PeFLL: Personalized Federated Learning by Learning to Learn
2306.05515
0
0
🖼️
Abstract
We present PeFLL, a new personalized federated learning algorithm that improves over the state-of-the-art in three aspects: 1) it produces more accurate models, especially in the low-data regime, and not only for clients present during its training phase, but also for any that may emerge in the future; 2) it reduces the amount of on-client computation and client-server communication by providing future clients with ready-to-use personalized models that require no additional finetuning or optimization; 3) it comes with theoretical guarantees that establish generalization from the observed clients to future ones. At the core of PeFLL lies a learning-to-learn approach that jointly trains an embedding network and a hypernetwork. The embedding network is used to represent clients in a latent descriptor space in a way that reflects their similarity to each other. The hypernetwork takes as input such descriptors and outputs the parameters of fully personalized client models. In combination, both networks constitute a learning algorithm that achieves state-of-the-art performance in several personalized federated learning benchmarks.
Create account to get full access
Overview
- Presents PeFLL, a new personalized federated learning algorithm
- Improves over the state-of-the-art in three key aspects:
- Produces more accurate models, even for future clients not present during training
- Reduces on-client computation and client-server communication by providing ready-to-use personalized models
- Comes with theoretical guarantees for generalization to future clients
Plain English Explanation
PeFLL is a new machine learning algorithm designed for personalized federated learning. Federated learning is a technique where multiple devices or clients collaborate to train a shared model without sharing their local data. Personalized federated learning aims to create models that are tailored to the unique characteristics of each individual client.
The key innovation of PeFLL is that it can produce highly accurate personalized models not just for the clients involved during training, but also for any new clients that join in the future. It achieves this by learning a general representation of clients in a latent space, and then using a hypernetwork to quickly generate personalized models for each client based on their position in this latent space. This means new clients can get a ready-to-use personalized model without having to do any additional training or optimization on their end.
Additionally, PeFLL reduces the computational burden and communication overhead for clients, as they don't need to perform extensive local training or send large amounts of data to the server. The algorithm also comes with theoretical guarantees that it can generalize well to future unseen clients.
Overall, PeFLL represents an advancement in personalized federated learning, allowing for more accurate, efficient, and scalable personalized models compared to previous approaches like FedMES, Personalized Wireless Federated Learning, Multi-Level Personalized Federated Learning, and EHRFL.
Technical Explanation
At the core of PeFLL is a learning-to-learn approach that jointly trains two neural networks: an embedding network and a hypernetwork. The embedding network represents each client in a low-dimensional latent descriptor space, capturing their unique characteristics. The hypernetwork then takes these client descriptors as input and outputs the parameters for a fully personalized model for each client.
By learning this two-stage process of first embedding clients and then generating personalized models, PeFLL is able to produce accurate personalized models not just for the clients seen during training, but also for any new clients that may join in the future. This is because the embedding network can generalize to map new clients into the latent space, and the hypernetwork can then quickly generate a tailored model for them.
The authors provide theoretical guarantees that this approach will generalize well to future unseen clients, based on the assumption that new clients will be similar to those observed during training in the learned latent space.
In experiments, PeFLL is shown to outperform state-of-the-art personalized federated learning algorithms on several benchmark datasets, particularly in the low-data regime where personalization is most crucial. It achieves these gains while also reducing the computational and communication costs for clients compared to approaches that require extensive local training or large data transfers.
Critical Analysis
The authors acknowledge that PeFLL's performance relies on the assumption that new clients will be similar to those seen during training, as captured by the learned latent client representations. If this assumption is violated and the system encounters very different types of clients in the future, the personalized models generated may not be as effective.
Additionally, the theoretical guarantees provided by the authors assume certain conditions about the data distribution and client similarities that may not always hold in real-world scenarios. Further empirical evaluations on more diverse datasets would help assess the robustness of PeFLL in the face of heterogeneous client populations.
Another potential limitation is that the hypernetwork approach, while efficient, may not be as expressive as allowing each client to train their own fully custom model. There could be a tradeoff between the convenience and scalability of PeFLL's approach and the ultimate personalization achievable.
