PETSc/TAO Developments for Early Exascale Systems

0

Sign in to get full access
Overview
- The paper discusses the development of the PETSc (Portable, Extensible Toolkit for Scientific Computation) and TAO (Toolkit for Advanced Optimization) libraries to address the challenges of programming for early exascale systems.
- It focuses on GPU programming challenges and PETSc's responses, including new features and optimizations to support GPU-accelerated computations.
- The paper also covers PETSc's efforts to enable mixed-precision computing and provide tools for legacy code modernization.
Plain English Explanation
PETSc and TAO are software libraries that scientists and engineers use to solve complex computational problems, such as modeling physical systems or optimizing designs. As computers become more powerful and use specialized hardware like graphics processing units (GPUs), these libraries need to evolve to take advantage of the new capabilities.
The paper explains how the PETSc and TAO teams have been working to address the challenges of programming for early exascale systems, which are the next generation of super-fast computers. One of the key challenges is using GPUs effectively, as their architecture is quite different from the traditional central processing units (CPUs) that have been the workhorses of scientific computing.
The PETSc team has developed new features and optimizations to make it easier for researchers and engineers to harness the power of GPUs in their simulations and optimization problems. This includes making it simpler to move data between the CPU and GPU, and allowing certain computations to be performed directly on the GPU.
The paper also discusses PETSc's efforts to enable "mixed-precision" computing, where some calculations are performed with lower-precision numbers to save time and memory, while still maintaining the overall accuracy of the results. This can be particularly helpful on exascale systems, where managing the massive amounts of data and computations is a significant challenge.
Finally, the paper touches on PETSc's work to provide tools that can help modernize legacy code, which is software that was written a long time ago and may not be optimized for the latest hardware. By making it easier to adapt this existing code, the PETSc team aims to help researchers and engineers leverage their valuable past work on the new exascale systems.
Technical Explanation
The paper outlines the development of the PETSc and TAO libraries to address the challenges of programming for early exascale systems, which are the next generation of super-fast computers. It focuses on three key areas:
-
GPU programming challenges and PETSc's responses: The paper describes how PETSc has introduced new features and optimizations to support GPU-accelerated computations. This includes improvements to data movement between the CPU and GPU, as well as the ability to perform certain computations directly on the GPU.
-
Enabling mixed-precision computing: The paper discusses PETSc's efforts to enable the use of lower-precision data types for some calculations, while still maintaining the overall accuracy of the results. This can help manage the massive amounts of data and computations on exascale systems.
-
Tools for legacy code modernization: The paper covers PETSc's work to provide tools that can help researchers and engineers adapt their existing, legacy code to run efficiently on the new exascale hardware. This allows them to leverage their valuable past work on the latest systems.
The paper presents experimental results and performance benchmarks to demonstrate the improvements and capabilities of the PETSc and TAO libraries in the context of early exascale systems. It also discusses the ongoing challenges and future directions for the development of these tools.
Critical Analysis
The paper provides a thorough overview of the PETSc and TAO developments for early exascale systems, and the authors have clearly put significant effort into addressing the key challenges. The focus on GPU programming, mixed-precision computing, and legacy code modernization are all important and timely topics as the research community prepares for the arrival of exascale-class supercomputers.
One potential limitation of the research is the scope of the paper, which is primarily focused on the PETSc and TAO libraries. While these are important tools, the challenges of exascale computing are broader and involve the entire software ecosystem. It would be valuable to see how the PETSc and TAO developments fit into the larger context of exascale software and hardware challenges.
Additionally, the paper does not delve deeply into the specific algorithms, data structures, or optimization techniques used in the PETSc and TAO implementations. A more technical discussion of these lower-level aspects could provide additional insights for researchers and developers looking to build upon this work.
Overall, the paper provides a solid overview of the PETSc and TAO developments and their relevance to early exascale systems. Readers interested in the broader challenges of exascale computing or the detailed technical implementation of the libraries may want to seek out additional resources to complement the information presented here.
Conclusion
The PETSc and TAO developments discussed in this paper represent an important step forward in preparing scientific computing software for the arrival of early exascale systems. By focusing on GPU programming, mixed-precision computing, and legacy code modernization, the PETSc and TAO teams are helping to ensure that researchers and engineers can effectively leverage the immense computational power of these next-generation supercomputers.
