Personalized Federated Learning Techniques: Empirical Analysis

0
📶
Sign in to get full access
Overview
- Personalized Federated Learning (pFL) is a promising approach to tailoring machine learning models to individual users while protecting their data privacy.
- Achieving optimal performance in pFL requires balancing memory overhead costs and model accuracy.
- This paper explores the trade-offs in pFL, providing insights for selecting the right algorithms for real-world scenarios.
Plain English Explanation
Personalized Federated Learning (pFL) is a technique that allows machine learning models to be customized for individual users while keeping their personal data private. This is important because it means people can benefit from personalized AI without having to share their sensitive information.
However, making pFL work well can be challenging. There's a tradeoff between the memory and computing resources used by the model, and how accurate the model is. This paper looks at this tradeoff in depth, evaluating ten different pFL techniques across various datasets and scenarios.
The key finding is that pFL methods that use personalized (local) data aggregation tend to be the most efficient, converging faster than other approaches. This is because they are more efficient in terms of communication and computation.
On the other hand, fine-tuning methods struggle with handling differences in user data, and can also be vulnerable to adversarial attacks. Multi-objective learning methods achieve higher accuracy, but require more training time and resources.
Overall, the study emphasizes the critical role of communication efficiency in scaling up pFL systems. This can have a big impact on the real-world usability and resource requirements of these personalized AI models.
Technical Explanation
The paper empirically evaluates ten prominent pFL techniques across diverse datasets and data splits. The goal is to uncover the key trade-offs and insights for selecting the right pFL algorithms for various real-world scenarios.
The experiments reveal that pFL methods leveraging personalized (local) aggregation exhibit the fastest convergence. This is due to their efficiency in communication and computation, which is a crucial factor for scaling pFL in practice.
In contrast, fine-tuning methods face challenges in handling data heterogeneity and potential adversarial attacks. Multi-objective learning approaches achieve higher accuracy, but at the cost of additional training time and resource consumption.
The study underscores the pivotal role of communication efficiency in pFL. Optimizing this aspect can significantly impact the resource usage in real-world deployments, making pFL more viable for large-scale applications.
Critical Analysis
The paper provides a comprehensive empirical analysis of pFL techniques, offering valuable insights for practitioners. However, it does not delve into the potential limitations or caveats of the research.
For instance, the study focuses on a limited set of datasets and scenarios. Expanding the evaluation to a wider range of applications, including real-world use cases, could further validate the findings and uncover additional trade-offs.
Moreover, the paper does not discuss the implications of its results for the broader field of federated learning. Exploring how the insights from this study can inform the design of more efficient and robust federated learning systems would be a valuable next step.
Additionally, the paper could have addressed potential privacy and security concerns related to pFL, such as the risk of model inversion attacks or the impact of data drift on personalized models.
Conclusion
This paper offers a comprehensive empirical analysis of Personalized Federated Learning (pFL) techniques, shedding light on the critical trade-offs between memory overhead, model accuracy, and communication efficiency.
The key finding is that pFL methods leveraging personalized (local) aggregation exhibit the fastest convergence, highlighting the importance of communication efficiency for scaling pFL in real-world deployments. This insight can guide practitioners in selecting the appropriate pFL algorithms for their specific use cases, ultimately enabling more widespread adoption of personalized AI models that preserve user privacy.
While the paper provides valuable insights, further research is needed to explore the implications for broader federated learning systems and address potential privacy and security concerns. By continuing to advance the state of pFL, researchers can unlock the full potential of this promising approach to personalized and privacy-preserving machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Personalized Federated Learning Techniques: Empirical Analysis
Azal Ahmad Khan, Ahmad Faraz Khan, Haider Ali, Ali Anwar
Personalized Federated Learning (pFL) holds immense promise for tailoring machine learning models to individual users while preserving data privacy. However, achieving optimal performance in pFL often requires a careful balancing act between memory overhead costs and model accuracy. This paper delves into the trade-offs inherent in pFL, offering valuable insights for selecting the right algorithms for diverse real-world scenarios. We empirically evaluate ten prominent pFL techniques across various datasets and data splits, uncovering significant differences in their performance. Our study reveals interesting insights into how pFL methods that utilize personalized (local) aggregation exhibit the fastest convergence due to their efficiency in communication and computation. Conversely, fine-tuning methods face limitations in handling data heterogeneity and potential adversarial attacks while multi-objective learning methods achieve higher accuracy at the cost of additional training and resource consumption. Our study emphasizes the critical role of communication efficiency in scaling pFL, demonstrating how it can significantly affect resource usage in real-world deployments.
Read more9/12/2024

0
Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
Read more4/23/2024
📈
0
Personalized Multi-tier Federated Learning
Sourasekhar Banerjee, Ali Dadras, Alp Yurtsever, Monowar Bhuyan
The key challenge of personalized federated learning (PerFL) is to capture the statistical heterogeneity properties of data with inexpensive communications and gain customized performance for participating devices. To address these, we introduced personalized federated learning in multi-tier architecture (PerMFL) to obtain optimized and personalized local models when there are known team structures across devices. We provide theoretical guarantees of PerMFL, which offers linear convergence rates for smooth strongly convex problems and sub-linear convergence rates for smooth non-convex problems. We conduct numerical experiments demonstrating the robust empirical performance of PerMFL, outperforming the state-of-the-art in multiple personalized federated learning tasks.
Read more7/22/2024
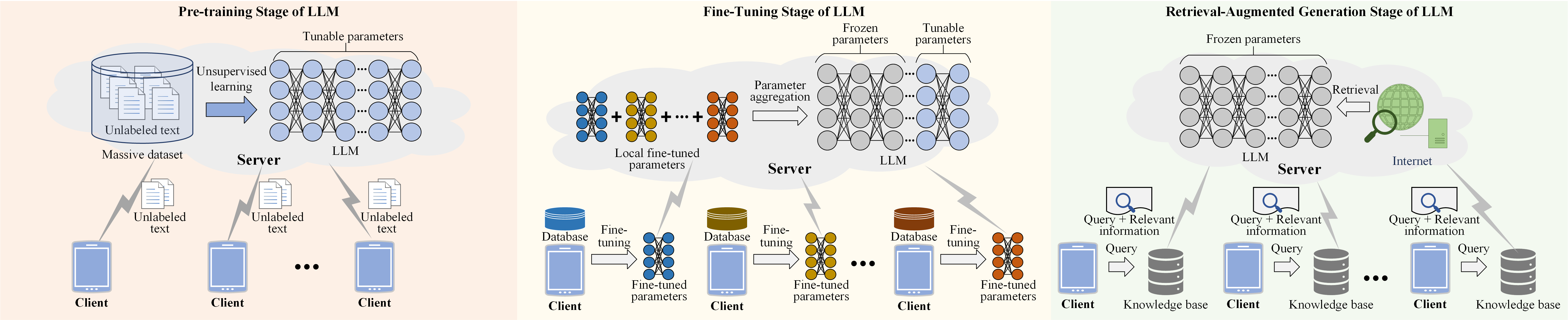
0
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
Read more4/23/2024