On permutation-invariant neural networks
2403.17410
0
0
Abstract
Conventional machine learning algorithms have traditionally been designed under the assumption that input data follows a vector-based format, with an emphasis on vector-centric paradigms. However, as the demand for tasks involving set-based inputs has grown, there has been a paradigm shift in the research community towards addressing these challenges. In recent years, the emergence of neural network architectures such as Deep Sets and Transformers has presented a significant advancement in the treatment of set-based data. These architectures are specifically engineered to naturally accommodate sets as input, enabling more effective representation and processing of set structures. Consequently, there has been a surge of research endeavors dedicated to exploring and harnessing the capabilities of these architectures for various tasks involving the approximation of set functions. This comprehensive survey aims to provide an overview of the diverse problem settings and ongoing research efforts pertaining to neural networks that approximate set functions. By delving into the intricacies of these approaches and elucidating the associated challenges, the survey aims to equip readers with a comprehensive understanding of the field. Through this comprehensive perspective, we hope that researchers can gain valuable insights into the potential applications, inherent limitations, and future directions of set-based neural networks. Indeed, from this survey we gain two insights: i) Deep Sets and its variants can be generalized by differences in the aggregation function, and ii) the behavior of Deep Sets is sensitive to the choice of the aggregation function. From these observations, we show that Deep Sets, one of the well-known permutation-invariant neural networks, can be generalized in the sense of a quasi-arithmetic mean.
Create account to get full access
Introduction
This paper discusses the advancement of machine learning algorithms to handle more complex data structures beyond simple vectors, such as sets. The key points are:
- Machine learning has achieved significant success in many fields, traditionally using vector-based algorithms.
- However, there is growing interest in algorithms that can handle more complex data structures, such as sets.
- Set data structures include sets of vector data (e.g. image vectors) and point cloud data (spatial coordinates).
- The goal is to utilize machine learning models to approximate set functions, which operate on sets of elements or data points.
- A key property of set functions is permutation invariance - the output remains the same regardless of the order of elements in the set.
- Popular neural network architectures like VGG and ResNet do not inherently possess this permutation-invariant property.
- The primary research interest is in determining neural network architectures that can achieve permutation invariance while maintaining performance.
- The paper introduces such model architectures, provides an overview of the objective tasks, and discusses theoretical analyses of neural network approximations for permutation-invariant functions.
- The paper also lists well-known datasets for evaluating research in this area.
- Finally, the paper proposes a novel generalization of the Deep Sets architecture using the concept of quasi-arithmetic mean.
Preliminary and related concepts
This text introduces key definitions and concepts related to set functions and their properties. It defines the ground set 𝒱 and the mapping 𝜑 that associates each element in 𝒱 with a corresponding vector. The concept of permutation invariance is then introduced, where a set function Φ is permutation invariant if its value remains the same regardless of the order of elements in the input set. This is an important property for accurately modeling set-based tasks using neural networks.
The text also defines permutation equivariance, where a function Φ is permutation equivariant if permuting the input instances permutes the output labels accordingly. Permutation equivariance is another crucial property for set-based neural network models. Recent studies have shown that permutation invariant transformations can be constructed by combining multiple permutation equivariant transformations.
Overall, the provided section establishes the necessary mathematical foundations and key concepts that underlie the modeling of set functions using neural networks.
Model architectures for approximating set functions
This section provides an overview of neural network architectures that can approximate set functions. Table 1 summarizes various architectures and their corresponding applications. The focus is on architectures that follow the idea of Deep Sets, which demonstrated universality results for permutation-invariant inputs.
Prior to Deep Sets, several similar studies on related architectures existed, such as achieving invariance through pose normalization or by averaging a possibly nonlinear function over a group.
Deep Sets is a seminal work for approximating set functions by neural networks. Its architecture satisfies permutation-invariance and can represent set functions using arbitrary neural networks. Deep Sets is also known to have universality for permutation-invariant and sum-decomposable set functions.
PointNet is another well-known architecture for processing point cloud data, which differs from Deep Sets in its pooling operation. The architectures of Deep Sets and PointNet can be expressed in a unified notation, with Deep Sets being sum-decomposable and PointNet being max-decomposable.
The Set Transformer architecture utilizes the Transformer architecture to handle permutation-invariant inputs, addressing the limitation of Deep Sets and PointNet by introducing an attention mechanism that considers the relationships between elements in the input set.