As exascale systems become a reality, the continued evolution of tools like PETSc and TAO will be crucial for advancing scientific discovery and engineering innovation across a wide range of domains. The insights and techniques presented in this paper can serve as a foundation for further research and development in this critical area of high-performance computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PETSc/TAO Developments for Early Exascale Systems
Richard Tran Mills, Mark Adams, Satish Balay, Jed Brown, Jacob Faibussowitsch, Toby Isaac, Matthew Knepley, Todd Munson, Hansol Suh, Stefano Zampini, Hong Zhang, Junchao Zhang
The Portable Extensible Toolkit for Scientific Computation (PETSc) library provides scalable solvers for nonlinear time-dependent differential and algebraic equations and for numerical optimization via the Toolkit for Advanced Optimization (TAO). PETSc is used in dozens of scientific fields and is an important building block for many simulation codes. During the U.S. Department of Energy's Exascale Computing Project, the PETSc team has made substantial efforts to enable efficient utilization of the massive fine-grain parallelism present within exascale compute nodes and to enable performance portability across exascale architectures. We recap some of the challenges that designers of numerical libraries face in such an endeavor, and then discuss the many developments we have made, which include the addition of new GPU backends, features supporting efficient on-device matrix assembly, better support for asynchronicity and GPU kernel concurrency, and new communication infrastructure. We evaluate the performance of these developments on some pre-exascale systems as well the early exascale systems Frontier and Aurora, using compute kernel, communication layer, solver, and mini-application benchmark studies, and then close with a few observations drawn from our experiences on the tension between portable performance and other goals of numerical libraries.
Read more6/14/2024
🛠️
0
Web-based Visualization and Analytics of Petascale data: Equity as a Tide that Lifts All Boats
Aashish Panta, Xuan Huang, Nina McCurdy, David Ellsworth, Amy Gooch, Giorgio Scorzelli, Hector Torres, Patrice Klein, Gustavo Ovando-Montejo, Valerio Pascucci
Scientists generate petabytes of data daily to help uncover environmental trends or behaviors that are hard to predict. For example, understanding climate simulations based on the long-term average of temperature, precipitation, and other environmental variables is essential to predicting and establishing root causes of future undesirable scenarios and assessing possible mitigation strategies. While supercomputer centers provide a powerful infrastructure for generating petabytes of simulation output, accessing and analyzing these datasets interactively remains challenging on multiple fronts. This paper presents an approach to managing, visualizing, and analyzing petabytes of data within a browser on equipment ranging from the top NASA supercomputer to commodity hardware like a laptop. Our novel data fabric abstraction layer allows user-friendly querying of scientific information while hiding the complexities of dealing with file systems or cloud services. We also optimize network utilization while streaming from petascale repositories through state-of-the-art progressive compression algorithms. Based on this abstraction, we provide customizable dashboards that can be accessed from any device with any internet connection, enabling interactive visual analysis of vast amounts of data to a wide range of users - from top scientists with access to leadership-class computing environments to undergraduate students of disadvantaged backgrounds from minority-serving institutions. We focus on NASA's use of petascale climate datasets as an example of particular societal impact and, therefore, a case where achieving equity in science participation is critical. We further validate our approach by deploying the dashboards and simplified training materials in the classroom at a minority-serving institution.
