Personalized federated learning based on feature fusion
2406.16583
0
0

Abstract
Federated learning enables distributed clients to collaborate on training while storing their data locally to protect client privacy. However, due to the heterogeneity of data, models, and devices, the final global model may need to perform better for tasks on each client. Communication bottlenecks, data heterogeneity, and model heterogeneity have been common challenges in federated learning. In this work, we considered a label distribution skew problem, a type of data heterogeneity easily overlooked. In the context of classification, we propose a personalized federated learning approach called pFedPM. In our process, we replace traditional gradient uploading with feature uploading, which helps reduce communication costs and allows for heterogeneous client models. These feature representations play a role in preserving privacy to some extent. We use a hyperparameter $a$ to mix local and global features, which enables us to control the degree of personalization. We also introduced a relation network as an additional decision layer, which provides a non-linear learnable classifier to predict labels. Experimental results show that, with an appropriate setting of $a$, our scheme outperforms several recent FL methods on MNIST, FEMNIST, and CRIFAR10 datasets and achieves fewer communications.
Create account to get full access
Overview
- This paper proposes a personalized federated learning (PFL) method based on feature fusion to address the challenge of label distribution skew in federated learning.
- The method aims to improve model performance by fusing personalized features learned at the client-level with shared features learned at the server-level.
- The authors conduct experiments on several benchmark datasets to evaluate the effectiveness of their approach compared to other PFL methods.
Plain English Explanation
In traditional federated learning, a central server tries to train a single model by aggregating updates from many clients (e.g., mobile devices) without accessing their private data. However, one issue that can arise is that the data on each client may have a different distribution of labels, leading to poor performance when the central model is applied to individual clients.
To address this, the researchers in this paper developed a new personalized federated learning technique that allows the central model to adapt to each client's unique data distribution. The key idea is to fuse two types of features: 1) shared features learned at the server-level, which capture general patterns in the data, and 2) personalized features learned at the client-level, which capture the unique characteristics of each client's data.
By combining these two feature sets, the model is able to perform well not only on the overall dataset, but also on the specific data distributions of individual clients. The authors show through experiments on standard machine learning benchmarks that their personalized federated learning approach outperforms other state-of-the-art personalized federated learning methods, such as decentralized personalized federated learning, personalized federated learning via stacking, FedP3: Federated Personalized Privacy-Friendly Network Pruning, and multi-level personalized federated learning for heterogeneous and long-tailed data.
Technical Explanation
The key innovation of this paper is the personalized feature fusion (PFF) approach, which learns both shared and personalized features to improve performance on individual client data distributions.
At a high level, the process works as follows:
- The central server trains a shared feature extractor network on the aggregated data from all clients.
- Each client then trains a personalized feature extractor network on their local data.
- The client's personalized features are fused with the server's shared features to produce a final personalized prediction model.
The authors show that this feature fusion approach outperforms prior PFL methods that either relied solely on shared features or required complex architectural changes or privacy-invasive techniques.
Experimentally, the authors evaluate their PFF approach on several benchmark datasets, including CIFAR-10, FEMNIST, and Shakespeare. They compare against several strong PFL baselines and demonstrate significant improvements in both overall accuracy and personalized performance on individual clients.
Critical Analysis
One potential limitation of the PFF approach is that it requires each client to train a separate personalized feature extractor network, which adds computational overhead and may not be feasible for resource-constrained devices. The authors acknowledge this tradeoff and suggest exploring more efficient personalization techniques as future work.
Additionally, the paper does not provide a deep analysis of the types of data distributions or label skew patterns where the PFF approach is most effective. Further research could investigate the sensitivity of the method to different data heterogeneity scenarios.
Overall, the PFF method represents an interesting and promising direction for improving personalized performance in federated learning. By explicitly modeling both shared and personalized features, it addresses a key challenge in this domain and demonstrates strong empirical results. However, there are still opportunities to refine the approach and investigate its broader applicability.
Conclusion
This paper introduces a novel personalized federated learning technique based on feature fusion, which aims to improve model performance on individual client data distributions by combining shared and personalized feature representations.
The authors show through extensive experiments that their approach outperforms several state-of-the-art PFL methods, highlighting the benefits of explicitly modeling both global and local feature patterns. While the method has some practical limitations, it represents an important step forward in addressing the label distribution skew problem in federated learning and could inspire further advancements in this active research area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
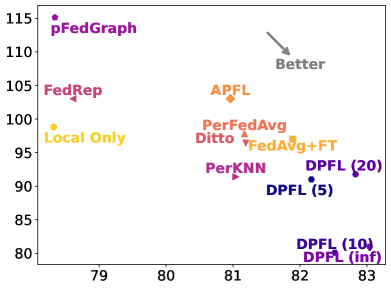
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024
✨
pFedAFM: Adaptive Feature Mixture for Batch-Level Personalization in Heterogeneous Federated Learning
Liping Yi, Han Yu, Chao Ren, Heng Zhang, Gang Wang, Xiaoguang Liu, Xiaoxiao Li
0
0
Model-heterogeneous personalized federated learning (MHPFL) enables FL clients to train structurally different personalized models on non-independent and identically distributed (non-IID) local data. Existing MHPFL methods focus on achieving client-level personalization, but cannot address batch-level data heterogeneity. To bridge this important gap, we propose a model-heterogeneous personalized Federated learning approach with Adaptive Feature Mixture (pFedAFM) for supervised learning tasks. It consists of three novel designs: 1) A sharing global homogeneous small feature extractor is assigned alongside each client's local heterogeneous model (consisting of a heterogeneous feature extractor and a prediction header) to facilitate cross-client knowledge fusion. The two feature extractors share the local heterogeneous model's prediction header containing rich personalized prediction knowledge to retain personalized prediction capabilities. 2) An iterative training strategy is designed to alternately train the global homogeneous small feature extractor and the local heterogeneous large model for effective global-local knowledge exchange. 3) A trainable weight vector is designed to dynamically mix the features extracted by both feature extractors to adapt to batch-level data heterogeneity. Theoretical analysis proves that pFedAFM can converge over time. Extensive experiments on 2 benchmark datasets demonstrate that it significantly outperforms 7 state-of-the-art MHPFL methods, achieving up to 7.93% accuracy improvement while incurring low communication and computation costs.
4/30/2024

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024

FedP3: Federated Personalized and Privacy-friendly Network Pruning under Model Heterogeneity
Kai Yi, Nidham Gazagnadou, Peter Richt'arik, Lingjuan Lyu
0
0
The interest in federated learning has surged in recent research due to its unique ability to train a global model using privacy-secured information held locally on each client. This paper pays particular attention to the issue of client-side model heterogeneity, a pervasive challenge in the practical implementation of FL that escalates its complexity. Assuming a scenario where each client possesses varied memory storage, processing capabilities and network bandwidth - a phenomenon referred to as system heterogeneity - there is a pressing need to customize a unique model for each client. In response to this, we present an effective and adaptable federated framework FedP3, representing Federated Personalized and Privacy-friendly network Pruning, tailored for model heterogeneity scenarios. Our proposed methodology can incorporate and adapt well-established techniques to its specific instances. We offer a theoretical interpretation of FedP3 and its locally differential-private variant, DP-FedP3, and theoretically validate their efficiencies.
4/16/2024