PdfTable: A Unified Toolkit for Deep Learning-Based Table Extraction

0
Sign in to get full access
Overview
- PdfTable is a unified toolkit for deep learning-based table extraction from PDF documents.
- It provides a comprehensive solution for table detection, structure recognition, and content extraction.
- The toolkit includes pre-trained models, simple APIs, and an interactive visualization tool.
Plain English Explanation
PdfTable: A Unified Toolkit for Deep Learning-Based Table Extraction is a research paper that presents a tool for extracting tables from PDF documents using deep learning techniques. The key idea is to provide a comprehensive and easy-to-use solution for various table extraction tasks, including detecting the presence of tables, recognizing their structure (e.g., identifying rows and columns), and extracting the content within the tables.
The toolkit includes pre-trained machine learning models that have been developed and tested on a wide range of PDF documents. It also provides simple APIs that allow users to integrate the table extraction functionality into their own applications or workflows. Additionally, the researchers have developed an interactive visualization tool that helps users understand and validate the table extraction process.
Technical Explanation
The PdfTable toolkit combines several deep learning-based models to tackle the different aspects of table extraction. The first component is a table detection model that can identify the presence and location of tables within a PDF document. This is followed by a structure recognition model that analyzes the detected tables and determines their row and column structure.
Once the table structure is understood, a content extraction model is used to parse the textual and numerical data within each cell of the table. The researchers have experimented with various neural network architectures, such as Transformer-based models and object detection models, to achieve high accuracy on these tasks.
The toolkit is designed to be flexible and extensible, allowing users to fine-tune the pre-trained models or integrate their own custom models into the pipeline. The interactive visualization tool provides a user-friendly interface for exploring the table extraction results and debugging any issues that may arise.
Critical Analysis
The PdfTable paper presents a comprehensive and well-designed solution for table extraction from PDF documents. The authors have carefully considered the various challenges involved in this task, such as the diverse layout and formatting of tables in real-world documents, and have proposed a modular and scalable approach to address them.
One potential limitation of the research, as mentioned in the paper, is the reliance on a relatively small dataset for training and evaluation. The authors acknowledge the need for larger and more diverse datasets to further improve the performance of the models, especially on complex or unusual table layouts.
