Permutation invariant functions: statistical tests, density estimation, and computationally efficient embedding
2403.01671
0
0
🔍
Abstract
Permutation invariance is among the most common symmetry that can be exploited to simplify complex problems in machine learning (ML). There has been a tremendous surge of research activities in building permutation invariant ML architectures. However, less attention is given to: (1) how to statistically test for permutation invariance of coordinates in a random vector where the dimension is allowed to grow with the sample size; (2) how to leverage permutation invariance in estimation problems and how does it help reduce dimensions. In this paper, we take a step back and examine these questions in several fundamental problems: (i) testing the assumption of permutation invariance of multivariate distributions; (ii) estimating permutation invariant densities; (iii) analyzing the metric entropy of permutation invariant function classes and compare them with their counterparts without imposing permutation invariance; (iv) deriving an embedding of permutation invariant reproducing kernel Hilbert spaces for efficient computation. In particular, our methods for (i) and (iv) are based on a sorting trick and (ii) is based on an averaging trick. These tricks substantially simplify the exploitation of permutation invariance.
Create account to get full access
Overview
- The paper explores the statistical and computational aspects of exploiting permutation invariance in machine learning problems.
- It addresses key questions about testing for permutation invariance, estimating permutation invariant densities, and efficiently computing in permutation invariant function spaces.
- The authors propose novel techniques, such as a "sorting trick" and an "averaging trick," to simplify the use of permutation invariance in these fundamental problems.
Plain English Explanation
Permutation invariance is an important symmetry that machine learning models can take advantage of to simplify complex problems. Permutation invariant neural networks are a prime example of this concept in action. However, the statistical and computational aspects of using permutation invariance have not been fully explored.
This paper aims to address some key questions in this area. First, it looks at how to test whether the coordinates of a random vector are truly permutation invariant, even as the dimensionality of the vector grows. This is important for assessing the invariance of representations learned by machine learning models.
Next, the paper examines how to estimate probability distributions that are permutation invariant. This could be useful for modeling data with inherent symmetries, such as the arrangement of atoms in a molecule.
The authors also analyze the complexity of permutation invariant function classes, comparing them to their non-invariant counterparts. This provides insights into the statistical properties of invariant representations and how they might behave in machine learning tasks.
Finally, the paper proposes an efficient way to compute in permutation invariant function spaces, using a clever "embedding" technique. This could lead to more scalable machine learning methods that exploit symmetries in data.
Overall, this work takes a deeper look at the theoretical and practical aspects of leveraging permutation invariance in machine learning, providing tools and insights that could benefit a wide range of applications.
Technical Explanation
The paper begins by highlighting the importance of permutation invariance as a common symmetry that can be exploited to simplify complex machine learning problems. However, the authors note that there has been limited research into the statistical and computational aspects of using permutation invariance.
To address this gap, the paper examines several fundamental problems:
-
Testing for permutation invariance: The authors propose a method to statistically test whether the coordinates of a random vector are permutation invariant, even as the dimensionality of the vector grows with the sample size. This is based on a "sorting trick" that simplifies the testing procedure.
-
Estimating permutation invariant densities: The paper presents an approach for estimating probability distributions that are permutation invariant. This "averaging trick" involves taking the average of all permutations of the input data to obtain the permutation invariant density estimate.
-
Analyzing metric entropy: The authors derive bounds on the metric entropy (a measure of function class complexity) for permutation invariant function classes and compare them to their non-invariant counterparts. This provides insights into the statistical properties of permutation invariant representations.
-
Efficient computation in permutation invariant spaces: Finally, the paper proposes an embedding technique that allows for efficient computation in permutation invariant reproducing kernel Hilbert spaces. This could enable more scalable machine learning methods that exploit symmetries in data.
Throughout the paper, the authors demonstrate how their proposed "tricks" can substantially simplify the exploitation of permutation invariance in these fundamental problems, paving the way for more advanced applications of this important symmetry in machine learning.
Critical Analysis
The paper makes valuable contributions by addressing key statistical and computational challenges in leveraging permutation invariance for machine learning. The proposed methods, such as the sorting and averaging tricks, provide practical solutions to problems that have received relatively little attention in the literature.
One potential limitation of the work is that it focuses primarily on the theoretical and mathematical aspects of permutation invariance, without extensive empirical validation. While the authors provide some illustrative examples, more comprehensive experiments on real-world datasets could further demonstrate the benefits and practical implications of their techniques.
