Parameter Efficient Fine-tuning of Self-supervised ViTs without Catastrophic Forgetting
2404.17245
0
0
📉
Abstract
Artificial neural networks often suffer from catastrophic forgetting, where learning new concepts leads to a complete loss of previously acquired knowledge. We observe that this issue is particularly magnified in vision transformers (ViTs), where post-pre-training and fine-tuning on new tasks can significantly degrade the model's original general abilities. For instance, a DINO ViT-Base/16 pre-trained on ImageNet-1k loses over 70% accuracy on ImageNet-1k after just 10 iterations of fine-tuning on CIFAR-100. Overcoming this stability-plasticity dilemma is crucial for enabling ViTs to continuously learn and adapt to new domains while preserving their initial knowledge. In this work, we study two new parameter-efficient fine-tuning strategies: (1)~Block Expansion, and (2) Low-rank adaptation (LoRA). Our experiments reveal that using either Block Expansion or LoRA on self-supervised pre-trained ViTs surpass fully fine-tuned ViTs in new domains while offering significantly greater parameter efficiency. Notably, we find that Block Expansion experiences only a minimal performance drop in the pre-training domain, thereby effectively mitigating catastrophic forgetting in pre-trained ViTs.
Create account to get full access
Overview
- Artificial neural networks often suffer from catastrophic forgetting, where learning new concepts leads to a complete loss of previously acquired knowledge.
- This issue is particularly pronounced in vision transformers (ViTs), where post-pre-training and fine-tuning on new tasks can significantly degrade the model's original general abilities.
- Overcoming this stability-plasticity dilemma is crucial for enabling ViTs to continuously learn and adapt to new domains while preserving their initial knowledge.
Plain English Explanation
Neural networks are a type of artificial intelligence that are inspired by the human brain. They are very good at learning and adapting to new information. However, they often suffer from a problem called "catastrophic forgetting," where learning new things causes them to completely forget what they previously learned.
This issue is especially common in a type of neural network called a "vision transformer" (ViT). ViTs are good at understanding and processing visual information, but when they are trained on new tasks, they can lose a lot of their original capabilities.
Researchers are trying to solve this problem so that ViTs can continue to learn and adapt to new situations without forgetting what they already know. This would be very useful for [https://aimodels.fyi/papers/arxiv/supervised-fine-tuning-turn-improves-visual-foundation]supervised fine-tuning[/link] and [https://aimodels.fyi/papers/arxiv/inflora-interference-free-low-rank-adaptation-continual]continual learning[/link] in computer vision.
Technical Explanation
The paper explores two new parameter-efficient fine-tuning strategies to overcome catastrophic forgetting in pre-trained ViTs:
-
Block Expansion: This approach selectively expands certain blocks of the ViT model to adapt to new tasks, while leaving the majority of the model's parameters unchanged. This helps preserve the original pre-training knowledge.
-
Low-rank Adaptation (LoRA): LoRA is a lightweight fine-tuning technique that only modifies a small number of the model's parameters, allowing the core pre-trained weights to be largely preserved. This [https://aimodels.fyi/papers/arxiv/intelligent-learning-rate-distribution-to-reduce-catastrophic]reduces catastrophic forgetting[/link] compared to full fine-tuning.
The experiments show that using either Block Expansion or LoRA on self-supervised pre-trained ViTs outperforms fully fine-tuned ViTs in new domains, while offering significantly greater parameter efficiency. Notably, Block Expansion experiences only a minimal performance drop in the pre-training domain, effectively mitigating catastrophic forgetting.
Critical Analysis
The paper provides a promising solution to the challenging problem of catastrophic forgetting in ViTs. The authors' [https://aimodels.fyi/papers/arxiv/observation-analysis-solution-exploring-strong-lightweight-vision]proposed methods[/link] offer a way to continuously adapt ViTs to new tasks and domains while preserving their initial knowledge and capabilities.
However, the paper does not explore the long-term effects of these fine-tuning strategies. It would be valuable to see how the models perform after multiple rounds of fine-tuning on different tasks. Additionally, the paper could have considered other [https://aimodels.fyi/papers/arxiv/weight-copy-low-rank-adaptation-few-shot]parameter-efficient fine-tuning techniques[/link] beyond just Block Expansion and LoRA.
Overall, this research represents an important step forward in addressing the stability-plasticity dilemma in vision transformers, and the findings have the potential to significantly impact the field of continual learning in computer vision.
Conclusion
This paper presents two effective strategies, Block Expansion and Low-rank Adaptation (LoRA), for fine-tuning pre-trained vision transformers (ViTs) without suffering from catastrophic forgetting. The results show that these parameter-efficient approaches can outperform fully fine-tuned ViTs in new domains while preserving the models' original general capabilities.