Additionally, the paper does not provide a detailed comparison of the PdfTable toolkit's performance against other state-of-the-art table extraction systems. While the authors report strong results on their own test sets, it would be helpful to understand how the toolkit fares against alternative approaches in the literature.
Conclusion
PdfTable is a promising step towards a unified and user-friendly solution for table extraction from PDF documents. By combining advanced deep learning techniques with a modular and extensible design, the toolkit has the potential to significantly streamline and improve the table extraction process for a wide range of applications, from scientific publications to financial reports. As the field of document understanding continues to evolve, tools like PdfTable will likely play an increasingly important role in unlocking the valuable information contained within complex PDF documents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PdfTable: A Unified Toolkit for Deep Learning-Based Table Extraction
Lei Sheng, Shuai-Shuai Xu
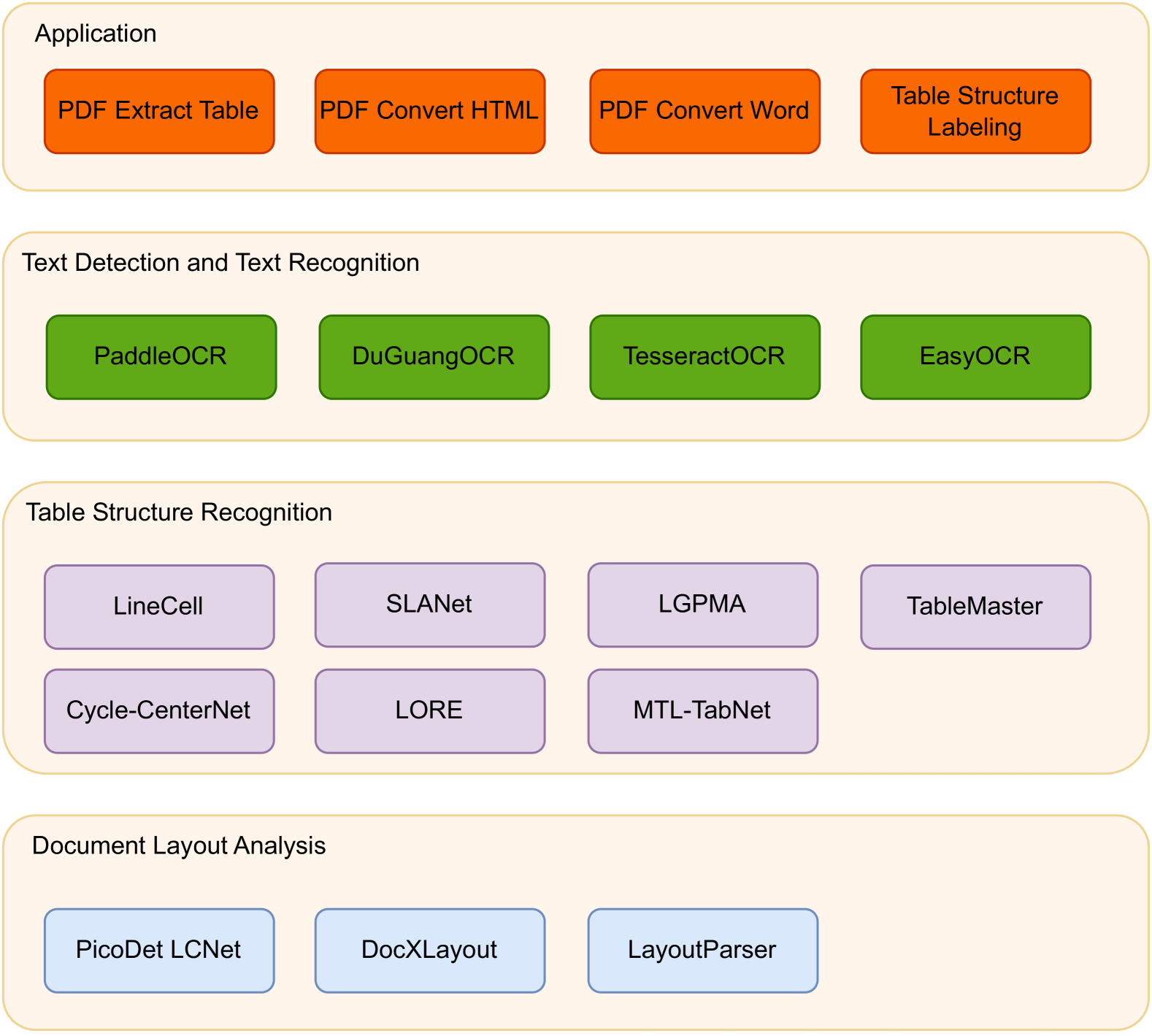
Currently, a substantial volume of document data exists in an unstructured format, encompassing Portable Document Format (PDF) files and images. Extracting information from these documents presents formidable challenges due to diverse table styles, complex forms, and the inclusion of different languages. Several open-source toolkits, such as Camelot, Plumb a PDF (pdfnumber), and Paddle Paddle Structure V2 (PP-StructureV2), have been developed to facilitate table extraction from PDFs or images. However, each toolkit has its limitations. Camelot and pdfnumber can solely extract tables from digital PDFs and cannot handle image-based PDFs and pictures. On the other hand, PP-StructureV2 can comprehensively extract image-based PDFs and tables from pictures. Nevertheless, it lacks the ability to differentiate between diverse application scenarios, such as wired tables and wireless tables, digital PDFs, and image-based PDFs. To address these issues, we have introduced the PDF table extraction (PdfTable) toolkit. This toolkit integrates numerous open-source models, including seven table recognition models, four Optical character recognition (OCR) recognition tools, and three layout analysis models. By refining the PDF table extraction process, PdfTable achieves adaptability across various application scenarios. We substantiate the efficacy of the PdfTable toolkit through verification on a self-labeled wired table dataset and the open-source wireless Publicly Table Reconition Dataset (PubTabNet). The PdfTable code will available on Github: https://github.com/CycloneBoy/pdf_table.