Additionally, the paper does not delve into the broader context of how permutation invariance relates to other types of symmetries and invariances in machine learning, such as translation, rotation, or scale invariance. Exploring the connections and potential synergies between these different forms of invariance could lead to a more holistic understanding of the role of symmetries in machine learning.
Furthermore, the paper does not address potential challenges or caveats that may arise when applying these techniques in practice. For example, the sensitivity of the proposed tests for permutation invariance to factors like noise, outliers, or sample size could be important considerations for real-world deployment.
Despite these minor limitations, the paper represents a valuable contribution to the growing body of research on exploiting symmetries in machine learning. The authors' insights and techniques could inspire further advancements in this area, potentially leading to more efficient, robust, and interpretable machine learning models across a wide range of applications.
Conclusion
This paper takes a deep dive into the statistical and computational aspects of leveraging permutation invariance in machine learning. By addressing key questions around testing for permutation invariance, estimating permutation invariant densities, analyzing function class complexities, and efficiently computing in permutation invariant spaces, the authors provide a comprehensive framework for better understanding and utilizing this important symmetry.
The proposed "sorting trick" and "averaging trick" demonstrate how permutation invariance can be exploited in a computationally efficient manner, potentially enabling more scalable and powerful machine learning models. These insights could have far-reaching implications, from modeling data with inherent symmetries to learning using statistical invariants.
Overall, this work represents a significant step forward in our understanding of the theoretical and practical aspects of permutation invariance, and could inspire further advancements in the field of machine learning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
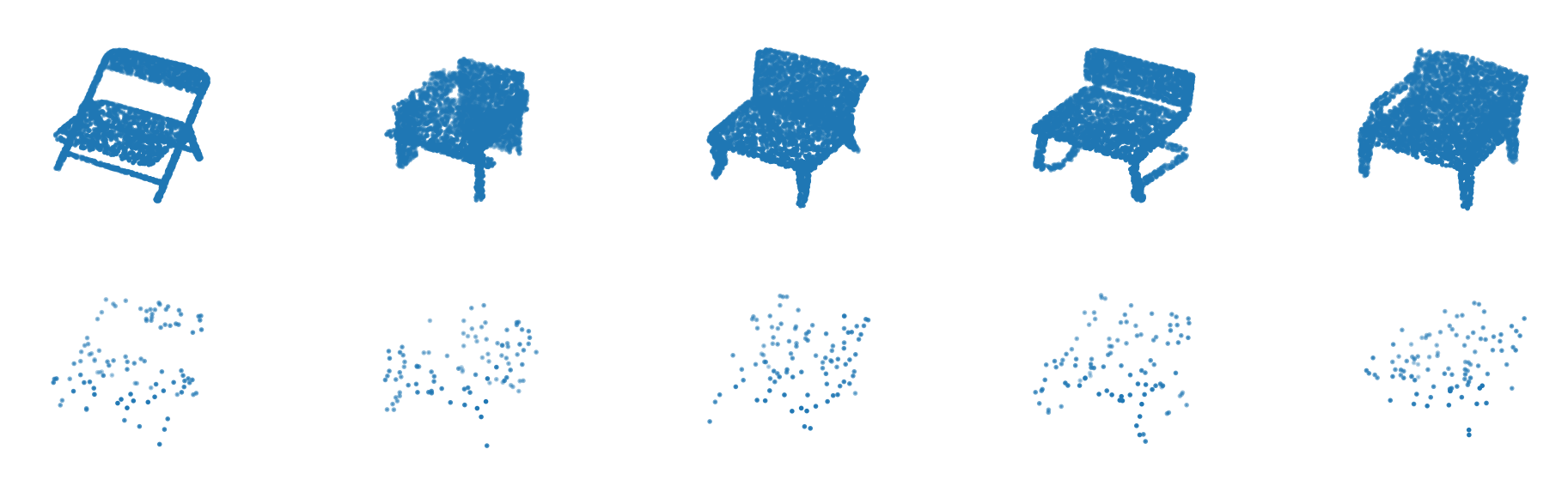
Learning functions on symmetric matrices and point clouds via lightweight invariant features
Ben Blum-Smith, Ningyuan Huang, Marco Cuturi, Soledad Villar
0
0
In this work, we present a mathematical formulation for machine learning of (1) functions on symmetric matrices that are invariant with respect to the action of permutations by conjugation, and (2) functions on point clouds that are invariant with respect to rotations, reflections, and permutations of the points. To achieve this, we construct $O(n^2)$ invariant features derived from generators for the field of rational functions on $ntimes n$ symmetric matrices that are invariant under joint permutations of rows and columns. We show that these invariant features can separate all distinct orbits of symmetric matrices except for a measure zero set; such features can be used to universally approximate invariant functions on almost all weighted graphs. For point clouds in a fixed dimension, we prove that the number of invariant features can be reduced, generically without losing expressivity, to $O(n)$, where $n$ is the number of points. We combine these invariant features with DeepSets to learn functions on symmetric matrices and point clouds with varying sizes. We empirically demonstrate the feasibility of our approach on molecule property regression and point cloud distance prediction.