These findings are significant for enabling ViTs to continuously learn and adapt to new tasks and environments, which is crucial for their widespread adoption in real-world applications. By mitigating catastrophic forgetting, the proposed methods pave the way for [https://aimodels.fyi/papers/arxiv/observation-analysis-solution-exploring-strong-lightweight-vision]more robust and versatile vision transformers[/link] that can leverage their pre-training knowledge to quickly learn new skills.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts
Samar Khanna, Medhanie Irgau, David B. Lobell, Stefano Ermon
0
0
Parameter-efficient fine-tuning (PEFT) techniques such as low-rank adaptation (LoRA) can effectively adapt large pre-trained foundation models to downstream tasks using only a small fraction (0.1%-10%) of the original trainable weights. An under-explored question of PEFT is in extending the pre-training phase without supervised labels; that is, can we adapt a pre-trained foundation model to a new domain via efficient self-supervised pre-training on this new domain? In this work, we introduce ExPLoRA, a highly effective technique to improve transfer learning of pre-trained vision transformers (ViTs) under domain shifts. Initializing a ViT with pre-trained weights on large, natural-image datasets such as from DinoV2 or MAE, ExPLoRA continues the unsupervised pre-training objective on a new domain. In this extended pre-training phase, ExPLoRA only unfreezes 1-2 pre-trained ViT blocks and all normalization layers, and then tunes all other layers with LoRA. Finally, we fine-tune the resulting model only with LoRA on this new domain for supervised learning. Our experiments demonstrate state-of-the-art results on satellite imagery, even outperforming fully pre-training and fine-tuning ViTs. Using the DinoV2 training objective, we demonstrate up to 7% improvement in linear probing top-1 accuracy on downstream tasks while using <10% of the number of parameters that are used in prior fully-tuned state-of-the art approaches. Our ablation studies confirm the efficacy of our approach over other baselines, including PEFT and simply unfreezing more transformer blocks.
6/18/2024
👀
Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference
Ting Liu, Xuyang Liu, Liangtao Shi, Zunnan Xu, Siteng Huang, Yi Xin, Quanjun Yin
0
0
Parameter-efficient fine-tuning (PEFT) has emerged as a popular approach for adapting pre-trained Vision Transformer (ViT) models to downstream applications. While current PEFT methods achieve parameter efficiency, they overlook GPU memory and time efficiency during both fine-tuning and inference, due to the repeated computation of redundant tokens in the ViT architecture. This falls short of practical requirements for downstream