Read more9/10/2024
⛏️
0
Financial Table Extraction in Image Documents
William Watson, Bo Liu
Table extraction has long been a pervasive problem in financial services. This is more challenging in the image domain, where content is locked behind cumbersome pixel format. Luckily, advances in deep learning for image segmentation, OCR, and sequence modeling provides the necessary heavy lifting to achieve impressive results. This paper presents an end-to-end pipeline for identifying, extracting and transcribing tabular content in image documents, while retaining the original spatial relations with high fidelity.
Read more5/10/2024

0
TC-OCR: TableCraft OCR for Efficient Detection & Recognition of Table Structure & Content
Avinash Anand, Raj Jaiswal, Pijush Bhuyan, Mohit Gupta, Siddhesh Bangar, Md. Modassir Imam, Rajiv Ratn Shah, Shin'ichi Satoh
The automatic recognition of tabular data in document images presents a significant challenge due to the diverse range of table styles and complex structures. Tables offer valuable content representation, enhancing the predictive capabilities of various systems such as search engines and Knowledge Graphs. Addressing the two main problems, namely table detection (TD) and table structure recognition (TSR), has traditionally been approached independently. In this research, we propose an end-to-end pipeline that integrates deep learning models, including DETR, CascadeTabNet, and PP OCR v2, to achieve comprehensive image-based table recognition. This integrated approach effectively handles diverse table styles, complex structures, and image distortions, resulting in improved accuracy and efficiency compared to existing methods like Table Transformers. Our system achieves simultaneous table detection (TD), table structure recognition (TSR), and table content recognition (TCR), preserving table structures and accurately extracting tabular data from document images. The integration of multiple models addresses the intricacies of table recognition, making our approach a promising solution for image-based table understanding, data extraction, and information retrieval applications. Our proposed approach achieves an IOU of 0.96 and an OCR Accuracy of 78%, showcasing a remarkable improvement of approximately 25% in the OCR Accuracy compared to the previous Table Transformer approach.
Read more4/22/2024

0
Latent Diffusion for Guided Document Table Generation
Syed Jawwad Haider Hamdani, Saifullah Saifullah, Stefan Agne, Andreas Dengel, Sheraz Ahmed
Obtaining annotated table structure data for complex tables is a challenging task due to the inherent diversity and complexity of real-world document layouts. The scarcity of publicly available datasets with comprehensive annotations for intricate table structures hinders the development and evaluation of models designed for such scenarios. This research paper introduces a novel approach for generating annotated images for table structure by leveraging conditioned mask images of rows and columns through the application of latent diffusion models. The proposed method aims to enhance the quality of synthetic data used for training object detection models. Specifically, the study employs a conditioning mechanism to guide the generation of complex document table images, ensuring a realistic representation of table layouts. To evaluate the effectiveness of the generated data, we employ the popular YOLOv5 object detection model for training. The generated table images serve as valuable training samples, enriching the dataset with diverse table structures. The model is subsequently tested on the challenging pubtables-1m testset, a benchmark for table structure recognition in complex document layouts. Experimental results demonstrate that the introduced approach significantly improves the quality of synthetic data for training, leading to YOLOv5 models with enhanced performance. The mean Average Precision (mAP) values obtained on the pubtables-1m testset showcase results closely aligned with state-of-the-art methods. Furthermore, low FID results obtained on the synthetic data further validate the efficacy of the proposed methodology in generating annotated images for table structure.
Read more8/20/2024