5/16/2024
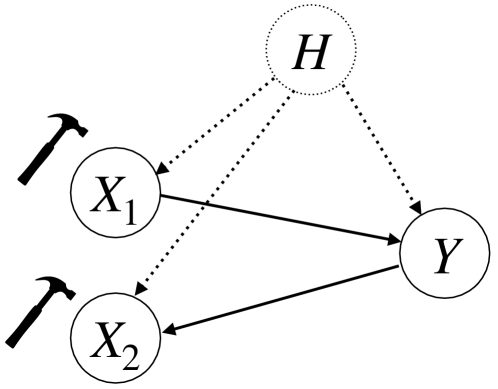
Invariant Probabilistic Prediction
Alexander Henzi, Xinwei Shen, Michael Law, Peter Buhlmann
0
0
In recent years, there has been a growing interest in statistical methods that exhibit robust performance under distribution changes between training and test data. While most of the related research focuses on point predictions with the squared error loss, this article turns the focus towards probabilistic predictions, which aim to comprehensively quantify the uncertainty of an outcome variable given covariates. Within a causality-inspired framework, we investigate the invariance and robustness of probabilistic predictions with respect to proper scoring rules. We show that arbitrary distribution shifts do not, in general, admit invariant and robust probabilistic predictions, in contrast to the setting of point prediction. We illustrate how to choose evaluation metrics and restrict the class of distribution shifts to allow for identifiability and invariance in the prototypical Gaussian heteroscedastic linear model. Motivated by these findings, we propose a method to yield invariant probabilistic predictions, called IPP, and study the consistency of the underlying parameters. Finally, we demonstrate the empirical performance of our proposed procedure on simulated as well as on single-cell data.
6/18/2024
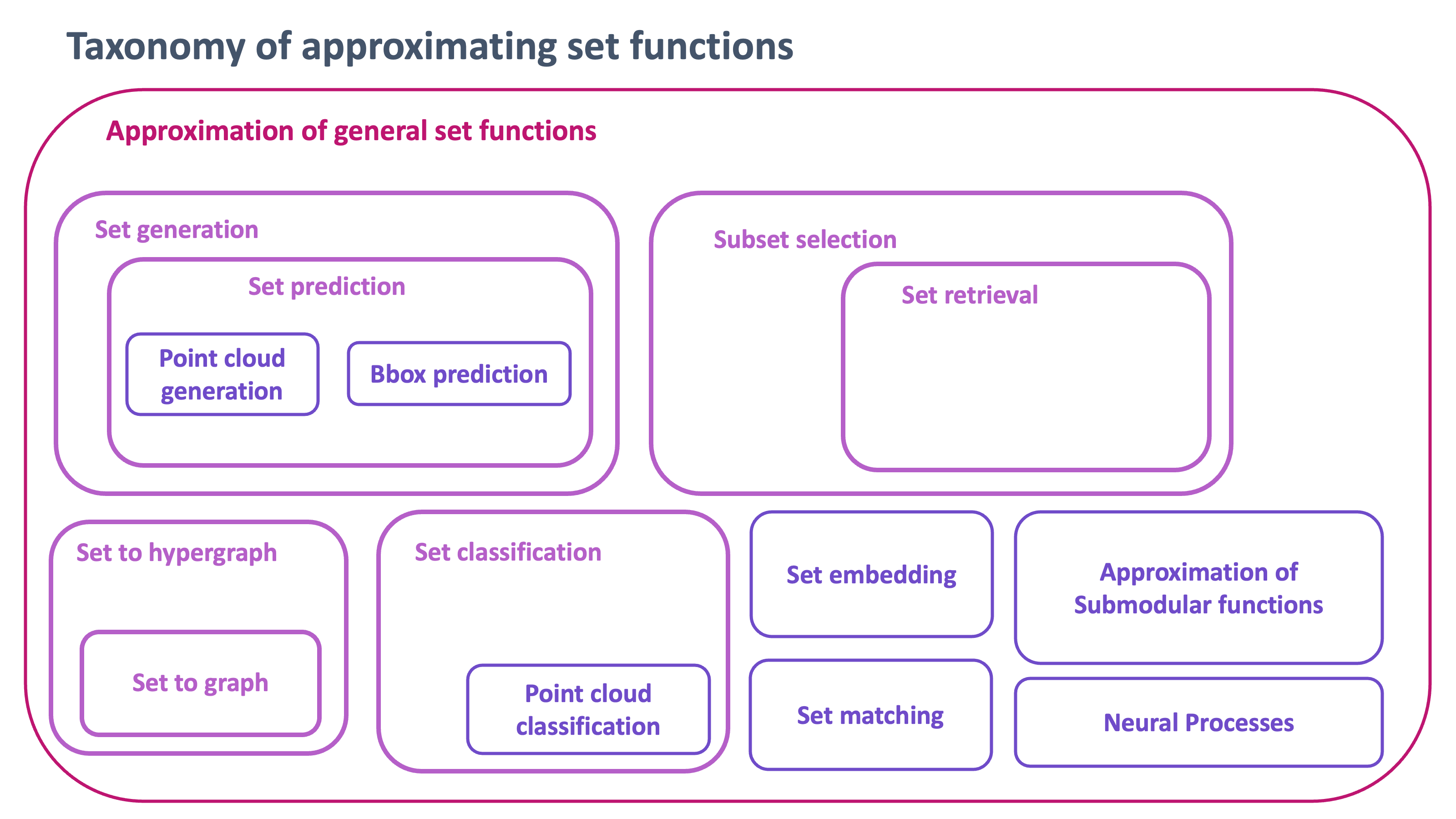
On permutation-invariant neural networks
Masanari Kimura, Ryotaro Shimizu, Yuki Hirakawa, Ryosuke Goto, Yuki Saito
0
0
Conventional machine learning algorithms have traditionally been designed under the assumption that input data follows a vector-based format, with an emphasis on vector-centric paradigms. However, as the demand for tasks involving set-based inputs has grown, there has been a paradigm shift in the research community towards addressing these challenges. In recent years, the emergence of neural network architectures such as Deep Sets and Transformers has presented a significant advancement in the treatment of set-based data. These architectures are specifically engineered to naturally accommodate sets as input, enabling more effective representation and processing of set structures. Consequently, there has been a surge of research endeavors