The section also discusses extensions and variants of these architectures, such as Deep Sets++, Set Transformer++, DSPN, iDSPN, SetVAE, PointCLIP, Slot Attention, and Perceiver. These architectures explore various techniques to improve the performance and capabilities of neural networks for set-based tasks.
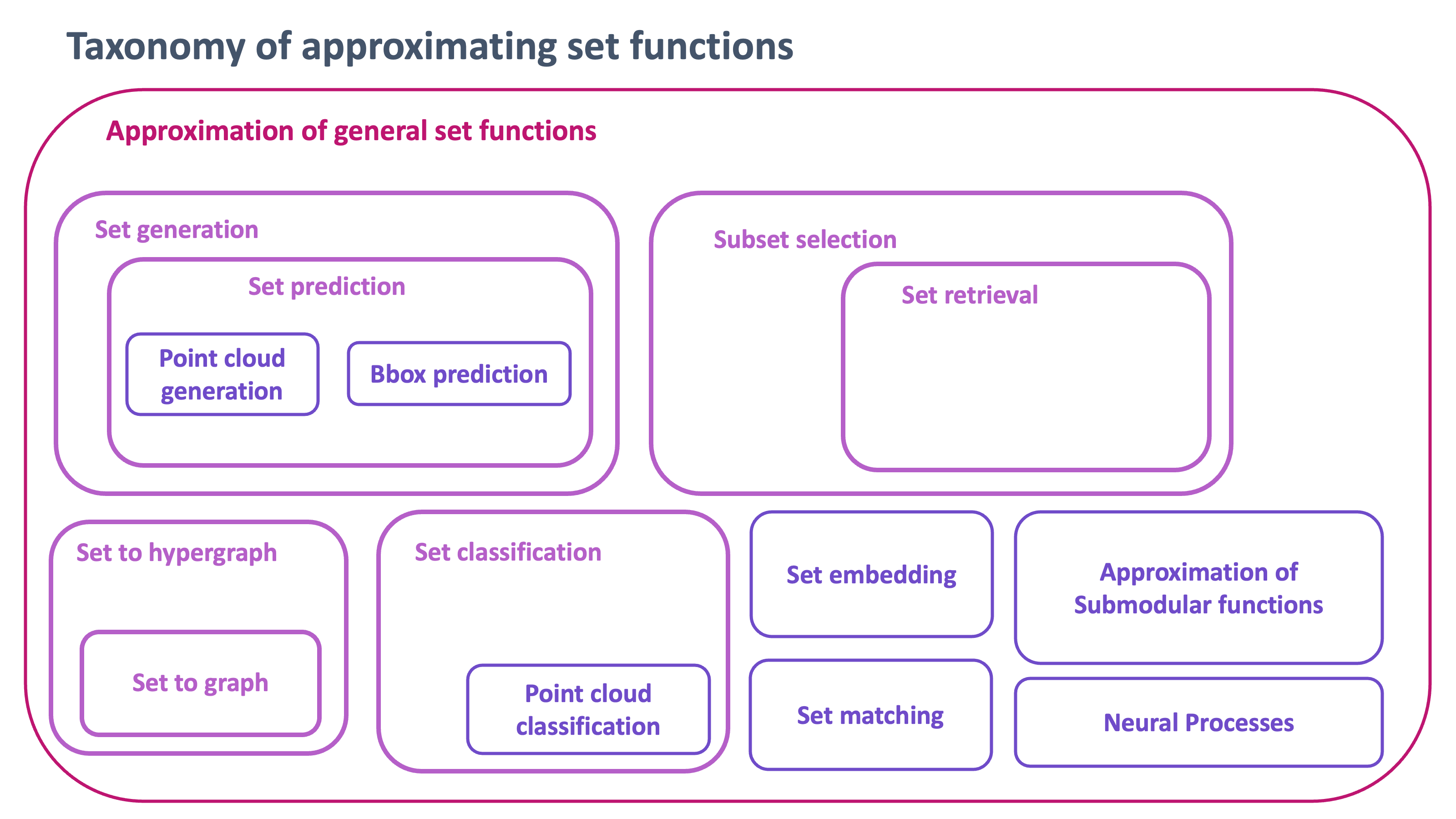
Tasks of approximating set functions
The paper organizes the tasks addressed by neural networks that approximate set functions. Figure 2 presents a taxonomy of these set function approximation tasks.
This section covers several topics related to set-based machine learning tasks:
Point cloud processing: Methods like CurveNet treat point clouds as graphs and aggregate points along curves to represent the structure.