Overall, PeFLL represents an interesting and promising advancement in personalized federated learning, but as with any research, there are areas that merit further exploration and validation to fully understand its strengths, weaknesses, and applicability across different real-world settings.
Conclusion
PeFLL is a novel personalized federated learning algorithm that addresses key limitations of previous approaches. By learning a general representation of clients and using a hypernetwork to quickly generate personalized models, PeFLL can produce accurate models not just for training clients, but also for any new clients that may join in the future. This reduces the computational and communication burden on clients while also providing theoretical guarantees for generalization.
While the approach shows promising results, there are some potential limitations around the assumptions made and the tradeoffs involved. Further research is needed to fully understand PeFLL's robustness and applicability across diverse real-world scenarios. Nevertheless, this work represents an important step forward in the field of personalized federated learning, with implications for privacy-preserving, scalable, and customized machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024
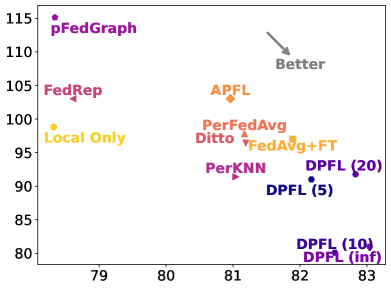
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024

FedMeS: Personalized Federated Continual Learning Leveraging Local Memory
Jin Xie, Chenqing Zhu, Songze Li
0
0
We focus on the problem of Personalized Federated Continual Learning (PFCL): a group of distributed clients, each with a sequence of local tasks on arbitrary data distributions, collaborate through a central server to train a personalized model at each client, with the model expected to achieve good performance on all local tasks. We propose a novel PFCL framework called Federated Memory Strengthening FedMeS to address the challenges of client drift and catastrophic forgetting. In FedMeS, each client stores samples from previous tasks using a small amount of local memory, and leverages this information to both 1) calibrate gradient updates in training process; and 2) perform KNN-based Gaussian inference to facilitate personalization. FedMeS is designed to be task-oblivious, such that the same inference process is applied to samples from all tasks to achieve good performance. FedMeS is analyzed theoretically and evaluated experimentally. It is shown to outperform all baselines in average accuracy and forgetting rate, over various combinations of datasets, task distributions, and client numbers.
4/22/2024
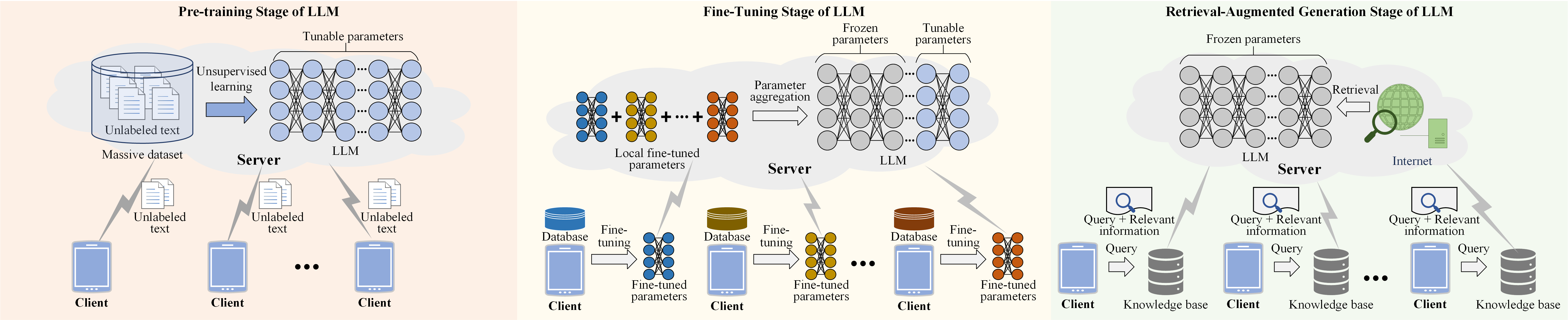
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024