PEFT-U: Parameter-Efficient Fine-Tuning for User Personalization

0
📉
Sign in to get full access
Overview
- PEFT-U is a research paper that proposes a parameter-efficient fine-tuning method for personalizing large language models to individual users.
- The method involves training a small number of model parameters while keeping the majority of the model frozen, allowing for personalization with minimal computational overhead.
- The paper introduces a novel PEFT-U benchmark for evaluating personalization performance on various tasks and datasets.
Plain English Explanation
PEFT-U is a technique that allows large language models to be customized for individual users without requiring a lot of additional training. Large language models, like those used for tasks like text generation or question answering, are powerful but can be computationally expensive to train from scratch. PEFT-U avoids this by only updating a small portion of the model's parameters, while leaving the majority of the model unchanged. This allows the model to be personalized for each user while still leveraging the general knowledge encoded in the larger model.
The paper also introduces a new benchmark for evaluating how well these personalized models perform on different tasks and datasets. This helps researchers and developers compare the effectiveness of different personalization techniques.
Technical Explanation
The key technical innovation in PEFT-U is the way it fine-tunes a pre-trained language model to personalize it for individual users. Instead of updating all the model parameters, PEFT-U only updates a small subset, leaving the majority of the model's parameters frozen. This reduced parameter count allows for more efficient personalization, as less computation and data is required to update the model.
The paper evaluates PEFT-U on a variety of personalization tasks and datasets, which are collectively referred to as the "PEFT-U Benchmark". This includes tasks like personalized text generation and few-shot learning for individual users. The results demonstrate that PEFT-U can effectively personalize large language models while only updating a small fraction of the total parameters.
Critical Analysis
The paper provides a thorough evaluation of the PEFT-U method, exploring its performance across multiple personalization tasks and datasets. However, the authors acknowledge that the scope of the benchmark is limited, and there may be additional personalization challenges not captured by the current suite of tasks.
Additionally, while PEFT-U achieves impressive results, there may be further opportunities to reduce the parameter count or computational overhead required for personalization. The paper does not extensively explore the tradeoffs between the degree of personalization and the required computational resources.
Overall, PEFT-U represents a promising step forward in making large language models more adaptable to individual users. Further research in this area could lead to even more efficient and effective personalization techniques.
Conclusion
The PEFT-U paper introduces a novel parameter-efficient fine-tuning method for personalizing large language models. By only updating a small subset of the model's parameters, PEFT-U can customize the model for individual users while minimizing the computational overhead. The paper also presents a comprehensive benchmark for evaluating personalization performance, which can help drive progress in this important area of language model research and development.
The PEFT-U approach has the potential to make large language models more accessible and useful for a wider range of applications and user contexts, by enabling efficient personalization without the need for resource-intensive retraining. As AI systems become increasingly ubiquitous, techniques like PEFT-U will be crucial for ensuring these models can be tailored to meet the diverse needs of individual users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
PEFT-U: Parameter-Efficient Fine-Tuning for User Personalization
Christopher Clarke, Yuzhao Heng, Lingjia Tang, Jason Mars
The recent emergence of Large Language Models (LLMs) has heralded a new era of human-AI interaction. These sophisticated models, exemplified by Chat-GPT and its successors, have exhibited remarkable capabilities in language understanding. However, as these LLMs have undergone exponential growth, a crucial dimension that remains understudied is the personalization of these models. Large foundation models such as GPT-3 etc. focus on creating a universal model that serves a broad range of tasks and users. This approach emphasizes the model's generalization capabilities, treating users as a collective rather than as distinct individuals. While practical for many common applications, this one-size-fits-all approach often fails to address the rich tapestry of human diversity and individual needs. To explore this issue we introduce the PEFT-U Benchmark: a new dataset for building and evaluating NLP models for user personalization. datasetname{} consists of a series of user-centered tasks containing diverse and individualized expressions where the preferences of users can potentially differ for the same input. Using PEFT-U, we explore the challenge of efficiently personalizing LLMs to accommodate user-specific preferences in the context of diverse user-centered tasks.
Read more7/26/2024
0
Customizing Large Language Model Generation Style using Parameter-Efficient Finetuning
Xinyue Liu, Harshita Diddee, Daphne Ippolito
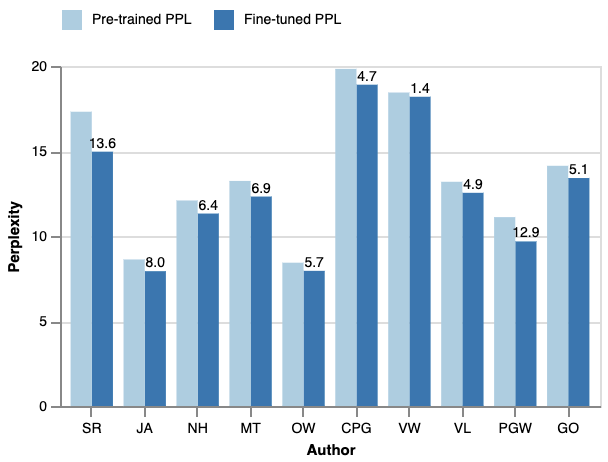
One-size-fits-all large language models (LLMs) are increasingly being used to help people with their writing. However, the style these models are trained to write in may not suit all users or use cases. LLMs would be more useful as writing assistants if their idiolect could be customized to match each user. In this paper, we explore whether parameter-efficient finetuning (PEFT) with Low-Rank Adaptation can effectively guide the style of LLM generations. We use this method to customize LLaMA-2 to ten different authors and show that the generated text has lexical, syntactic, and surface alignment with the target author but struggles with content memorization. Our findings highlight the potential of PEFT to support efficient, user-level customization of LLMs.
Read more9/10/2024

0
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
Read more4/30/2024

0
Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Sravanthi Rajanala, Yi Fang
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
Read more4/15/2024