the paper does not discuss the potential computational complexity or inference speed of the SGFormer model, which could be an important consideration for real-world applications. Additionally, the authors could have explored the model's performance on a wider range of 360-degree datasets to further validate its generalization capabilities.
It would also be interesting to see how the SGFormer compares to other state-of-the-art methods that leverage geographic location encoding or stereo-guided depth estimation for 360-degree depth estimation.
Conclusion
The SGFormer proposed in this paper is a significant step forward in addressing the challenge of panoramic distortion in 360-degree depth estimation. By integrating spherical geometric priors into a vision transformer architecture, the authors have developed a novel and effective solution that outperforms existing state-of-the-art methods.
The key insights from this research could be leveraged to further improve 360-degree depth estimation and support the development of more advanced 3D scene understanding and virtual/augmented reality applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CRF360D: Monocular 360 Depth Estimation via Spherical Fully-Connected CRFs
Zidong Cao, Lin Wang
0
0
Monocular 360 depth estimation is challenging due to the inherent distortion of the equirectangular projection (ERP). This distortion causes a problem: spherical adjacent points are separated after being projected to the ERP plane, particularly in the polar regions. To tackle this problem, recent methods calculate the spherical neighbors in the tangent domain. However, as the tangent patch and sphere only have one common point, these methods construct neighboring spherical relationships around the common point. In this paper, we propose spherical fully-connected CRFs (SF-CRFs). We begin by evenly partitioning an ERP image with regular windows, where windows at the equator involve broader spherical neighbors than those at the poles. To improve the spherical relationships, our SF-CRFs enjoy two key components. Firstly, to involve sufficient spherical neighbors, we propose a Spherical Window Transform (SWT) module. This module aims to replicate the equator window's spherical relationships to all other windows, leveraging the rotational invariance of the sphere. Remarkably, the transformation process is highly efficient, completing the transformation of all windows in a 512X1024 ERP with 0.038 seconds on CPU. Secondly, we propose a Planar-Spherical Interaction (PSI) module to facilitate the relationships between regular and transformed windows, which not only preserves the local details but also captures global structures. By building a decoder based on the SF-CRFs blocks, we propose CRF360D, a novel 360 depth estimation framework that achieves state-of-the-art performance across diverse datasets. Our CRF360D is compatible with different perspective image-trained backbones (e.g., EfficientNet), serving as the encoder.
5/21/2024

Estimating Depth of Monocular Panoramic Image with Teacher-Student Model Fusing Equirectangular and Spherical Representations
Jingguo Liu, Yijun Xu, Shigang Li, Jianfeng Li
0
0
Disconnectivity and distortion are the two problems which must be coped with when processing 360 degrees equirectangular images. In this paper, we propose a method of estimating the depth of monocular panoramic image with a teacher-student model fusing equirectangular and spherical representations. In contrast with the existing methods fusing an equirectangular representation with a cube map representation or tangent representation, a spherical representation is a better choice because a sampling on a sphere is more uniform and can also cope with distortion more effectively. In this processing, a novel spherical convolution kernel computing with sampling points on a sphere is developed to extract features from the spherical representation, and then, a Segmentation Feature Fusion(SFF) methodology is utilized to combine the features with ones extracted from the equirectangular representation. In contrast with the existing methods using a teacher-student model to obtain a lighter model of depth estimation, we use a teacher-student model to learn the latent features of depth images. This results in a trained model which estimates the depth map of an equirectangular image using not only the feature maps extracted from an input equirectangular image but also the distilled knowledge learnt from the ground truth of depth map of a training set. In experiments, the proposed method is tested on several well-known 360 monocular depth estimation benchmark datasets, and outperforms the existing methods for the most evaluation indexes.
5/28/2024
PanoNormal: Monocular Indoor 360{deg} Surface Normal Estimation
Kun Huang, Fanglue Zhang, Neil Dodgson
0
0
The presence of spherical distortion on the Equirectangular image is an acknowledged challenge in dense regression computer vision tasks, such as surface normal estimation. Recent advances in convolutional neural networks (CNNs) strive to mitigate spherical distortion but often fall short in capturing holistic structures effectively, primarily due to their fixed receptive field. On the other hand, vision transformers (ViTs) excel in establishing long-range dependencies through a global self-attention mechanism, yet they encounter limitations in preserving local details. We introduce textit{PanoNormal}, a monocular surface normal estimation architecture designed for 360{deg} images, which combines the strengths of CNNs and ViTs. Specifically, we employ a multi-level global self-attention scheme with the consideration of the spherical feature distribution, enhancing the comprehensive understanding of the scene. Our experimental results demonstrate that our approach achieves state-of-the-art performance across multiple popular 360{deg} monocular datasets. The code and models will be released.
5/30/2024

Elite360D: Towards Efficient 360 Depth Estimation via Semantic- and Distance-Aware Bi-Projection Fusion
Hao Ai, Lin Wang
0
0
360 depth estimation has recently received great attention for 3D reconstruction owing to its omnidirectional field of view (FoV). Recent approaches are predominantly focused on cross-projection fusion with geometry-based re-projection: they fuse 360 images with equirectangular projection (ERP) and another projection type, e.g., cubemap projection to estimate depth with the ERP format. However, these methods suffer from 1) limited local receptive fields, making it hardly possible to capture large FoV scenes, and 2) prohibitive computational cost, caused by the complex cross-projection fusion module design. In this paper, we propose Elite360D, a novel framework that inputs the ERP image and icosahedron projection (ICOSAP) point set, which is undistorted and spatially continuous. Elite360D is superior in its capacity in learning a representation from a local-with-global perspective. With a flexible ERP image encoder, it includes an ICOSAP point encoder, and a Bi-projection Bi-attention Fusion (B2F) module (totally ~1M parameters). Specifically, the ERP image encoder can take various perspective image-trained backbones (e.g., ResNet, Transformer) to extract local features. The point encoder extracts the global features from the ICOSAP. Then, the B2F module captures the semantic- and distance-aware dependencies between each pixel of the ERP feature and the entire ICOSAP feature set. Without specific backbone design and obvious computational cost increase, Elite360D outperforms the prior arts on several benchmark datasets.
5/28/2024