task adaptation. In this paper, we propose textbf{Sparse-Tuning}, a novel tuning paradigm that substantially enhances both fine-tuning and inference efficiency for pre-trained ViT models. Sparse-Tuning efficiently fine-tunes the pre-trained ViT by sparsely preserving the informative tokens and merging redundant ones, enabling the ViT to focus on the foreground while reducing computational costs on background regions in the images. To accurately distinguish informative tokens from uninformative ones, we introduce a tailored Dense Adapter, which establishes dense connections across different encoder layers in the ViT, thereby enhancing the representational capacity and quality of token sparsification. Empirical results on VTAB-1K, three complete image datasets, and two complete video datasets demonstrate that Sparse-Tuning reduces the GFLOPs to textbf{62%-70%} of the original ViT-B while achieving state-of-the-art performance. Source code is available at url{https://github.com/liuting20/Sparse-Tuning}.
5/24/2024
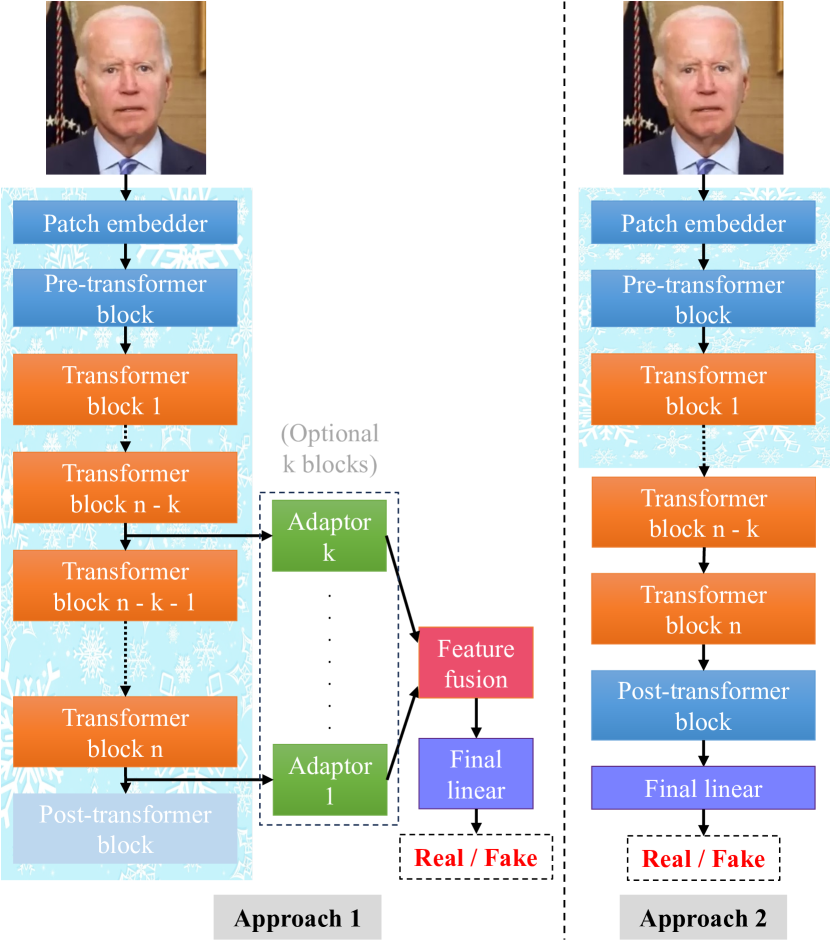
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
0
0
This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
5/2/2024
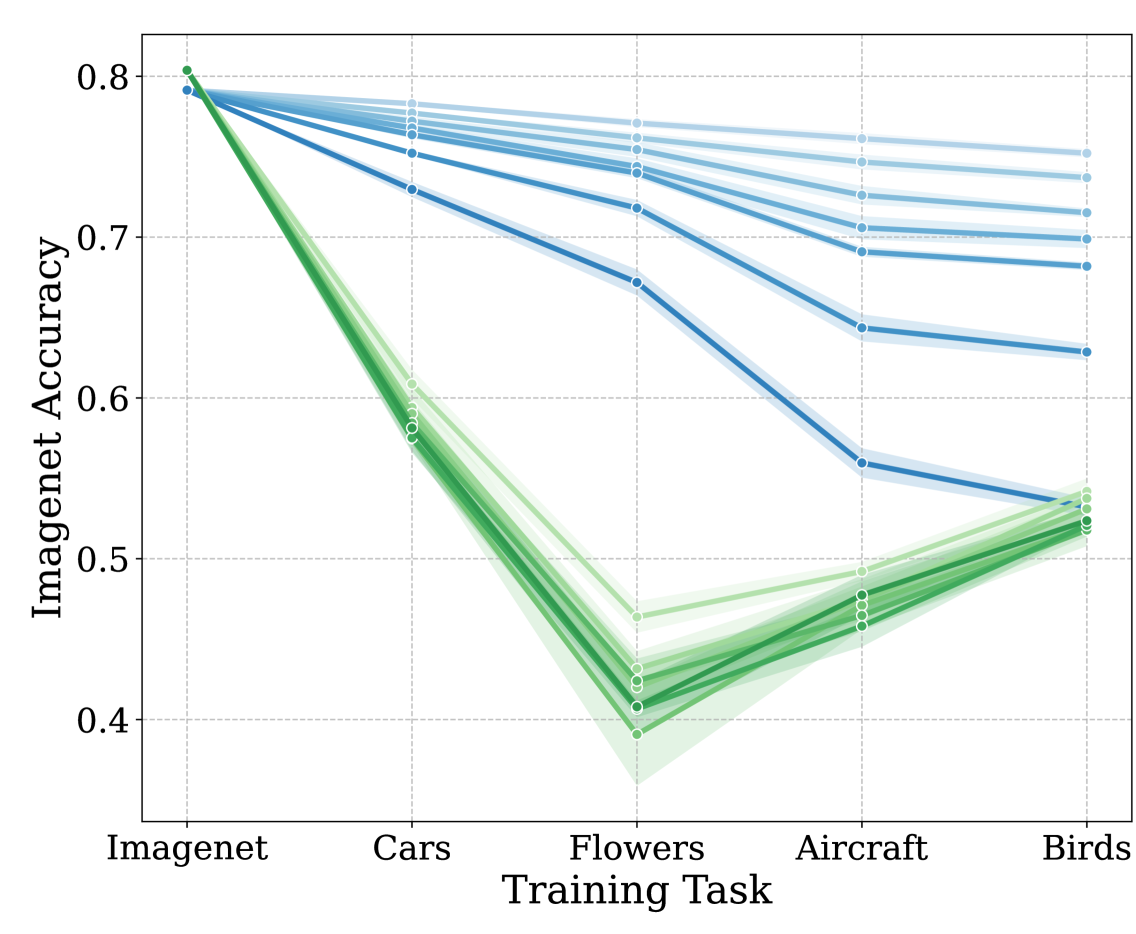
An Empirical Analysis of Forgetting in Pre-trained Models with Incremental Low-Rank Updates
Albin Soutif--Cormerais, Simone Magistri, Joost van de Weijer, Andew D. Bagdanov
0
0
Broad, open source availability of large pretrained foundation models on the internet through platforms such as HuggingFace has taken the world of practical deep learning by storm. A classical pipeline for neural network training now typically consists of finetuning these pretrained network on a small target dataset instead of training from scratch. In the case of large models this can be done even on modest hardware using a low rank training technique known as Low-Rank Adaptation (LoRA). While Low Rank training has already been studied in the continual learning setting, existing works often consider storing the learned adapter along with the existing model but rarely attempt to modify the weights of the pretrained model by merging the LoRA with the existing weights after finishing the training of each task. In this article we investigate this setting and study the impact of LoRA rank on the forgetting of the pretraining foundation task and on the plasticity and forgetting of subsequent ones. We observe that this rank has an important impact on forgetting of both the pretraining and downstream tasks. We also observe that vision transformers finetuned in that way exhibit a sort of ``contextual'' forgetting, a behaviour that we do not observe for residual networks and that we believe has not been observed yet in previous continual learning works.
5/29/2024