Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference
2405.14700
0
0
👀
Abstract
Parameter-efficient fine-tuning (PEFT) has emerged as a popular approach for adapting pre-trained Vision Transformer (ViT) models to downstream applications. While current PEFT methods achieve parameter efficiency, they overlook GPU memory and time efficiency during both fine-tuning and inference, due to the repeated computation of redundant tokens in the ViT architecture. This falls short of practical requirements for downstream task adaptation. In this paper, we propose textbf{Sparse-Tuning}, a novel tuning paradigm that substantially enhances both fine-tuning and inference efficiency for pre-trained ViT models. Sparse-Tuning efficiently fine-tunes the pre-trained ViT by sparsely preserving the informative tokens and merging redundant ones, enabling the ViT to focus on the foreground while reducing computational costs on background regions in the images. To accurately distinguish informative tokens from uninformative ones, we introduce a tailored Dense Adapter, which establishes dense connections across different encoder layers in the ViT, thereby enhancing the representational capacity and quality of token sparsification. Empirical results on VTAB-1K, three complete image datasets, and two complete video datasets demonstrate that Sparse-Tuning reduces the GFLOPs to textbf{62%-70%} of the original ViT-B while achieving state-of-the-art performance. Source code is available at url{https://github.com/liuting20/Sparse-Tuning}.
Create account to get full access
Overview
- The paper proposes a novel approach called "Sparse-Tuning" that aims to enhance both the fine-tuning and inference efficiency of pre-trained Vision Transformer (ViT) models.
- Current parameter-efficient fine-tuning (PEFT) methods for ViT models overlook GPU memory and time efficiency, leading to practical limitations for downstream task adaptation.
- Sparse-Tuning efficiently fine-tunes pre-trained ViT models by sparsely preserving informative tokens and merging redundant ones, allowing the ViT to focus on the foreground while reducing computational costs on background regions.
- The paper introduces a tailored Dense Adapter to accurately distinguish informative tokens from uninformative ones, enhancing the representational capacity and quality of token sparsification.
Plain English Explanation
Sparse-Tuning is a new technique that aims to make it easier and more efficient to adapt pre-trained Vision Transformer (ViT) models to new tasks. ViT models are powerful, but current fine-tuning methods can be slow and require a lot of computing power, which limits their practical use.
Sparse-Tuning works by identifying the most important parts of the ViT model and focusing on those, rather than trying to update the entire model. It does this by "sparsely" preserving the informative tokens (the key elements) in the ViT and merging the less important ones. This allows the ViT to concentrate on the important parts of the image or video, rather than wasting time and resources on the background.
To figure out which tokens are important, Sparse-Tuning uses a special "Dense Adapter" that looks at how the different layers of the ViT model are connected. This helps the model better understand which tokens are truly meaningful and should be kept, versus which ones can be simplified or removed.
By taking this sparse and efficient approach, Sparse-Tuning is able to reduce the computational requirements of fine-tuning and running ViT models by 30-38% while still achieving state-of-the-art performance. This makes ViT models much more practical to use in real-world applications.
Technical Explanation
Sparse-Tuning is a novel parameter-efficient fine-tuning (PEFT) approach for pre-trained Vision Transformer (ViT) models. While existing PEFT methods like PEFT, Spectral Adapter, SCT, and SpAFit achieve parameter efficiency, they overlook GPU memory and time efficiency during fine-tuning and inference.
To address this, Sparse-Tuning fine-tunes the pre-trained ViT model by sparsely preserving the informative tokens and merging redundant ones. This allows the ViT to focus on the foreground of the image/video while reducing computational costs on background regions. The key innovation is a tailored Dense Adapter module, which establishes dense connections across different encoder layers in the ViT. This enhances the representational capacity and quality of the token sparsification process.
Experimental results on various image and video datasets demonstrate that Sparse-Tuning can reduce the computational cost (GFLOPs) of the original ViT-B model by 30-38% while achieving state-of-the-art performance. The authors provide their source code publicly to enable further research and development in this area.
Critical Analysis
The Sparse-Tuning approach presents a promising direction for improving the efficiency of fine-tuning and inference for pre-trained ViT models. By selectively preserving informative tokens and merging redundant ones, the method is able to achieve significant computational savings without compromising model performance.
However, the paper does not provide a detailed analysis of the limitations or potential downsides of the approach. For example, it is unclear how the token sparsification may impact model robustness or generalization to out-of-distribution samples. Additionally, the reliance on a specialized Dense Adapter module may limit the wider applicability of the technique, as it may require additional training or architectural changes for different ViT model variants.
Further research could explore the transferability of the Sparse-Tuning approach to other transformer-based models, as well as investigate the trade-offs between computational efficiency and model performance in more depth. Rigorous evaluation on a wider range of tasks and datasets would also help to better understand the strengths and limitations of this novel fine-tuning paradigm.