Read more8/23/2024
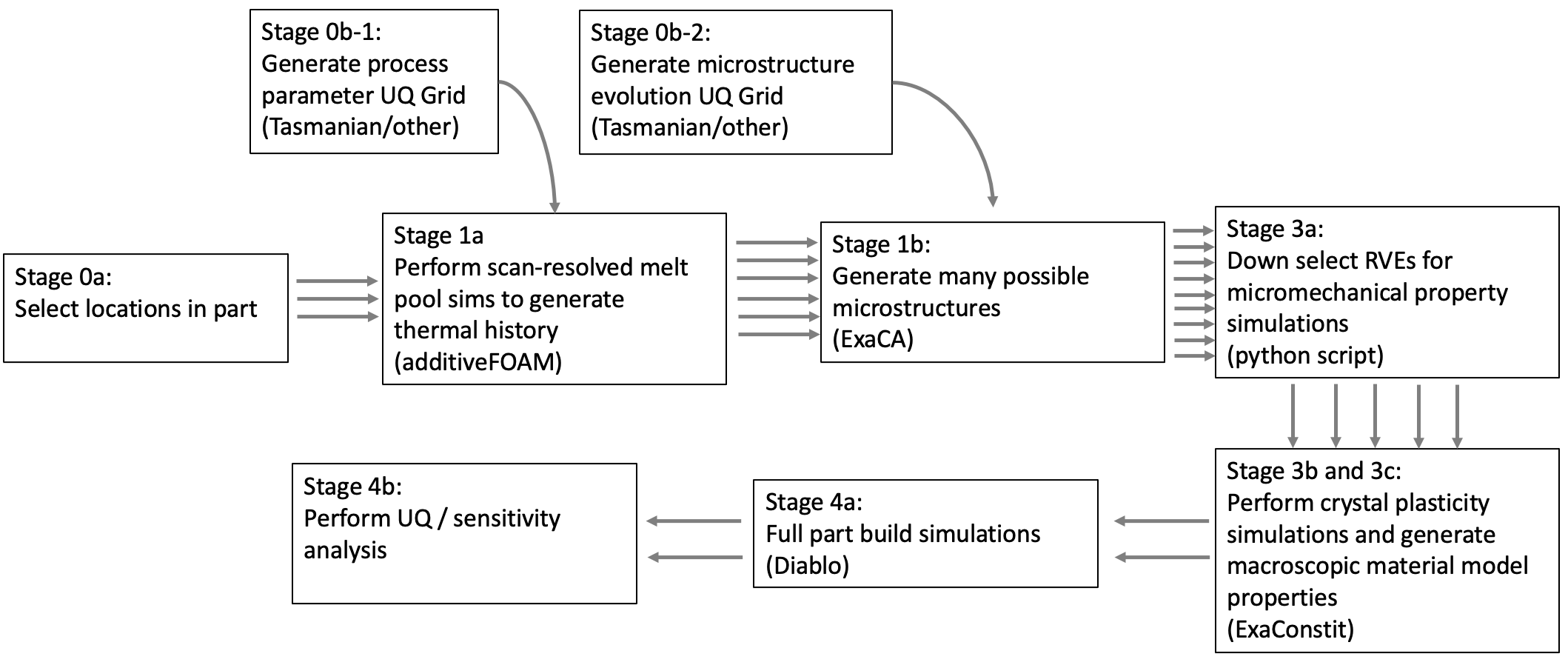
0
Scaling on Frontier: Uncertainty Quantification Workflow Applications using ExaWorks to Enable Full System Utilization
Mikhail Titov, Robert Carson, Matthew Rolchigo, John Coleman, James Belak, Matthew Bement, Daniel Laney, Matteo Turilli, Shantenu Jha
When running at scale, modern scientific workflows require middleware to handle allocated resources, distribute computing payloads and guarantee a resilient execution. While individual steps might not require sophisticated control methods, bringing them together as a whole workflow requires advanced management mechanisms. In this work, we used RADICAL-EnTK (Ensemble Toolkit) - one of the SDK components of the ECP ExaWorks project - to implement and execute the novel Exascale Additive Manufacturing (ExaAM) workflows on up to 8000 compute nodes of the Frontier supercomputer at the Oak Ridge Leadership Computing Facility. EnTK allowed us to address challenges such as varying resource requirements (e.g., heterogeneity, size, and runtime), different execution environment per workflow, and fault tolerance. And a native portability feature of the developed EnTK applications allowed us to adjust these applications for Frontier runs promptly, while ensuring an expected level of resource utilization (up to 90%).
Read more7/2/2024

0
ExaWorks Software Development Kit: A Robust and Scalable Collection of Interoperable Workflow Technologies
Matteo Turilli, Mihael Hategan-Marandiuc, Mikhail Titov, Ketan Maheshwari, Aymen Alsaadi, Andre Merzky, Ramon Arambula, Mikhail Zakharchanka, Matt Cowan, Justin M. Wozniak, Andreas Wilke, Ozgur Ozan Kilic, Kyle Chard, Rafael Ferreira da Silva, Shantenu Jha, Daniel Laney
Scientific discovery increasingly requires executing heterogeneous scientific workflows on high-performance computing (HPC) platforms. Heterogeneous workflows contain different types of tasks (e.g., simulation, analysis, and learning) that need to be mapped, scheduled, and launched on different computing. That requires a software stack that enables users to code their workflows and automate resource management and workflow execution. Currently, there are many workflow technologies with diverse levels of robustness and capabilities, and users face difficult choices of software that can effectively and efficiently support their use cases on HPC machines, especially when considering the latest exascale platforms. We contributed to addressing this issue by developing the ExaWorks Software Development Kit (SDK). The SDK is a curated collection of workflow technologies engineered following current best practices and specifically designed to work on HPC platforms. We present our experience with (1) curating those technologies, (2) integrating them to provide users with new capabilities, (3) developing a continuous integration platform to test the SDK on DOE HPC platforms, (4) designing a dashboard to publish the results of those tests, and (5) devising an innovative documentation platform to help users to use those technologies. Our experience details the requirements and the best practices needed to curate workflow technologies, and it also serves as a blueprint for the capabilities and services that DOE will have to offer to support a variety of scientific heterogeneous workflows on the newly available exascale HPC platforms.
Read more7/24/2024