Set retrieval and subset selection: Set retrieval aims to search and retrieve sets from a large pool. Subset selection chooses a subset that retains meaningful properties. SetNet uses a NetVLAD layer for set retrieval.
Set generation and prediction: Two main approaches are distribution matching, which approximates the conditional probability of a set, and minimum assignment, which calculates a loss between assigned pairs. Techniques like Deep Set Prediction Networks, SetVAE, and Detection Transformer leverage these ideas.
Set matching: Estimating the degree of matching between homogeneous or heterogeneous sets. Recent work has analyzed negative sampling and task-specific distribution shifts.
Neural processes: Conditional Neural Processes and Neural Processes model conditional predictive distributions and enable function sampling respectively. Attentive Neural Processes address underfitting.
Approximating submodular functions: Submodular functions satisfy a diminishing returns property. Deep Sets and PointNet architectures are shown to take the form of modular and submodular functions.
Other applications: Person re-identification, metric learning, explainable AI, and federated learning are discussed in the context of set-based methods.
Theoretical analysis of approximating set functions
This section reviews several theoretical results on the approximation of set functions. It discusses sum-decomposability, Janossy pooling, and the expressive power of Deep Sets and PointNet architectures.
Key points:
- Janossy pooling is a generalization of Deep Sets and self-attention that can represent any permutation-invariant function.
- Deep Sets and PointNet have different representation capabilities. Deep Sets can represent any continuous permutation-invariant function, but PointNet has limitations in approximating certain functions like averages.
- The required latent dimension in Deep Sets scales with the size of the input set. Larger input sets require higher latent dimensions for optimal performance.
- The choice of aggregation function in Deep Sets is crucial. Recurrent and query-based aggregations can provide improved robustness and performance compared to simple sum or max pooling.
The section also provides detailed theorems, proofs, and illustrations to support these findings. Overall, it presents a comprehensive analysis of the theoretical and empirical properties of set function approximation methods.
Datasets
This section introduces several commonly used datasets for evaluating the performance of neural networks that approximate set functions:
Flow-RBC: This dataset consists of 98,240 training examples and 23,104 test examples, where each input set represents the distribution of 1,000 red blood cells characterized by volume and hemoglobin content measurements. The task involves predicting the corresponding hematocrit level.
Celebrity Together: This dataset contains 194k images with a total of 546k faces, suitable for evaluating set retrieval methods. It includes full images with multiple labeled faces, unlike other face datasets with only individual face crops.
SHIFT15M: This dataset is designed for assessing set-to-set matching models under distribution shift assumptions. It contains 2.5m sets and 15m fashion items, allowing evaluation across different levels of dataset shift.
CLEVR: This is a synthetic Visual Question Answering dataset with 3D-rendered objects. It consists of a training set of 70k images and 700k questions, a validation set of 15k images and 150k questions, and a test set of 15k images and 150k questions.
ShapeNet: A large-scale repository for 3D CAD models, with over 300M models and 220,000 classified into 3,135 classes. The ShapeNet Parts subset contains 31,693 meshes categorized into 16 common object classes.
ModelNet40: This dataset contains 12,311 pre-aligned shapes from 40 categories, split into 9,843 for training and 2,468 for testing.
3D MNIST: A 3D version of the MNIST dataset of handwritten digits, containing 6,000 instances of 3D point clouds generated from the original images.
A Special Class of Deep Sets: Hölder’s Power Deep Sets
This paper considers generalizing Deep Sets and PointNet as differences in aggregation functions. The authors introduce a quasi-arithmetic mean function called the Hölder's Power Mean, which includes several special cases like the arithmetic mean, geometric mean, and max pooling.
By using this Hölder's Power Mean as the aggregation function, the authors define the Hölder's Power Deep Sets architecture. This allows them to explore the effects of different choices of the power exponent p.
The key findings are:
- The optimal value of p depends on the dataset and problem setting. Choosing the right p can outperform the special cases of Deep Sets (p=1) and PointNet (p=+∞).
- The authors experiment with optimizing p using linear search, Bayesian optimization, and gradient descent. These methods can find good values of p in reasonable computation time.
- The paper also discusses some limitations of this approach, noting that further experimental and theoretical analysis is needed when using nonlinear functions.
Overall, the paper proposes a parameterized generalization of Deep Sets and PointNet and shows it can lead to improved performance by tuning the aggregation function.