Conclusion
Sparse-Tuning represents a significant advance in parameter-efficient fine-tuning of pre-trained Vision Transformer models. By introducing a sparse and efficient fine-tuning approach, the technique is able to substantially reduce the computational requirements of both fine-tuning and inference, making ViT models more practical for real-world applications.
The key innovation of Sparse-Tuning is the use of a tailored Dense Adapter module to accurately identify and preserve the most informative tokens in the ViT, while merging redundant ones. This allows the model to focus on the important parts of the input, rather than wasting resources on less relevant background information.
Overall, Sparse-Tuning demonstrates the potential for developing more efficient and practical fine-tuning methods for powerful transformer-based models like ViT. As the use of these models continues to grow, techniques like Sparse-Tuning will become increasingly important for enabling their deployment in resource-constrained environments and real-time applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sparse is Enough in Fine-tuning Pre-trained Large Language Models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, Bo Du
0
0
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
6/11/2024
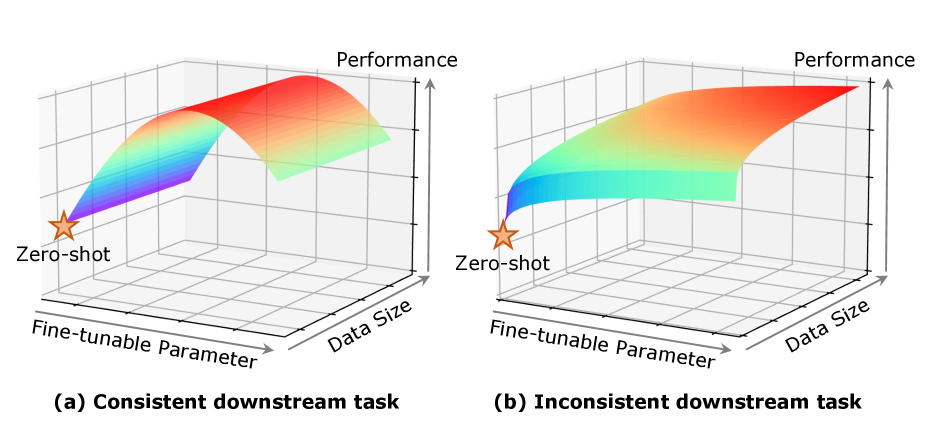
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
0
0
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
5/21/2024
🧪
Spectral Adapter: Fine-Tuning in Spectral Space
Fangzhao Zhang, Mert Pilanci
0
0
Recent developments in Parameter-Efficient Fine-Tuning (PEFT) methods for pretrained deep neural networks have captured widespread interest. In this work, we study the enhancement of current PEFT methods by incorporating the spectral information of pretrained weight matrices into the fine-tuning procedure. We investigate two spectral adaptation mechanisms, namely additive tuning and orthogonal rotation of the top singular vectors, both are done via first carrying out Singular Value Decomposition (SVD) of pretrained weights and then fine-tuning the top spectral space. We provide a theoretical analysis of spectral fine-tuning and show that our approach improves the rank capacity of low-rank adapters given a fixed trainable parameter budget. We show through extensive experiments that the proposed fine-tuning model enables better parameter efficiency and tuning performance as well as benefits multi-adapter fusion. The code will be open-sourced for reproducibility.
5/24/2024

Sparsity- and Hybridity-Inspired Visual Parameter-Efficient Fine-Tuning for Medical Diagnosis
Mingyuan Liu, Lu Xu, Shengnan Liu, Jicong Zhang
0
0
The success of Large Vision Models (LVMs) is accompanied by vast data volumes, which are prohibitively expensive in medical diagnosis.To address this, recent efforts exploit Parameter-Efficient Fine-Tuning (PEFT), which trains a small number of weights while freezing the rest.However, they typically assign trainable weights to the same positions in LVMs in a heuristic manner, regardless of task differences, making them suboptimal for professional applications like medical diagnosis.To address this, we statistically reveal the nature of sparsity and hybridity during diagnostic-targeted fine-tuning, i.e., a small portion of key weights significantly impacts performance, and these key weights are hybrid, including both task-specific and task-agnostic parts.Based on this, we propose a novel Sparsity- and Hybridity-inspired Parameter Efficient Fine-Tuning (SH-PEFT).It selects and trains a small portion of weights based on their importance, which is innovatively estimated by hybridizing both task-specific and task-agnostic strategies.Validated on six medical datasets of different modalities, we demonstrate that SH-PEFT achieves state-of-the-art performance in transferring LVMs to medical diagnosis in terms of accuracy. By tuning around 0.01% number of weights, it outperforms full model fine-tuning.Moreover, SH-PEFT also achieves comparable performance to other models deliberately optimized for specific medical tasks.Extensive experiments demonstrate the effectiveness of each design and reveal that large model transfer holds great potential in medical diagnosis.
5/29/2024