dedicated to exploring and harnessing the capabilities of these architectures for various tasks involving the approximation of set functions. This comprehensive survey aims to provide an overview of the diverse problem settings and ongoing research efforts pertaining to neural networks that approximate set functions. By delving into the intricacies of these approaches and elucidating the associated challenges, the survey aims to equip readers with a comprehensive understanding of the field. Through this comprehensive perspective, we hope that researchers can gain valuable insights into the potential applications, inherent limitations, and future directions of set-based neural networks. Indeed, from this survey we gain two insights: i) Deep Sets and its variants can be generalized by differences in the aggregation function, and ii) the behavior of Deep Sets is sensitive to the choice of the aggregation function. From these observations, we show that Deep Sets, one of the well-known permutation-invariant neural networks, can be generalized in the sense of a quasi-arithmetic mean.
4/1/2024
🎲
Sample Complexity Bounds for Estimating Probability Divergences under Invariances
Behrooz Tahmasebi, Stefanie Jegelka
0
0
Group-invariant probability distributions appear in many data-generative models in machine learning, such as graphs, point clouds, and images. In practice, one often needs to estimate divergences between such distributions. In this work, we study how the inherent invariances, with respect to any smooth action of a Lie group on a manifold, improve sample complexity when estimating the 1-Wasserstein distance, the Sobolev Integral Probability Metrics (Sobolev IPMs), the Maximum Mean Discrepancy (MMD), and also the complexity of the density estimation problem (in the $L^2$ and $L^infty$ distance). Our results indicate a two-fold gain: (1) reducing the sample complexity by a multiplicative factor corresponding to the group size (for finite groups) or the normalized volume of the quotient space (for groups of positive dimension); (2) improving the exponent in the convergence rate (for groups of positive dimension). These results are completely new for groups of positive dimension and extend recent bounds for finite group actions.
6/7/2024