Conclusion and discussion
The provided text discusses the importance of ensuring permutation-invariance when dealing with set data, rather than typical vector data, in machine learning models. It reviews various neural network architectures that satisfy permutation-invariance and highlights how they benefit a range of tasks. Permutation-invariant architectures enhance the ability to learn from and make predictions on set data, as well as enable more sophisticated handling of complex structures in machine learning.
The text then outlines future research directions for machine learning models that handle sets or permutation-invariant vectors. Key areas include:
- Insufficient research in specific areas like XAI and federated learning for neural networks dealing with sets.
- The need for more diverse and large-scale datasets, similar to ImageNet, to advance the field.
- Efficiently optimizing the wide range of parameters introduced in the generalized Deep Sets model.
- Further generalizing the Hölder's Power Deep Sets formulation.
- Conducting theoretical analysis of the generalized Deep Sets model.
- Comprehensive experimentation on a larger number of datasets to gain deeper insights.
Overall, the text highlights the promising potential of permutation-invariant neural networks and the various research opportunities to refine these models, address challenges, and uncover novel applications in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Enhancing Neural Subset Selection: Integrating Background Information into Set Representations
Binghui Xie, Yatao Bian, Kaiwen zhou, Yongqiang Chen, Peilin Zhao, Bo Han, Wei Meng, James Cheng
0
0
Learning neural subset selection tasks, such as compound selection in AI-aided drug discovery, have become increasingly pivotal across diverse applications. The existing methodologies in the field primarily concentrate on constructing models that capture the relationship between utility function values and subsets within their respective supersets. However, these approaches tend to overlook the valuable information contained within the superset when utilizing neural networks to model set functions. In this work, we address this oversight by adopting a probabilistic perspective. Our theoretical findings demonstrate that when the target value is conditioned on both the input set and subset, it is essential to incorporate an textit{invariant sufficient statistic} of the superset into the subset of interest for effective learning. This ensures that the output value remains invariant to permutations of the subset and its corresponding superset, enabling identification of the specific superset from which the subset originated. Motivated by these insights, we propose a simple yet effective information aggregation module designed to merge the representations of subsets and supersets from a permutation invariance perspective. Comprehensive empirical evaluations across diverse tasks and datasets validate the enhanced efficacy of our approach over conventional methods, underscoring the practicality and potency of our proposed strategies in real-world contexts.
6/11/2024
On the H{o}lder Stability of Multiset and Graph Neural Networks
Yair Davidson, Nadav Dym
0
0
Famously, multiset neural networks based on sum-pooling can separate all distinct multisets, and as a result can be used by message passing neural networks (MPNNs) to separate all pairs of graphs that can be separated by the 1-WL graph isomorphism test. However, the quality of this separation may be very weak, to the extent that the embeddings of separable multisets and graphs might even be considered identical when using fixed finite precision. In this work, we propose to fully analyze the separation quality of multiset models and MPNNs via a novel adaptation of Lipschitz and H{o}lder continuity to parametric functions. We prove that common sum-based models are lower-H{o}lder continuous, with a H{o}lder exponent that decays rapidly with the network's depth. Our analysis leads to adversarial examples of graphs which can be separated by three 1-WL iterations, but cannot be separated in practice by standard maximally powerful MPNNs. To remedy this, we propose two novel MPNNs with improved separation quality, one of which is lower Lipschitz continuous. We show these MPNNs can easily classify our adversarial examples, and compare favorably with standard MPNNs on standard graph learning tasks.
6/12/2024
🔍
Permutation invariant functions: statistical tests, density estimation, and computationally efficient embedding
Wee Chaimanowong, Ying Zhu
0
0
Permutation invariance is among the most common symmetry that can be exploited to simplify complex problems in machine learning (ML). There has been a tremendous surge of research activities in building permutation invariant ML architectures. However, less attention is given to: (1) how to statistically test for permutation invariance of coordinates in a random vector where the dimension is allowed to grow with the sample size; (2) how to leverage permutation invariance in estimation problems and how does it help reduce dimensions. In this paper, we take a step back and examine these questions in several fundamental problems: (i) testing the assumption of permutation invariance of multivariate distributions; (ii) estimating permutation invariant densities; (iii) analyzing the metric entropy of permutation invariant function classes and compare them with their counterparts without imposing permutation invariance; (iv) deriving an embedding of permutation invariant reproducing kernel Hilbert spaces for efficient computation. In particular, our methods for (i) and (iv) are based on a sorting trick and (ii) is based on an averaging trick. These tricks substantially simplify the exploitation of permutation invariance.
5/10/2024
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
0
0
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
5/28/2024